Editor’s Note: Last October at GraphConnect San Francisco, Ian Robinson – Senior Engineer at Neo Technology – delivered this in-depth presentation on how to effectively scale your Neo4j-based application for enterprise-level production.
For more videos from GraphConnect SF and to register for GraphConnect Europe, check out graphconnect.com.
If you’re planning on taking a Neo4j-based app into production, you’re probably already thinking about the most appropriate application architecture for your use case, and how – once you’ve built your app – you’ll deploy and operate it at scale.
In this talk from GraphConnect, I look at some of the most important considerations around designing, building and operating a Neo4j app. Topics include:
- Where Neo4j fits in your application architecture, in both its embedded and server modes
- How to configure its clustering for high availability and high read throughput
- Backup strategies
- The new monitoring capabilities in Neo4j 2.3
My Full Presentation:
What we’re going to be talking about today is deploying and moving your Neo4j-based application into production.
We’ll talk about some of the things that you want to think about early in the application development lifecycle, some of your deployment options, some of the things that you need to think about when you’re designing your environment, and also some of the operational activities that you’ll want to perform once you’ve got that app into production.
Diving into Neo4j deployment options
So, thinking first about deployment options. There are three different ways in which you can incorporate Neo4j into your app:
- You can use embedded Neo4j
- You can use the server version of the product
- You can use the server together with unmanaged extensions
Embedded Neo4j
This first one: embedded Neo4j. Emil already covered this briefly.
Neo4j started life as an embedded graph database; that is, as a library that you hosted in your own application’s Java process, and you can still do that today.
You can treat Neo4j as a library that makes its data durable on disk, and your application can speak to Neo4j by way of a rich set of Java APIs that allow you to talk in terms of the graph primitives: nodes, relationships, properties and labels.
You also have access to a couple of other APIs: a traversal framework, our graph algorithms package and so on. So that’s one way of incorporating Neo4j into your application, treating it as a library and using embedded Neo4j.
Server version of Neo4j
The more common way of using Neo4j today is to use the server version of the product.
Effectively, we’ve built the server infrastructure that surrounds an embedded graph database instance. So, you spin up a server.
This is our typical experience of a database. We want our databases to be somewhere else on the network. We all have a client driver, and we just expect to be able to speak to that database, talk to the database over the network using that client driver.
That’s effectively what you get with the server version of Neo4j. It’s a server infrastructure that embeds or wraps an embedded graph database instance. This embedded graph database sits in the background there at the heart of that server and then we expose an HTTP API – a set of REST APIs effectively – that allow you to communicate with the server.
This includes a transactional endpoint that allows you, from the client side, to control the scope of the transaction, to start a transaction, to submit multiple queries in the context of that transaction and then finally to close it.
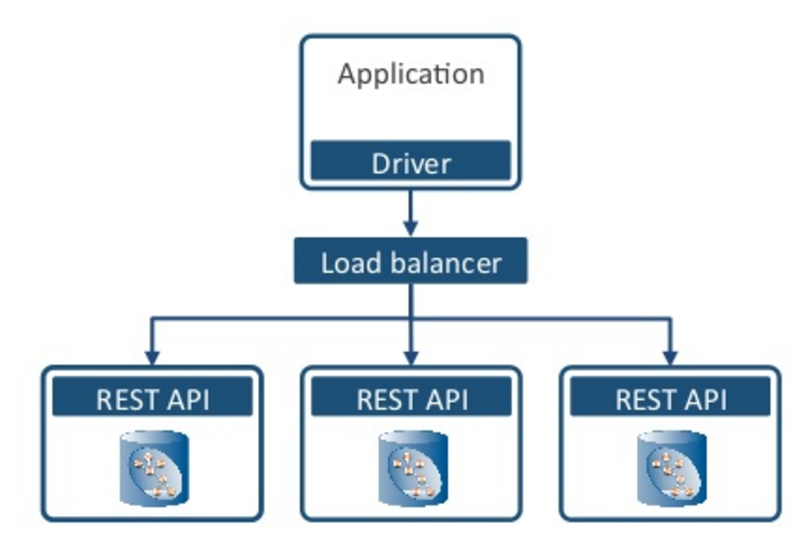
Below is a typical architecture where we’ve got our application code with the stuff that’s specific to your domain, a driver as part of that and typically it’s talking by way of a load balancer to a Neo4j cluster or server instances.

