


Property Sharding in Infinigraph: Smarter Scaling for Rich Graph Databases

Senior Product Manager, Neo4j
4 min read
When your graph grows, so do your challenges.
A dataset often starts small, then blossoms into billions of nodes and relationships — each carrying dozens of properties. At some point, the graph topology isn’t the bottleneck. It’s the properties themselves: hundreds of attributes, wide documents, and rich metadata hanging off each node.
Our new property sharding feature helps you manage this growth without sacrificing performance, structure, or ease of use. It distributes properties across multiple database shards while keeping the graph structure intact.
Scaling Without Splitting the Graph: Why Property Sharding?
A property graph model represents data as nodes (entities) and relationships (connections between entities), both of which can have properties (key-value pairs). Traditional horizontal scaling strategies assume you need to split the graph itself. But relationships are the lifeblood of graphs — and they don’t like being pulled apart.
Instead, we decided to focus on the real scaling pain points our users face:
- Nodes and relationships with massive property payloads that don’t fit comfortably in memory
- Caching inefficiency when property-heavy nodes dominate hot query paths
Property sharding in Infinigraph separates property data into specialized shards while leaving the topology shard lean and efficient.
And you still get:
- ACID compliance: Fully transactional and consistent
- Simplicity: Transparent to the user, using standard Cypher queries
- Analytics support: Works seamlessly with query, exploration, and graph data science tools
- Full API transparency: No application-level rewrites required
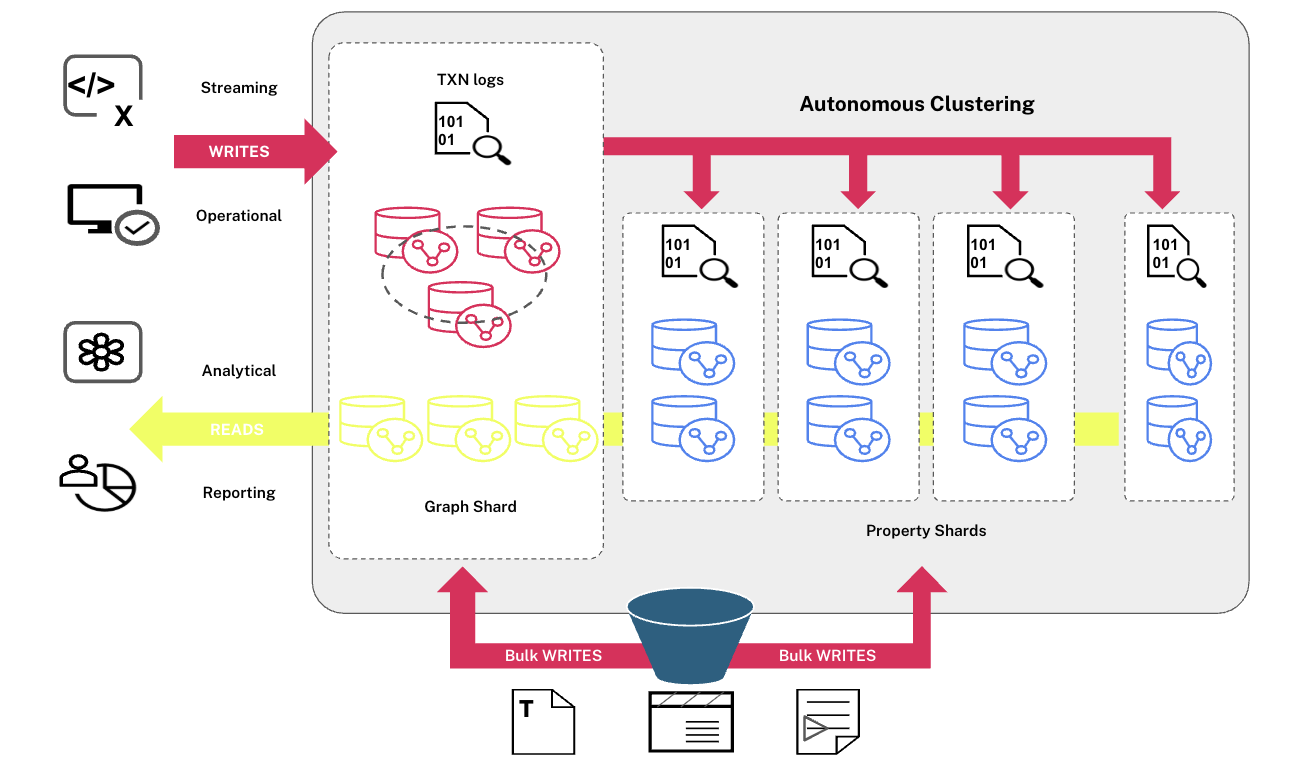
Sharding in Autonomous Clusters: How It Works
At the heart of property sharding is the Neo4j autonomous cluster. Here’s what happens:
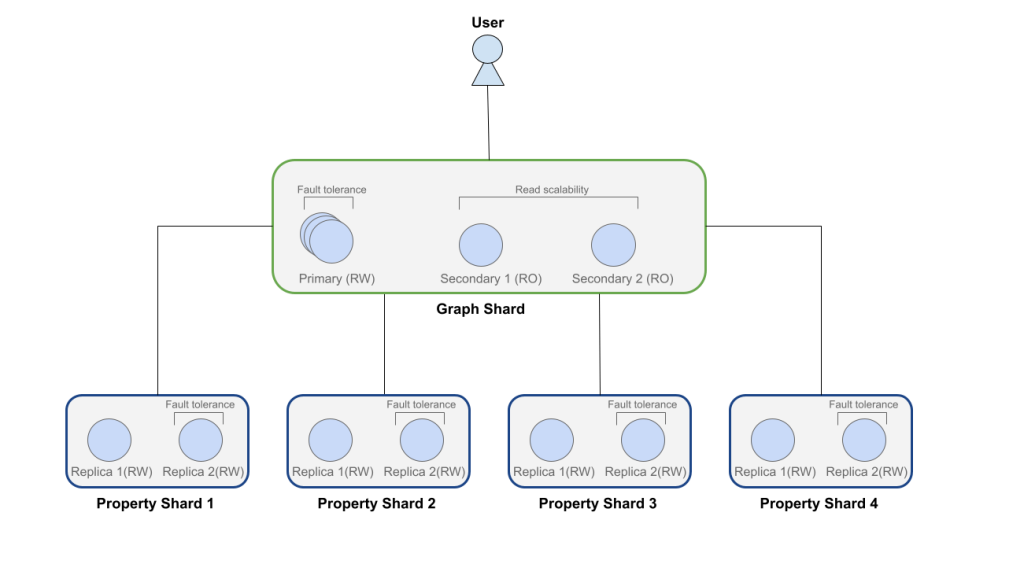
- A graph shard stores the topology, nodes, relationships, labels, and unique identifiers.
- Property shards store the properties, distributed evenly using a hash function.
Each entity in the graph shard has exactly one corresponding entity in a property shard. When a query requests properties, the system automatically fetches them from the right shard, while traversal stays local to the topology shard.
The whole system runs in an autonomous cluster. The graph shard forms a regular Raft group, ensuring availability and failover. Property shards can be scaled independently by adding replicas, which provides them with high availability, a new feature introduced for property sharding in the Neo4j autonomous cluster.
The transaction is managed by the Raft group. The data is then propagated to all the property shards by the transaction logs.
A Quick Walkthrough
This is an introduction, so we’ll keep it simple and avoid complex queries on property-heavy graphs — graphs built for fraud analysis on financial transactions, for example, or shiny LLM applications using GraphRAG with heavy vector indexes.
Instead, let’s go through the concepts using a familiar friend: the Neo4j movie database.
