







A Graph-Specialized ETL: Taking Citizens into a Graph and Keeping It Up to Date

Project Manager, Kale Yazılım
8 min read

In this post I want to talk about the challenges we faced during our graph journey and how we overcame them. The outline of this post is as follows.
- Why do we need ETL and sync from SQL to a graph
- Benefits of taking citizen data into a graph
- Challenges in data modeling, export and import
- Change data capture
- Our approach
Why Do We Need ETL and Sync from SQL to a Graph
The digital universe is doubling in size every two years and expected to reach 44 zettabytes by 2020.
With such a vast amount of data, the patterns and connections in data become as important as the data itself. To be able to discover and use those patterns and connections for business purposes, information technology veterans increasingly use graph databases. Although they are reluctant to alter their online transaction processing systems, they can’t resist the appeal created by the power of graph computing, especially due to the fact that Neo4j has reduced previously complex and scary graph science to such simple and smart solutions (yeah Cypher rocks!).
We have been dealing with census data for more than 15 years. It was 2-3 years ago when we hit the graph database concept and Neo4j, while we were looking for possible solutions for some big data analysis requirements. In fact we had spent some time on key-value and column-family databases till one day we realized that we were trying to construct a graph using other NoSQL databases. After that, it did not take long to come upon the native graph solution: Neo4j.
The Benefits of Taking Citizen Data into a Graph
Shortly after initial POC practices, it became quite clear that representing citizen data as a graph database was the perfect solution for the following scenarios among many others:
- Providing comprehensive and online real-time ancestral trees for citizens
- Determining heirs and calculating heritage shares
- Identifying old/helpless citizens without any relatives living nearby
- Constructing domestic / international migration routes, investigating causes and discussing consequences
For instance, it would require four join operations on tables with more than 100 million rows to reach a close relative such as a cousin of a person, which would require a lot more effort for the developer and consume a lot more system resources compared to Neo4j. After realizing that great potential in graph databases, it was no longer possible for us to even consider a citizen database not making use of a graph database.
If you already have a small or well-designed SQL data, it is relatively easy to construct a property-graph model and make the initial data load. However, defining the graph data model and ETL process for our data, which was first designed 25 years ago according to legislative regulations that dates back to 19th century and have been subject to frequent updates, had its own story.
First let’s look at some of the challenges in data modeling.
Challenges in Data Modeling
- Mutual relations will be an early subject of discussion especially if humans are a part of your conceptual domain. We had initially designed the spouse relationship as mutual. So there were two spouse relationships, one from wife to husband and one from husband to wife.
Although that looked good on the screen at first, it became a real drawback when we began to perform analysis depending on human relations. They caused circular relations misleading our analysis. We ended up just creating one relation for each couple. You may also define two different relationship types like wife and husband if your queries require so, but we would advise you to think carefully about it.
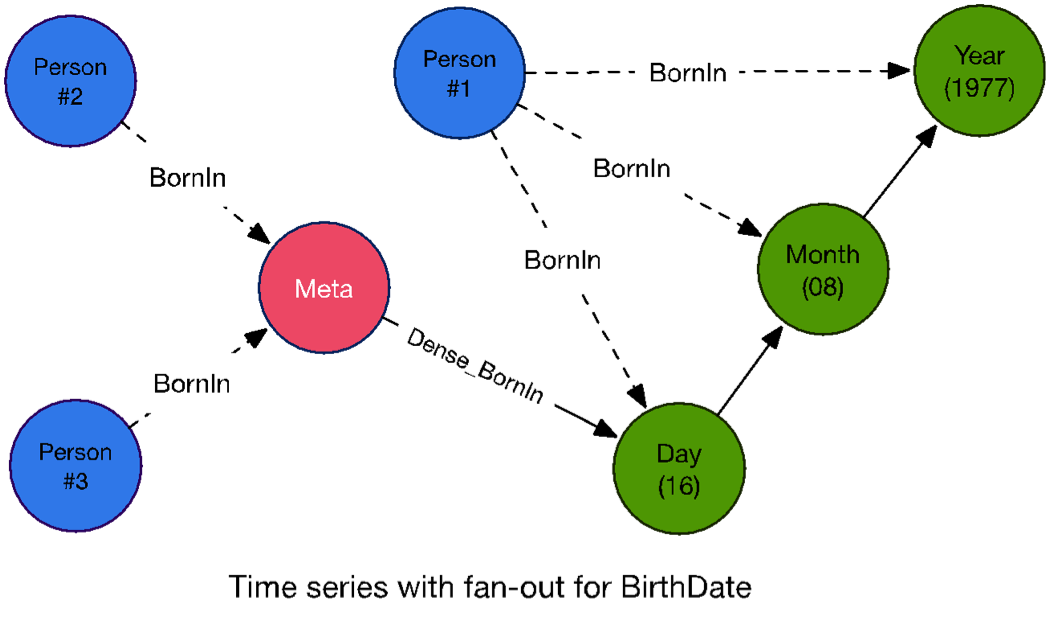
- Birthdate info is represented with three separate nullable fields in census database because of old records which don’t have exact birthdate information. In addition, it is a valuable information that we often use as a criteria in queries.
So we designed it as a “time series tree” such that
(Day)-[Day_Of]->(Month)-[Month_Of]->[Year]starting from year 1000. APersonnode can be connected to aDaynode if it has a complete birthdate information, connected to aMonthnode if day information is missing and connected to aYearnode if the year of birth is all we know. - Another problem arose when we began expanding person nodes after loading birthdate data. There are thousands of people born on the same day causing dense nodes that can possibly slow down traversals across these nodes (depending on queries).
As discussed in the Learning Neo4j (by Rik Van Bruggen, Packt Publishing) book you can apply a fan-out strategy for that. We have to stress that you should maintain fan-out levels (meta nodes) as data changes to not introduce new dense nodes.
- You can’t always extract relationships directly from existing explicit or implicit table relations. One example is the marriages that ended with a divorce, which we want to define as “ExSpouse”.
Unfortunately you have to check out the marriage registrations table for marriage records, eliminate current wife and then distinguish widows as well. This is an extraordinary mapping from SQL to graph that you have to manage in both initial data load and data synchronization.

