“Google” your own brain: Create a CMS with Neo4j & Elasticsearch [Community Post]

UX Developer, Unicon
7 min read
[As community content, this post reflects the views and opinions of the particular author and does not necessarily reflect the official stance of Neo4j.]
Grasp Theory is a project that is exploring a new way to catalogue and recall documents that are personally relevant. This article describes some high-level concepts being used that leverage Neo4j.
The power of the graph
Having a graph to represent connections between content is really powerful. It’s a really hot topic and Google solidified a dynasty off their PageRank algorithm that leverages the links between pages on the web. This helps Google provide us with more relevant content very quickly.
Wait a minute though, “relevant” in the case of using Google doesn’t necessarily mean “personally relevant.” In fact, most times we are searching to find out what everyone else knows and is generally agreed upon as relevant. We are essentially peering into the connections of a brain which is the cumulative average of the world and Google allows us to do this through the colored lenses provided by their proprietary ranking algorithm.
Search engines are a valuable tool for a variety of use cases, however, there could be use cases where we may not want to search everyone else’s brains and instead search our own.
The start of our new brain
Human memory is short and terribly fickle.
–Janine Di Giovanni
Suppose throughout our schooling days we developed a content management system (CMS) and indexed all the information we were exposed to into our CMS. We could then rely on this system to help us recall information that is personally relevant to us without requiring our actual brains to keep sharp representations of all the information we were ever exposed to handy.
If we indexed all that information into something like Elasticsearch we could certainly search for relevant documents via basic text searches. Done!
Isn’t simple text search enough to search our own brains? Simple text-based search wasn’t enough for Google, so let’s explore a few things we can do to improve upon a text-based search in our new brain-based CMS.
It seems that there are a few quick wins we could implement:
- Provide related content to items we find
- Increase the relevancy of the search results
If we tracked the content and all the relationships we made between content in our CMS using Neo4j then #1 is already done. Nice, thanks Neo4j!
How do we address #2, the relevancy problem? Let’s take a page from Google’s playbook.
Enhancing relevancy via Mazerunner
A good memory is one trained to forget the trivial.
–Clifton Fadiman
Our brain does an amazing job letting some things fade away but provides hooks into memories that we have deemed important. We can then jump to related memories via associations we have created through our experiences. It would be annoying, inefficient, and probably dangerous to be able to recall every associated memory that isn’t relevant.
Let’s use this idea as a model and work to enhance the relevancy of searches in our Neo4j CMS.
Fortunately, the Neo4j team took over a project created by Kenny Bastani called Mazerunner. Mazerunner is exactly the tool we need to enhance the relevancy of our search. As described here, Mazerunner integrates an existing Neo4j database with Apache Spark and GraphX to generate graph analytics like PageRank and then puts those values back into your Neo4j database.
NOTE: There is a new Apache Spark connector that is now the preferred way to use Spark with Neo4j. Check it out here.
To generate a PageRank value, you must tell Mazerunner which relationships to use and this will depend on your relationship structure.
See Mazerunner documentation for implementation details here.
Once we have a PageRank value for each piece of content, we could use that to tweak our search results.
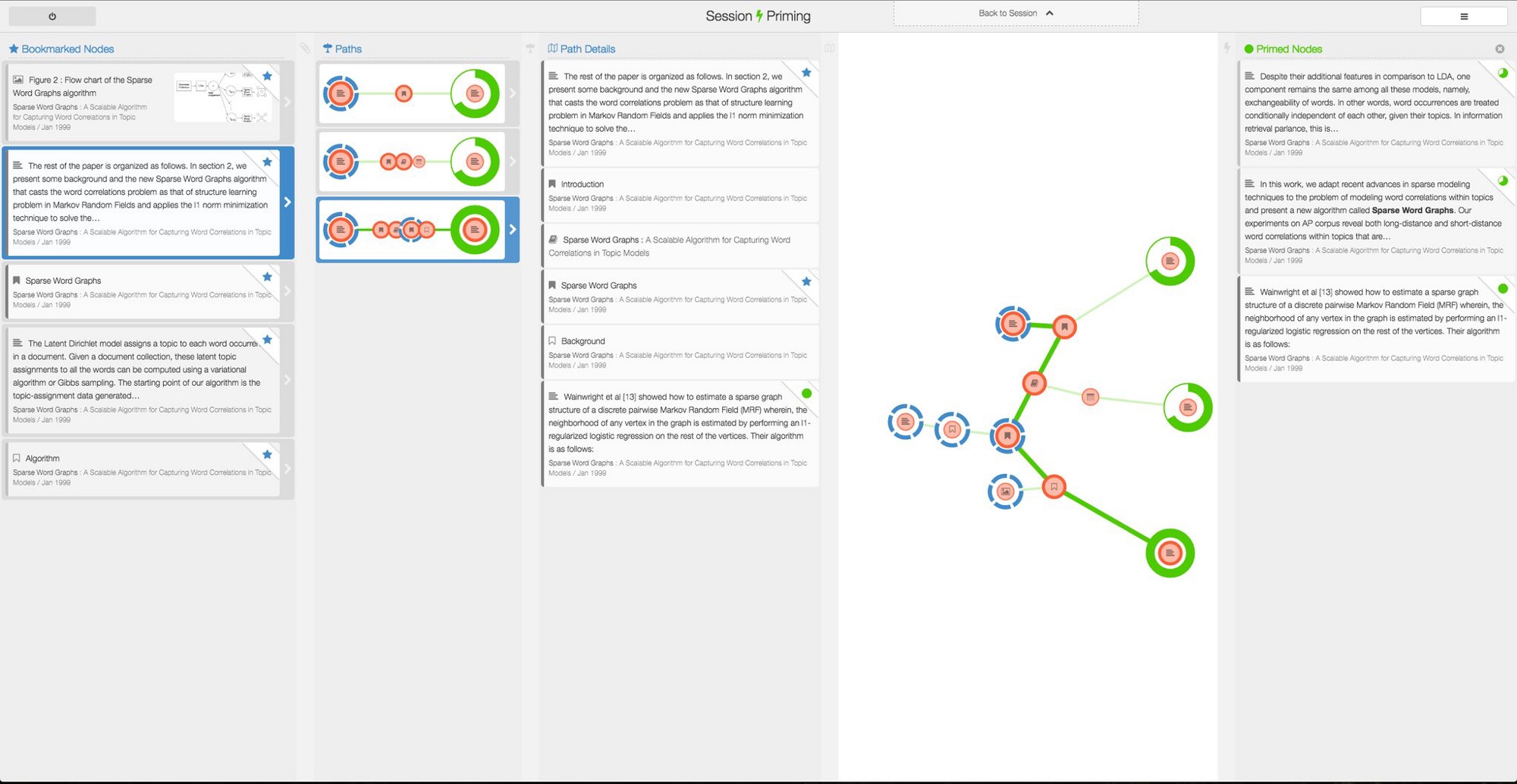
Below is the result of running Mazerunner on a simple tree structure utilizing RELATED relationships between our nodes. Since PageRank essentially gives a weight proportional to the probability of reaching a node from a randomly selected node in the graph, it makes sense that our root node of the tree has a low PageRank, while our values trend upwards as we traverse down the branches.

