







How Go + Neo4j Enabled the Financial Times to Deliver at Speed

Senior Metadata DevOps, Financial Times
9 min read

Editor’s Note: This presentation was given by Dan Murphy from the Financial Times at GraphConnect Europe in April 2016. Here’s a quick recap of what he covered:
–
What we’re going to talk about today is how the Financial Times threw away an old technology that wasn’t working for us and embraced an entirely new database with Neo4j and Go:
I write code at the Financial Times, and I’m going to give you an overview of one of our projects that was failing. Despite the hard work that had been put into it, the project wasn’t delivering. This was shaping up to be catastrophic, as the project formed a vital aspect of the Financial Times’ digital future.
I’ve worked in IT for a long time, and sometimes there’s a tendency to stick with a project to make it work even if there are no signs pointing to success. But for this project, we took a hard look at what we were trying to achieve as well as the technologies we were using, and made the difficult decision to embrace a drastic change.
Normally when we change in the IT world, we change one thing at a time so that if something goes wrong, we know exactly what happened. We decided to ignore that, and threw away over a year’s worth of work and rewrote it in a different programming language over a period of about three months. This changed the project from one that was failing to one that was working.
The Financial Times: Moving from Print to Digital
For those of you who aren’t familiar with the Financial Times, we’re a newspaper that was launched in London in 1888. In 2010, the company began noticing a change in how consumers were accessing its content.
In 2012 they decided to release a free paywall as well as an HTML5 web app, which in combination resulted in a transition from our primary revenue being based on paper subscriptions to one based on digital subscriptions. Today, we make far more revenue from our digital subscriptions than we do from our paper ones.
With digital subscriptions, more things are possible. Now we have interactive graphics, podcasts and videos that requires us to display our content in a totally different way than we’re used to. Below are some sample pages taken from the current website:
Why are we moving away from this model? It’s a monolith, so we ran into obstacles every time we wanted to add other products on top of it via new APIs. This meant our current website — and the platform that sat underneath it — wasn’t going to work moving forward. And we knew things had to change.
A Failing Semantic Linked Data Platform
About 18 months ago, a band of fearless developers decided to set off on a journey to build a semantic linked data platform in Java. We chose this type of platform because we wanted to provide a really rich experience through the linking of concepts, content, organizations, people and any other type of information you can think of.
This seemed like the right thing to do at the time, so off they went. They headed off towards the peak of semantics and sadly, not everyone made it to the end of the journey. I joined the team last October, and not long after I arrived, it was apparent that the project had reached a decision point because the new semantic platform simply wasn’t delivering.
The main problem we encountered was the amount of time it took to load data into the platform, which was largely the result of our underlying technology. So, when we looked around at what to take with us on this journey, we realized that the equipment we had relied upon to build this platform was in reality slowing us down.
For example, the data modelling was typically done by people associated with the project, but not directly inside the project. Data modelling was also done in OWL — WC3 Web Ontology Language — which is a difficult, specialist art that requires a lot of training and time to use correctly.
But we realized that we weren’t really trying to build a linked data platform. Instead, we needed to find a better way to link our content using the data we already had. It would include taking articles in, processing them, extracting concepts, annotating the articles with the concepts and linking the articles with their related concepts. We weren’t going to be able to do this effectively with a linked data platform; we needed a graph database.
Even though the project we built wasn’t going to work for us, we had already built a solid foundation with our architecture. This included a set of flexible, discrete components called microservices, which are independent units that can be swapped out without affecting other parts of the system.
Turning the Project Around with Neo4j and Graph Technology
To get started, we took ourselves away from the main office and locked ourselves into a room for a week to try out different combinations of technologies. We put our tools on the table, which were RDF store and Java. To start, we changed out our RDF platform to see if that was what was holding us back.
But since we were working with microservices, we decided to explore some additional and more foreign options, which led us to experimenting with Neo4j and Go.
None of us had prior experience with Go or Neo4j but during that week, but we tried writing code in different triple-stores and graph databases to see what worked for us, and in both Neo4j and Go we found our solutions. One of the things we liked about Go was that we had to write way less code than in Java, it was incredibly easy to use, and we were able to get things up and running extremely quickly.
We also had to decide what type of driver we were going to use when writing Java to Neo4j. Should we use a JDBC driver or some other type of library, or use the REST interface directly? We tried both JDBC and REST but found the amount of coding extensive and found some driver limitations as well. We ultimately chose the neoism Go library, which is essentially a driver for talking to Neo4j.
After that week, we spent some time honing our skills, practicing our techniques and putting our proof of concept work into production. Below is a very simple node in our graph:

It represents a company, Apple, that has some applied labels: thing, concept, organization, company, and public company. It also has properties, such as a UUID. But our data inside the graph database isn’t the sole source of information; we also have data coming from other systems, one of which is called TME.
We started putting other identifiers as simple properties in our graph. This was a bit confusing because we ended up polluting the root of the object in the graph, which we had to iterate. And this ability to iterate through our models was one of the things we liked about Neo4j.
The next thing we tried was to group properties under an umbrella called “identifiers,” which we thought would allow us to include in addition to our UUID. And while this seemed like a good idea at the time, it wasn’t.
By grouping these properties in such a way, we weren’t able to effectively make use of indexing and searching. We wanted to be able to concord between the identifiers we knew and the identifiers other systems knew, but you couldn’t do that with everything grouped under one category.
We had been reluctant to add new nodes to our graph, but when we finally did, it solved a lot of problems for us:

While some of the above nodes aren’t “real” entities, adding representations of those concepts as nodes in the graph allowed us to build relationships between them. It also allowed us to apply labels to quickly ask for both LEIs — Legal Entity Identifiers — and TME identifiers.
What’s not shown on this diagram are the additional relationships that exist between Apple and other entities such as subsidiaries, related people or articles, but we are now able to create those types of links.
Below is a representation in Go of two structures, a Thing structure, which is our base representation, and a Brand structure:

The Brand is a composite structure that includes a structure as well as some extra properties, which has a pattern that we use in other places as well. The API URL is how the data is serialized and sent on the wire, which is essentially the public interface that we use for our APIs.
We also had to find an efficient way to export our data from the graph database into a structure that would allow us to send it out. Our solution came in the form of another neoism, or building a driver connection and running a query.
But rather than reading out our nodes, we constructed a structure that maps directly into our Brand structure that we can serialize. This saves us from having to go through a DTO pattern that requires us to copy between two different objects:
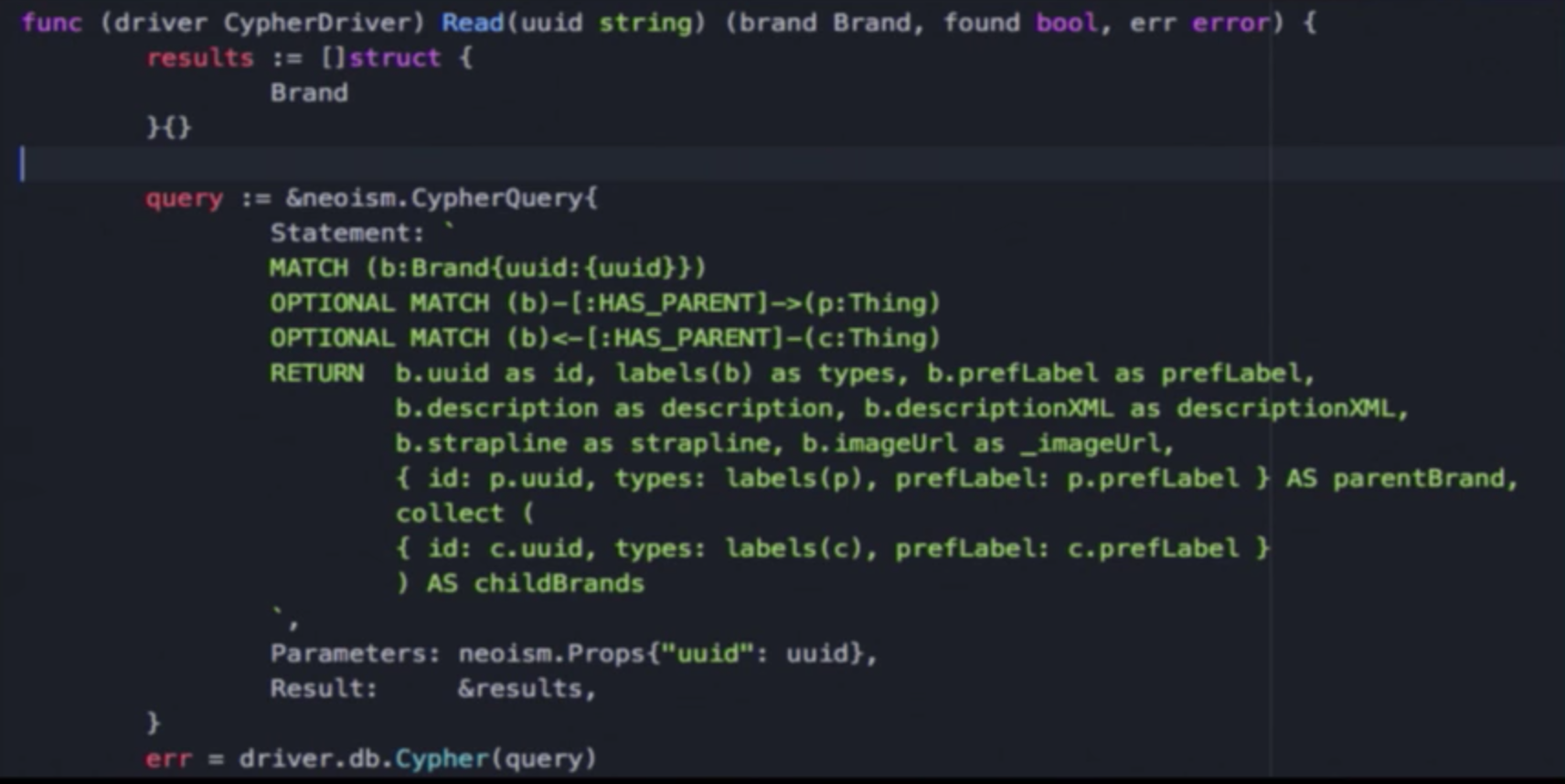
Another aspect to point out is our hierarchy of types, which has a function called labels:

So a public company, other company or organisation gets turned into a ray of strings by this labels function, which we then send out.
With neoism, if we hadn’t done that and gotten back nodes, to retrieve the labels we would have had to make another call to the database. To make it more performant, we saved ourselves three extra calls for each call of the API, which gave us a performant database that requires less code.
But this isn’t to say it was easy. We found a bug in Neo4j — which has been fixed now — that ended up returning duplicate bits of data.
This is a helpful reminder that one of the things that’s challenging about writing any database or data access system is knowing the results you should get back — not just whether or not the database functions. Validating the integrity of your returned data is extremely important.
One of the things we found lacking in the land of Neo4j is date and time support, because everyone seems to write things as either an integer or some kind of long end or build a date tree and then be able to do before and after kind of stuff. Having this as a first-class language would be helpful.
Conclusion
We’ve come a long way over three months. We threw out 12 months of code, rewrote over fifteen microservices, and wrote new APIs and microservices. We’re a small team of about four developers, and we’ve been producing more than one deliverable per week, including resiliently deploying data into the cloud and doing a first deployment to containers.
We unanimously agree that if we hadn’t taken that risk to go to a combination of Neo4j and Go, we’d still be writing code. That combination really worked for us, because we were prepared to take a calculated risk and chuck everything away.
If you’re dealing with a faltering project or are setting out on a venture of your own, I’d like to encourage you to see how radical you can be, how much change you can take. It worked for us, and we feel more empowered and in control of our world now than ever before.
Inspired by Dan’s talk? Click below to register for GraphConnect San Francisco and see even more presentations, talks and workshops from the world’s leading graph technology experts.
Share Article



Explore
Related Articles
New research finds enterprises earn 230% ROI with Neo4j Graph Intelligence Platform
Turning ServiceNow data into connected enterprise intelligence
A knowledge layer for your agentic systems on Google Cloud

The context gap: Why your smart-sounding AI struggles to reason

From data to intelligence: Why every enterprise needs an AI knowledge layer
