Graph algorithms in Neo4j: How connections drive discoveries

Graph Analytics & AI Program Director
4 min read

Graph algorithms are the powerhouse behind the analysis of real-world networks — from identifying fraud rings and optimizing the location of public services to evaluating the strength of a group and predicting the spread of disease or ideas.

In this series on graph algorithms, we’ll discuss the value of graph algorithm and what they can do for you. This week, we’ll take a look at how powerful graph algorithms offer a practical approach to graph analytics and review an example of how to find the most influential categories in Wikipedia using Neo4j.
Algorithms: The graph analysis powerhouse
Based on the unique mathematics of graph theory, graph algorithms use the connections between data to evaluate and infer the organization and dynamics of complex systems. Data scientists use these penetrating graph algorithms to surface valuable information hidden in connected data. They then use this analysis to iterate prototypes and test hypotheses.
A practical approach to graph analytics
Graph analytics have value only if you have the skills to use them and if they can quickly provide the insights you need. Therefore, the best graph algorithms are easy to use, fast to execute and produce powerful results.
For transactions and operational decisions, you need real-time graph analysis to provide a local view of relationships between specific data points. To discover the overall nature of networks and model the behavior of intricate systems, you need global graph algorithms that provide a broad view of patterns and structures across all data and relationships.
Other analytics tools layer graph functionality atop databases with non-native graph storage and computation engines. These hybrid solutions seldom support ACID transactions, which can ruin data integrity. Also, they must execute complicated JOINs for each query, crippling performance and wasting system resources.
Alternatively, you could maintain multiple environments for graph analytics, but then your algorithms aren’t integrated with – nor optimized for – a graph data model. This bulky approach is less efficient, less productive, more costly and greatly increases the risk of errors.
Real-time graph algorithms require exceptionally fast (millisecond-scale) results whereas global graph algorithms can be very computationally demanding. Graph analytics must have algorithms optimized for these different requirements with the ability to efficiently scale — analyzing billions of relationships without the need for super-sized or burdensome equipment. This kind of versatile scale necessitates very efficient storage and computational models as well as the use of state-of-the-art algorithms that avoid stalling or recursive processes.
Finally, a collection of graph algorithms must be vetted so your discoveries will be trustworthy and include ongoing educational material so your teams will be up to date. With these fundamental elements in place, you make progress on your breakthrough applications with confidence.
Analyzing category influence in Wikipedia
Let’s look at an example of how to use Neo4j graph analytics to analyze the most influential categories in Wikipedia searches.
The graph below shows only the largest of 2.6 million clusters found with the most influential categories in green. It reveals that France has significant influence as a large cluster-category with many, high-quality transitive links.
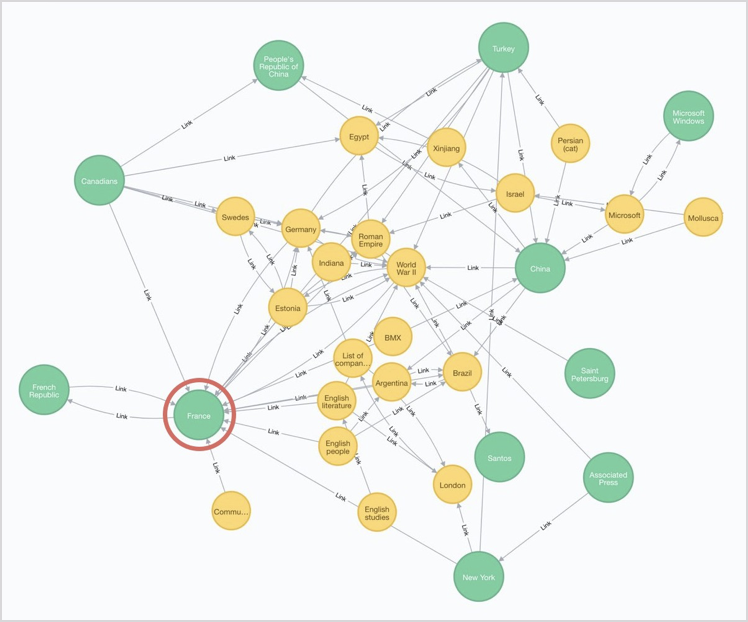
The Neo4j Label Propagation algorithm grouped related pages as a cluster-category in 24 seconds and then PageRank was used to identify the most influential categories by looking at the number and quality of transitive links in 23 seconds (using 144 CPU machine and 32GB RAM of 1TB total, SSD).
Conclusion
Graph algorithms must be optimized to support different use cases. Real-time recommendations demand real-time graph analysis, while finding patterns in large datasets requires global graph analysis. Optimized graph algorithms support all use cases with high performance.
In the coming weeks, we’ll take a closer look at the Neo4j Graph Platform that supports graph analytics, including its performance versus Spark GraphX. We’ll also explore specific examples of the wide range of powerful algorithms that Neo4j supports.
Learn about the power of graph algorithms in the O’Reilly book,
Graph Algorithms: Practical Examples in Apache Spark and Neo4j by the authors of this article. Click below to get your free ebook copy.
Share Article



Explore
Related Articles

SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3



Why machines need embeddings: Turning graph structure into features

Finding hidden bottlenecks in flight networks with Aura graph analytics on Databricks