Simple example of PageRank values added to nodes using Mazerunner
So how do we utilize our new PageRank values? Once Mazerunner finishes adding PageRank values back into the nodes within our Neo4j graph database, it’s time to re-index each node with this new value into Elasticsearch. (See the latest APOC Elasticsearch integration details here as one possible implementation).
We can then tweak our Elasticsearch query to include the PageRank value in our score calculation of matched documents.
query: {
function_score: {
query: {
filtered: {
// omitted for brevity
}
},
boost_mode: "replace",
script_score: {
params: {
prPercent: pageRankPercent
},
// *** MAGIC: Incorporate Neo4j graph pagerank score ***
script: "_score * (1 + _source.pageRank.value * prPercent)"
}
}
}
(See the Elasticsearch documentation for script_score.)
The tricky part here is that Elasticsearch provides an arbitrary score value for your results (description of problem here, documentation here). This score could be greater than one and varies based on each query, so since your weighting is fixed per query, you will need to tweak the weighting to get a “good enough” effect on your query results. This is accomplished above by adding a prPercent weight to the PageRank value.
The results
The impact of integrating PageRank values from Mazerunner and Neo4j into your search results will vary based upon your scoring algorithms/weighting and the underlying graph structure used to calculate the PageRank values.
Check out the screenshot and video below of toggling PageRank weighted searches using the same tree-based data described above. Even though the example below only uses a single tree structure for data and a limited number of relationships, PageRank already provides some small enhancements to search results. Naturally, the more data and more relationships, the more relevancy our PageRank values will give us.
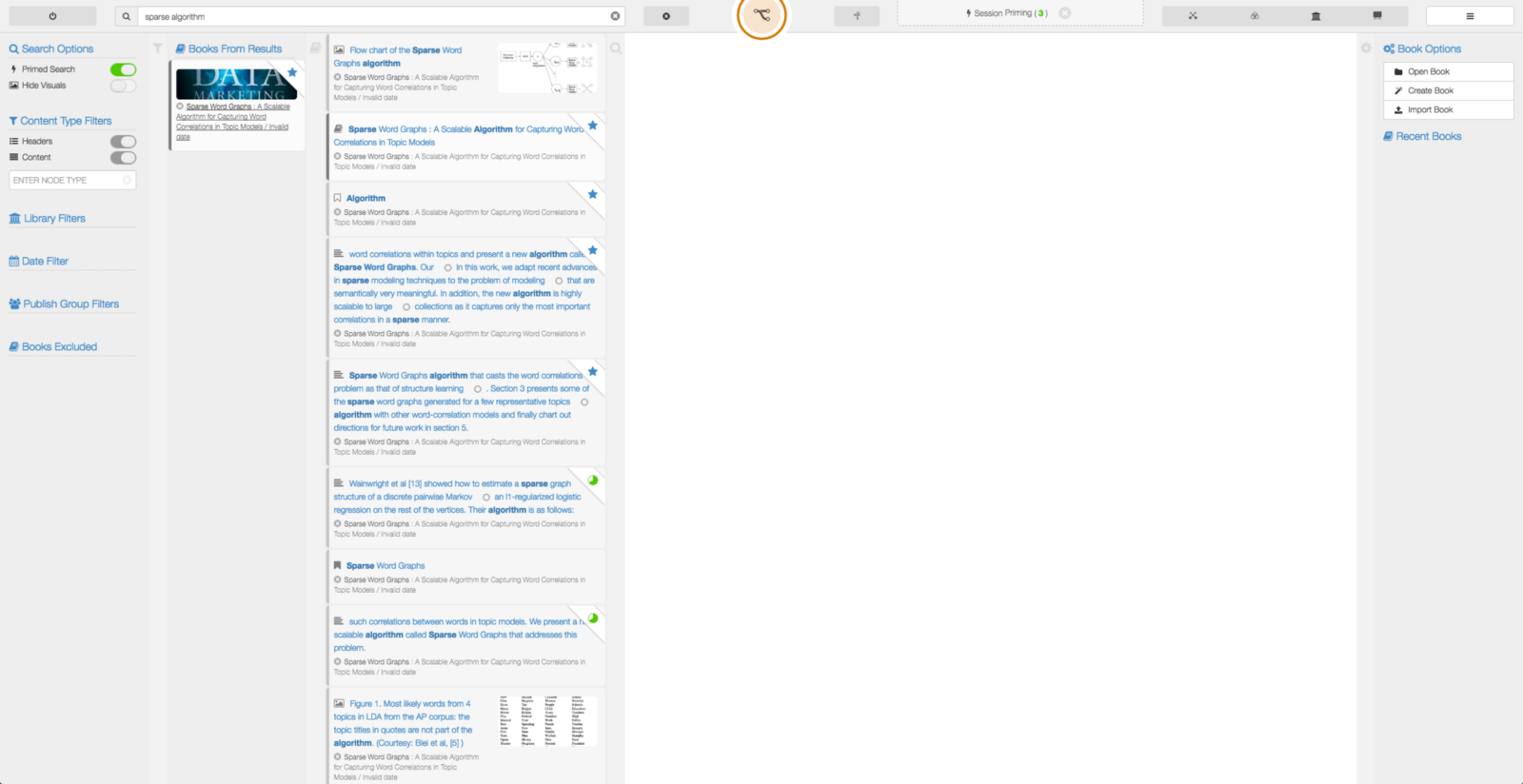
With PageRank values indexed into Elasticsearch, toggling their use during a search is as simple as clicking a button.
What’s next?
