Graph algorithms in Neo4j: Graph algorithms in practice


9 min read

Graph analytics have value only if you have the skills to use them and if they can quickly deliver the insights you need. This blog provides a hands-on example using Neo4j on data from Yelp’s Annual Dataset challenge.
Graph algorithms are easy to use, fast to execute and produce powerful results. This blog series is designed to help you better utilize graph analytics and graph algorithms so you can effectively innovate and develop intelligent solutions faster using a graph database like.
Last week we completed our looked at Community Detection algorithms, with a focus on the Triangle Count and Average Clustering Coefficient algorithm.

This week we conclude our series with an overview of graph algorithms in practice, where we will learn how to apply graph algorithms in data-intensive applications.
About graph algorithms in practice
Yelp.com has been running the Yelp Dataset challenge since 2013, a competition that encourages people to explore and research Yelp’s open dataset. As of Round 10 of the challenge, the dataset contained:
- Almost 5 million reviews
- Over 1.1 million users
- Over 150,000 businesses
- 12 metropolitan areas
Since its launch, the dataset has become popular, with hundreds of academic papers written about it. It has well-structured and highly interconnected data and is therefore a realistic dataset with which to showcase Neo4j and graph algorithms.
Graph model
The Yelp data is represented in a graph model as shown in the diagram below.
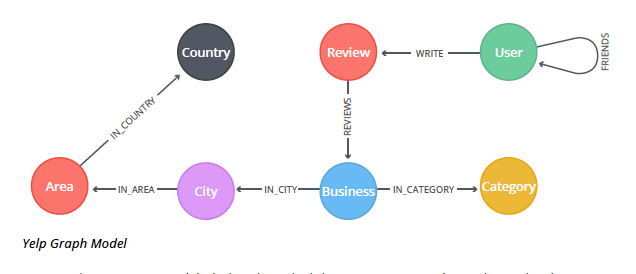
Our graph contains User labeled nodes, which have a FRIENDS relationship with other Users. Users also WRITE Reviews and tips about Businesses. All of the metadata is stored as properties of nodes, except for Categories of the Businesses, which are represented by separate nodes.
Data import
There are many different methods for importing data into Neo4j, including the import tool, LOAD CSV command and Neo4j Drivers.
For the Yelp dataset, we need to do a one-off import of a large amount of data so the import tool is the best choice. See the yelp-graph-algorithms GitHub repository for more details.
Exploratory data analysis
Once we have the data loaded in Neo4j, we execute some exploratory queries to get a feel for it. We will be using the
Awesome Procedures on Cypher (APOC) library in this section. Please see
Installing APOC for details if you would like to follow along.
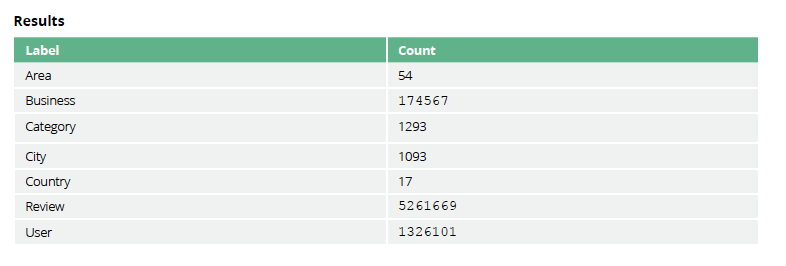
The following queries return the cardinalities of node labels and relationship types.
CALL db.labels()
YIELD label
CALL apoc.cypher.run("MATCH (:`"+label+"`)
RETURN count(*) as count", null)
YIELD value
RETURN label, value.count as count
ORDER BY label
CALL db.relationshipTypes()
YIELD relationshipType
CALL apoc.cypher.run("MATCH ()-[:" + `relationshipType` + "]->()
RETURN count(*) as count", null)
YIELD value
RETURN relationshipType, value.count AS count
ORDER BY relationshipType
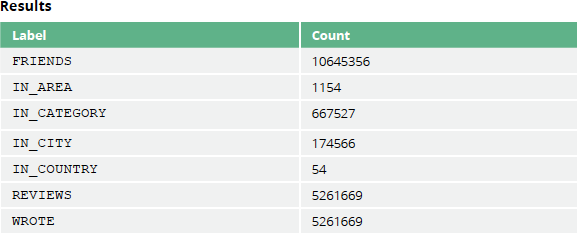
These queries shouldn’t reveal anything surprising but they are useful for checking that the data has been imported correctly.
It’s always fun reading hotel reviews, so we’re going to focus on businesses in that sector. We find out how many hotels there are by running the following query.
MATCH (category:Category {name: "Hotels"})
RETURN size((category)<-[:IN_CATEGORY]-()) AS businesses