The beauty of property sharding is that the Cypher commands are still the same for users.
Adding Data
You use CREATE or MERGE to add nodes or relationships to the database.
MERGE (TheMatrix:Movie {title:'The Matrix'})
ON CREATE SET TheMatrix.released=1999, TheMatrix.tagline='Welcome to the Real World'
MERGE (Keanu:Person {name:'Keanu Reeves'})
ON CREATE SET Keanu.born=1964
MERGE (Keanu)-[:ACTED_IN {roles:['Neo']}]->(TheMatrix)
But the result is different:
- The nodes and relationships are written to the graph shard.
- The sharding algorithm assigns properties (e.g., released, tagline, born, roles) to the appropriate property shards. A node’s properties and outgoing relationships are assigned to the same shard.
- Since allocation is random, related entities may end up in different shards. In this example, properties of the Keanu node and properties of the TheMatrix node will most likely end up on different shards.
Querying Across Shards
From the application’s perspective, you still query a single logical graph:
MATCH (p1:Person {name:"Tom Hanks"})-[:ACTED_IN]->(m)<-[:ACTED_IN]-(coActors),
(coActors)-[:ACTED_IN]->(m2)<-[:ACTED_IN]-(p2:Person {name:"Keanu Reeves"})
RETURN DISTINCT coActors.name AS matchmaker
This is how it works:
- The traversal runs entirely on the graph shard.
- At the final stage, property lookups are batched and fetched from property shards.
This keeps the page cache of the graph shard dedicated to relationships and structure, improving efficiency.
Benefits and Limitations of Property Sharding
Benefits
- Simple queries: Applications don’t change. Cypher queries work as usual.
- Scalable storage: Distribute massive property sets without splitting relationships.
- Operational flexibility: Property shards and the graph shard can each be tuned for their purpose.
- Better cache efficiency: The graph shard stays lean, focused on traversal.
Limitations
- No automatic rebalancing in its first version: The number of property shards is fixed at creation. They don’t rebalance themselves. We’ll introduce rebalancing at a later stage.
- Best for property-heavy graphs: This is not a one-size-fits-all solution — the benefits are most visible in property-heavy graphs.
Get Started With Property Sharding
Property sharding is a new way to scale Neo4j graphs without sacrificing clarity or control. By decoupling properties from relationships, you gain flexibility in how you manage data — without losing the power of connectedness.
So the next time your nodes start to feel a little property-heavy, don’t panic. Shard smart.
Property sharding is available in our Early Access Program. If you’re dealing with property-heavy workloads, contact us to join the EAP.
Sign Up for Our Webinar to See Property Sharding in Action
Find out how you can scale with speed, power, and flexibility.
Share Article



Explore
Related Articles

Neo4j Community Edition Advances for Graph-Powered AI and Intelligent Applications

Power Connected Intelligence for AI and Analytics with Neo4j and Databricks

Neo4j Brings High Speed Identity Resolution to the Snowflake AI Data Cloud

The Data Strategy That Makes Truly Personalized Customer Experiences Possible

Finding the Fastest Way Out: How Dijkstra’s Algorithm Finds Shortest Paths