The “Grasp Theory” project is working to import more data to fine-tune the generation and use of PageRank values. More data around that is coming soon, but our personal brain search engine is certainly showing some promise and it is exciting to see what else might pop out while leveraging Neo4j as things progress.
Here are some other areas that might be worth exploring to take things a step further:
- With a new release of APOC for Neo4j, streamlining integrations with Elasticsearch will be even better!
- Enhancing our graph with mappings from content nodes to semantics nodes could really help. This could help drive recommendations to relevant content that does not have relationships between them. This is like integrating a research paper from another project into your current project because they have semantic similarities.
- We could also look at the other graph analytics algorithms that Mazerunner provides. Perhaps calculating measures of betweenness centrality could provide some interesting insights?
- Add configurable relevancy via “priming”. Right now we have added PageRank to provide the global importance of content. We are essentially asking a question to our brains while our brains is in the same exact state during every query. What would happen if we “primed” our brains the way our brains are primed right now by reading this article?
If we searched right now for “graphs,” we would likely get graph theory or Neo4j-related results. If we searched “graphs” just before reading this article, it could be likely we get different results like those related to Euclidean coordinates. “Priming” is indeed very possible with our setup, so perhaps we’ll explore this in a future post.
Click below to get your free copy of the Learning Neo4j ebook and catch up to speed with the world’s leading graph database.
Share Article



Explore
Related Articles

Connected Intelligence: Operationalizing Production-Grade Graph Solutions Across Enterprise Networks

A workbench for teams to query, explore, and visualize graph data

1 of 3: The difference between a graph, a knowledge graph, and a context graph

2 of 3: Why graphs, knowledge graphs, and context graphs matter to customers

3 of 3: The graph ecosystem: Bringing connected context to enterprise AI