Challenges in Exporting and Loading Data
- Time spent to export your relational data: When you have billions of records for numerous tables, it takes really long to extract that data. We managed to shorten it by parallelizing the export process. It is possible to do it in several ways:
- If you have such a table, possibly it is already stored in partitions. So make use of it and export partitions in parallel.
- Another good practice is to divide into ranges by primary keys or unique indexes.
- If none of the above are applicable, dividing by non-unique indexes would also do work.
- Time spent to import: You successfully exported your massive data, and it is now time to import. Depending on your data, it can also take long to import it in with the
LOAD CSVcommand. If you are making an initial load, using “batch import” instead ofLOAD CSVwould save a lot of your time. It is also possible to use them in conjunction; let the batch import do the heavy work and LOAD CSV to handle the fine work. - Character encoding: During both export and import you need to check the tools used, exported files and the environment for regional settings. It is very disheartening to start over when you realize such a problem at the end.
- Special characters: You may have to replace them during export like replacing ” (double quotes) with ‘ (single quote). Text fields may also include separator characters that you will have to take care of.
- Null values in source data: If you are using
LOAD CSV, the following statement will make Cypher ignore attributes with values: SET n.FieldX = CASE trim(row.FieldX) WHEN "" THEN null ELSE row.FieldX END- For batch import you can simply use the
--ignore-empty-strings trueoption - Absence of unique identifiers: For batch import you will have to provide a unique id for each node.
Keeping It Up to Data (Change Data Capture)
Keeping your RDBMS and graph database synchronized is challenging. I will remark just some important matters here.
- Change Data Capture (CDC) mechanisms heavily depend on your relational database product. Below are possible solutions applicable to popular RDBMS.
- A common solution is to create triggers to track data manipulations in tables you are interested in. Those triggers may populate a single delta table with necessary information such as table name, change type, changed data, timestamp, etc. You have to manage transactions and preserve order of transactions to guarantee the integrity of both SQL and graph.
- If you are not good with triggers and are ready to make some investment, it is a better choice to use a CDC solution (Oracle GoldenGate, SQL Server Integration Services, IBM InfoSphere Change Data Capture, etc.) that is compatible with your RDBMS product.
- Whatever CDC mechanism you choose, it is a good practice to establish a uniform CDC data structure to use as the input of the component that carries out data transformation and load.
- Apart from the CDC mechanism, handling data changes may be tricky depending on your data structure. Here are some examples:
- Nodes that do not originate directly from a record are a consideration. For instance, in census data there is not a particular table for a family record. It is implicitly represented by family IDs assigned to citizens. So a new family is introduced to the database when a foreigner becomes a citizen, and a new family ID is assigned. We have to create a new family node to add that person to the graph.
- The birth date issue mentioned above is also a challenge in CDC. You have to employ a mechanism to find the exact meta node to connect and also create a new one if it reaches the threshold you determined.
- Another interesting case is when your source data has a versioned structure. Your solution depends on whether you want versioned data in the graph as well or want to aggregate them to a single node. In our case we needed to aggregate versions to a single node. So for every insertion or update we analyze whether it is really an insert, an update or a delete and act accordingly.
Our Approach
Obviously, there are a number of issues to consider for employing a graph database while using a relational database as the master data source. We concluded that building a generic ETL solution that is specialized in transforming and continuously synchronizing RDBMS data to a graph database would be the perfect solution to those issues.
Our design approach is to define the ETL process as a declaration of a transformation model that is independent of its execution, rather than defining business processes.
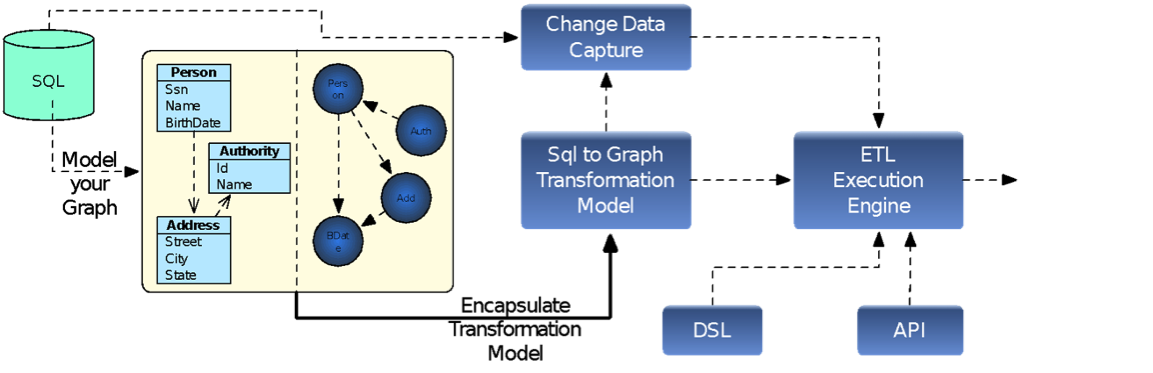
The system consists of the following components:
- A visual design tool that enables you to:
- Design a graph data model
- Define the transformation model from SQL to graph
- Capture those models as a DSL
- An ETL execution engine that:
- Executes initial load
- Executes the ETL model
- Provided as DSL
- Developed using the API provided
- Continuously synchronizes data from SQL to graph
Our ETL execution engine provides the infrastructure to satisfy the requirements like Change Data Capture, consistency, durability, robustness, resiliency, high throughput, etc.
Here is the high-level diagram for our ETL solution:
If you want to learn more about our ETL solution please join us GraphConnect Europe. We will be giving a Lightning Talk at 12:10 p.m. that takes a deeper dive into our ETL solution.
I would like to thank my colleagues Can, Bilgesu, Başar, Volkan and our V.P. Ali for their devotion to our product and precious contribution to this post.
Kale Yazılım is a Bronze Sponsor of GraphConnect Europe. Click below to register for GraphConnect and meet İrfan and the rest of the Kale Yazılım team in London on 26 April 2016.
Share Article



Explore
Related Articles
Turning ServiceNow Data into Connected Enterprise Intelligence
A knowledge layer for your agentic systems on Google Cloud


The Context Gap: Why Your Smart-Sounding AI Struggles to Reason

From data to intelligence: Why every enterprise needs an AI knowledge layer