That’s a decent number of hotels to explore.
How many reviews do we have to work with?
MATCH (:Review)-[:REVIEWS]->(:Business)-[:IN_CATEGORY]->(:Category {name:"Hotels"})
RETURN count(*) AS count

Let’s zoom in on some of the individual bits of data.
Trip planning
Imagine that we’re planning a trip to Las Vegas and want to find somewhere to stay.

We might start by asking which are the most reviewed hotels and how well they’ve been rated.
MATCH (review:Review)-[:REVIEWS]->(business:Business),
(business)-[:IN_CATEGORY]->(:Category {name:"Hotels"}),
(business)-[:IN_CITY]->(:City {name: "Las Vegas"})
WITH business, count(*) AS reviews, avg(review.stars) AS averageRating
ORDER BY reviews DESC
LIMIT 10
RETURN business.name AS business,
reviews,
apoc.math.round(averageRating,2) AS averageRating

These hotels have a lot of reviews, far more than anyone would be likely to read. We’d like to find the best reviews and make them more prominent on our business page.
Finding influential hotel reviewers
One way we can do this is by ordering reviews based on the influence of the reviewer on Yelp.
We’ll start by finding users who have reviewed more than five hotels. After that we’ll find the social network between those users and work out which users sit at the center of that network. This should reveal the most influential people. The FRIENDS relationship is an example of a bidirectional relationship, meaning that if Person A is friends with Person B then Person B is also friends with Person A. Neo4j stores a directed graph, but we have the option to ignore the direction when we query the graph.
We want to execute the PageRank algorithm over a projected graph of users that have reviewed hotels and then add a hotelPageRank property to each of those users. This is the first example where we can’t express the projected graph in terms of node labels and relationship types. Instead we will write Cypher statements to project the required graph.
The following query executes the PageRank algorithm.
CALL algo.pageRank(
"MATCH (u:User)-[:WROTE]->()-[:REVIEWS]->()-[:IN_CATEGORY]-> (:Category {name: "Hotels"}) WITH u, count(*) AS reviews WHERE reviews > 5 RETURN id(u) AS id", "MATCH (u1:User)-[:WROTE]->()-[:REVIEWS]->()-[:IN_CATEGORY]-> (:Category {name: "Hotels"}) MATCH (u1)-[:FRIENDS]->(u2) WHERE id(u1) < id(u2) RETURN id(u1) AS source, id(u2) AS target", {graph: "cypher", write: true, direction: "both", writeProperty: "hotelPageRank"})
We then write the following query to find the top reviewers.
MATCH (u:User)
WHERE u.hotelPageRank > 0
WITH u
ORDER BY u.hotelPageRank DESC
LIMIT 5
RETURN u.name AS name,
apoc.math.round(u.hotelPageRank,2) AS pageRank,
size((u)-[:WROTE]->()-[:REVIEWS]->()-[:IN_CATEGORY]->
(:Category {name: "Hotels"})) AS hotelReviews,
size((u)-[:WROTE]->()) AS totalReviews,
size((u)-[:FRIENDS]-()) AS friends

We could use those rankings on a hotel page when determining which reviews to show first. For example, if we want to show reviews of Caesars Palace, we could execute the following query.
MATCH (b:Business {name: "Caesars Palace Las Vegas Hotel & Casino"})
MATCH (b)<-[:REVIEWS]-(review)<-[:WROTE]-(user)
RETURN user.name AS name,
apoc.math.round(user.hotelPageRank,2) AS pageRank,
review.stars AS stars
ORDER BY user.hotelPageRank DESC
LIMIT 5

