
Graph Data Platforms: Collections vs. Connections

Vice President, Product Marketing
1 min read

You may have heard that graph database technology underpins the latest in machine learning and AI. But what are graph data platforms and why are they rapidly becoming the first choice for application development? Can a shift in database technology really make a big difference?
In this second blog of our two-part series, we look at how SQL databases and NoSQL databases handle connected data and explain how graph data platforms, focused on data relationships, drive numerous benefits.
SQL & NoSQL Systems Focus on Data Aggregation & Collection
Collection-centric storage designs as implemented by SQL and Not only SQL (NoSQL) databases are designed to efficiently divide and store data.
In SQL’s case, the normalization of data into a tabular schema aims to minimize storage of duplicate data objects, types and values. These systems were born during the era of scarce physical memory and expensive disk-based storage, designed to avoid managing often-redundant data objects such as physical location addresses for shipping, billing, homes, offices, destinations, businesses, etc. For example, all of these data objects included common, redundant data such as a country and its provinces or states, or telephone area codes and postal codes.
The original relational databases were designed to minimize storage of duplicative data values because disk space was costly. (Ironically, each normalization incurs a cost in relationship storage in the form of JOIN tables, which native graph databases have managed to eliminate through the use of pointers.) The RDBMS design achieved this consolidated, normalized goal by linking tables of data via foreign keys to their associated records from other tables. This is why a relational dataset modeled into a graph often shrinks by an order of magnitude or more, maintaining the full richness of the data without redundant data storage.
NoSQL systems like document, wide column and key-value data stores carry those concepts forward (and backward) by simplifying their models in exchange for higher levels of scale and simplicity. By eschewing data relationships and providing straightforward programmatic APIs, NoSQL systems make it easy for developers and administrators to work with simple data in a way that can easily scale.

A lack of concern about relationships leads to looser data guarantees, plain APIs and straightforward scaling schemes. Data is easily spread out and just as easily retrieved, without the need to maintain the integrity of related data that’s written across a distributed storage or a cluster of machines and without needing to concern itself with the performance of distributed JOINs across those machines.
These systems take on the “store and retrieve” problem at scale for simple data, and their architectures reflect this, as does the set of problems they are equipped to address. However, none of these systems focus on interrelated, contextualized data or how that data might be traversed to reveal unobvious relationships, as explained below.
Graph Systems Focus on Data Connections
By contrast, graph database technologies focus on how data elements are interrelated and contextualized as connected data.
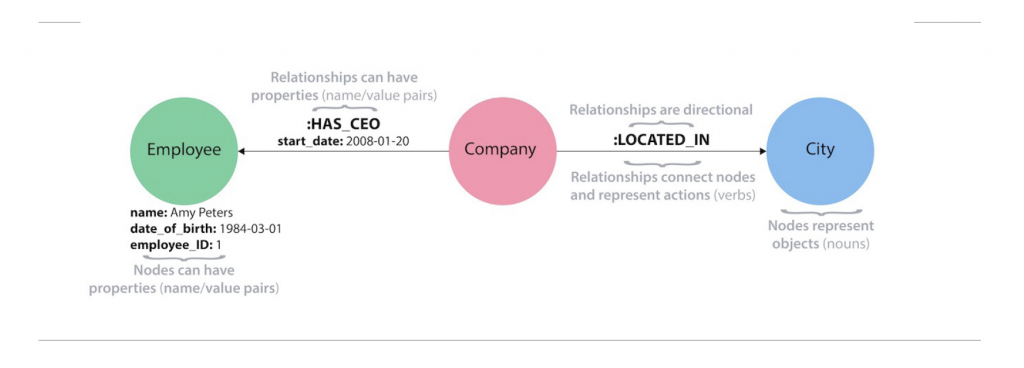
Connected data is the materialization and harnessing of relationships between data elements, which is modeled as a property graph.
A property graph is a data model designed to express data connectedness as nodes connected via relationships to other nodes, where both nodes and relationships can have properties attached to them (which in turn can be indexed). For example, devices on an enterprise network might be modeled as nodes, with properties for their attributes (such as throughput) and relationships pointing to other adjacent devices.
In the graph model, data relationships are persisted so they can be navigated or traversed along connected paths to gain context. Relationships are both typed and directional.
The context provided by these data connections is essential to identifying friendships, making relevant real-time recommendations, attaching adjacent ideas and detecting fraud by following money trails. Without relationships as first-class data entities, all of these use cases
become extremely difficult to execute.
Property Graphs Are Intentionally Simple
- You can draw property graphs on whiteboards and map that design directly into a
graph database. - You can change or update a property graph easily, because its agile design eliminates
most of the structural overhead of traditional database schemas. - You can quickly program property graphs because their query language expresses and
follows relationships. - You can visualize and navigate property graphs efficiently by following the relationships
on their paths to context. - You can rapidly determine data context when property graph queries are executed in
hyper-fast native graph platforms built on reliable, scalable database architectures.
Benefits of Graph Databases
- Simple and natural data modeling: Graph databases provide flexibility for data
modeling, depending on relationship types. Since the graph model comes with no
inherent rules, graph data stores add as much or as little semantic meaning as the
domain requires. This occurs without any constraints like normalization or restructuring
of the data using denormalization. - Flexibility for evolving data structures: Graph technology provides flexible schema
evolution. In a constantly changing data environment, you need the option to add or
drop data entities or relationships, as well as extend or modify your data model. Graph
databases allow for evolving data structures that match today’s agile development
environments. - Simultaneous support for real-time updates and queries: A graph data store and
its model allow real-time updates on graph data while supporting queries concurrently. - Better, faster and more powerful querying and analytics: Graph data stores provide superior query performance with connected data using native storage and
native indexed data structure.
Connected data in property graphs enables you to illustrate and traverse many relationships and find context for your next breakthrough application or analysis.
Conclusion
Today, businesses need to bring together data from many different systems, which is driving a huge shift from on-premises to cloud as well as investments in new data integration models. Traditional rigid systems aren’t nimble enough to keep up with the pace of change. Supporting complex data environments often requires real-time data analysis to make split-second decisions to optimize the business.
Making the most of your data requires the ability to make connections across all of it. As the fastest growing database technology in the past decade, graph databases provide a much more scalable, secure and flexible platform than traditional databases for enterprises to deploy their use cases – from real-time recommendation engines to fraud detection to knowledge graphs to AI and machine learning.
What will your first use case be? Find out more about Neo4j. Sign up for a 30-minute demo with a live Q&A.
Share Article



Explore
Related Articles

What Are the Different Types of Graph Algorithms & When to Use Them?


Neo4j Expands AWS Collaboration With New Competencies in Finance, Automotive, GenAI, and ML

GenAI Graph Gathering 2.0: The Evolution of GraphRAG