This information may also be useful for businesses that want to know when an influencer is staying in their hotel.
Finding similar categories
The Yelp dataset contains more than 1,000 categories, and it seems likely that some of those categories are similar to each other. That similarity is useful for making recommendations to users for other businesses that they may be interested in.
We will build a weighted category similarity graph based on how businesses categorize themselves. For example, if only one business categorizes itself under Hotels and Historical Tours, then we would have a link between Hotels and Historical Tours with a weight of 1.
We don’t actually have to create the similarity graph – we can run a community detection algorithm, such as Label Propagation, over a projected similarity graph.
CALL algo.labelPropagation.stream
"MATCH (c:Category) RETURN id(c) AS id",
"MATCH (c1:Category)<-[:IN_CATEGORY]-()-[:IN_CATEGORY]->(c2:Category)
WHERE id(c1) < id(c2)
RETURN id(c1) AS source, id(c2) AS target, count(*) AS weight",
{graph: "cypher"})
YIELD nodeId, label
MATCH (c:Category) WHERE id(c) = nodeId
MERGE (sc:SuperCategory {name: "SuperCategory-" + label})
MERGE (c)-[:IN_SUPER_CATEGORY]->(sc
The diagram below shows a sample of categories and super categories after we’ve run this query.

We write the following query to find some of the similar categories to hotels.
MATCH (hotels:Category {name: "Hotels"}),
(hotels)-[:IN_SUPER_CATEGORY]->()<-[:IN_SUPER_CATEGORY]-(otherCategory)
RETURN otherCategory.name AS otherCategory
LIMIT 5

Not all of those categories are relevant for users in Las Vegas, so we need to write a more specific query to find the most popular similar categories in this location.
MATCH (hotels:Category {name: "Hotels"}),
(lasVegas:City {name: "Las Vegas"}),
(hotels)-[:IN_SUPER_CATEGORY]->()<-[:IN_SUPER_CATEGORY]-(otherCategory)
RETURN otherCategory.name AS otherCategory,
size((otherCategory)<-[:IN_CATEGORY]-()-[:IN_CITY]->(lasVegas)) AS count
ORDER BY count DESC
LIMIT 10

We could then make a suggestion of one business with an above average rating in each of those categories.
MATCH (hotels:Category {name: "Hotels"}),
(lasVegas:City {name: "Las Vegas"}),
(hotels)-[:IN_SUPER_CATEGORY]->()<-[:IN_SUPER_CATEGORY]-(otherCategory),
(otherCategory)<-[:IN_CATEGORY]-(business)-[:IN_CITY]->(lasVegas)
WITH otherCategory, count(*) AS count,
collect(business) AS businesses,
apoc.coll.avg(collect(business.averageStars)) AS categoryAverageStars
ORDER BY count DESC
LIMIT 10
WITH otherCategory,
[b in businesses where b.averageStars >= categoryAverageStars] AS businesses
RETURN otherCategory.name AS otherCategory,
[b in businesses | b.name][toInteger(rand() * size(businesses))] AS business

In this blog, we’ve shown just a couple of ways that insights from graph algorithms are used in a real-time workflow to make real-time recommendations. In our example we made category and business recommendations but graph algorithms are applicable to many other problems.
Graph algorithms can help you take your graph-powered application to the next level.
Conclusion
Graph algorithms are the powerhouse behind the analysis of real-world networks – from identifying fraud rings and optimizing the location of public services to evaluating the strength of a group and predicting the spread of disease or ideas.
In this series, you’ve learned about how graph algorithms help you make sense of connected data. We covered the types of graph algorithms and offered specifics about how to use each one. Still, we are aware that we have only scratched the surface.
If you have any questions or need any help with any of the material in this series, send us an email at [email protected]. We look forward to hearing how you are using graph algorithms.
Learn about the power of graph algorithms in the O’Reilly book,
Graph Algorithms: Practical Examples in Apache Spark and Neo4j by the authors of this article. Click below to get your free ebook copy.
Share Article



Explore
Related Articles

A workbench for teams to query, explore, and visualize graph data

SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3