Server version of Neo4j with unmanaged extensions
The third deployment option is to use the server version of the product, but to extend it using what we call unmanaged extensions.
For a long time, we’ve given you the ability to be able to write additional pieces of Java code, and to sit them inside of the server. We call these unmanaged extensions. These extensions have direct access to the embedded graph database that is at the heart of that server.
So from within your unmanaged extension, you can use all of those lower-level Java APIs or the graph algorithm package or the traversal framework in order to talk to the embedded graph database.
Then you expose your extension’s functionality by way of another REST API, a set of URIs. You can think of it as being a cheap way of doing stored procedures, locating some code inside of each server and then using a client to communicate with those extensions.
The advantages here are that you’re still in a network environment, and you’re still dealing with the server version of the product, but your extensions themselves are a lot closer to the data. You can take advantage of those low-level APIs, but they also give you a lot of control over the request and the response format, so you can actually create request and response formats that are more sympathetic to your domain. Instead of talking in terms of nodes, relationships, properties and labels, you may want to talk in terms of products or users and so on.
Deployment options and Neo4j 3.0
So, these are your three different deployment options.
This is a choice that you’ll probably make early in your application development lifecycle. The most common deployments today are either the vanilla server version of Neo4j or quite often the server together with unmanaged extensions.
Any investments that you make in unmanaged extensions today, you will be able to port very easily into Neo4j 3.0 and to those universal language drivers, because effectively you will be able to use the core logic that you develop in any extension and treat that as a stored procedure that you can invoke using the Bolt protocol.
These are some of the upfront deployment options or decisions that you might have to make.
Hardware & software of your production environment
Thinking then about actually moving an application that you have developed into production, we start thinking about those target environments. I’ve got a few thoughts on hardware and software – I’ll go through them quickly.
Hardware
You’re going to perform best if you’ve got machines with lots of cores. Neo4j scales with the number of cores.
If you’re using the community version it scales up to four cores. If you use enterprise then it scales beyond that.
In terms of storage, ideally SSD rather than hard disk and not the kind of commodity SSD, but this more specialized single-level cell SSDs are the kind of things that we recommend.
Another thing: Even though we’re making all of that data durable on disk, you want lots of RAM because you want to be able to cache a lot of that data in memory.
We’ve invested very heavily over the last year and a half or so in the development of this off-heap page cache. This is the thing that’s going to give you a big performance benefit here.
If you can assign lots and lots of RAM to that page cache then you’re going to improve the performance of many of your queries.
Today, we recommend that if you’ve got plenty of RAM, assign between about 8 and 12GB to the heap itself, and then assign lots and lots of the remainder to the page cache.
One thing that I always recommend is that you should explicitly set the size of your page cache using this configuration option here:

If you’ve got enough RAM to cache the entirety of the store in RAM, then you should probably size this at the size of your entire store plus 10 percent plus some considerable headroom for growing that store over time.
If you don’t have enough RAM to map the entirety of the store into memory, remember to leave lots of room for the operating system itself and for any other processes that might be running on that box.
We’re kind of assuming that you’re dedicating machines to running Neo4j, but there are often other processes that you end up running there as well, monitoring or deployment processes, so you need to be able to leave some space for those as well.
If you don’t explicitly configure the page cache, then Neo4j will try to make some intelligent decisions. In versions prior to 2.3, if you didn’t configure explicitly, Neo4j would try and assign about 75 percent of the RAM that was left over, once it deducted the heap size, and try and assign that to the page cache.
In a lot of our testing, we discovered that that can actually create some out-of-memory conditions when we’re really thrashing this thing so we’ve lowered that default value to about 50 percent in 2.3.
So if you don’t actually configure it, then Neo4j will configure it at 50 percent of whatever is left over once we subtract the heap size from the amount of available RAM.
Software
In terms of software, we recommend either openJDK or the Oracle Java 8 JDK. If you are stepping up to use something like Neo4j on IBM POWER8 then we qualify using the IBM JDK on POWER8.
In versions of Neo4j prior to 2.3, the default garbage collector was the CMS collector, but we’ve switched that now to using the G1 garbage collector. We found that by using the page cache plus the G1 garbage collector with no object cache (which was dropped in 2.3), we get far better throughput and far better stability that ever we saw in 2.2 and in previous versions of Neo4j.
So even if you’re on 2.2 today, it’s worthwhile configuring the page cache to work with the G1 garbage collector and then removing the object cache. You’ll experience both improved throughput and increased stability.
If you’re on 2.2, here is the additional configuration you’ll need in order to be able to specify the G1 garbage collector:

Neo4j in cloud environments
Lots of our users now are deploying Neo4j into different cloud environments.
Working with Amazon Web Services (AWS)
The one I’m most familiar with is Amazon. In AWS, we found that you’ve got choices around the instances themselves and then the storage volumes. We recommend choosing HVM (hardware virtual machine) instances. HVM instances perform slightly better for our workloads than the old paravirtual instances.
The volumes themselves should be using Elastic Block Storage (EBS) so that you can snapshot your stores. This is that kind of durable shapshotable storage that AWS offers.
So when you’re choosing your instances, ideally you should either choose instances that are already EBS-optimized or you should provision them as EBS-optimized. This effectively ensures that you’ve got dedicated throughput to those EBS volumes.
The instances that we use for our heavy soak testing are the R3 memory-optimized instances. So with something like r3.xlarge, we get just under 31GB of RAM and that’s four virtual CPUs. With some of our clusters, we go up to r3.4xlarge, where we’ve got a lot more RAM and many more CPUs to play with.
R3 isn’t EBS-optimized by default, so we actually have to provision that when we’re creating instances, whereas C3 and C4 compute-optimized instances are effectively EBS-optimized by default. There are some of the different instance types that we recommend if you’re choosing to deploy into AWS.
Choosing volumes
Neo4j is a database, and therefore is always going to be I/O heavy. Naturally, there’s always going to be a lot of I/O work.
So when you’re choosing your volumes or provisioning your volumes, our recommendation is always to choose provisioned IOPS (I/O operations per second). This effectively gives you the ability to specify or reserve an I/O capacity and that leads to far better, far more predictable performance.
Provisioned IOPS is really there for I/O intensive workloads. And while it’s more expensive, you can provision that at about 30 IOPS per gigabyte with a ratio of 30/1.
For example, if you have a 300GB EBS volume, then you can provision that at about a maximum of 9000 IOPS.
Under very, very high throughput scenarios, you probably will end up maxing out those IOPS, so you need to perhaps increase the size of the volume – and therefore provision more IOPS – but this is stuff that it’s always worthwhile monitoring.
Neo4j’s high availability (HA) architecture
Okay, High Availability (HA) architecture.
Unless you’re building a desktop app or you’re building a small, lightly trafficked, non-critical web app, you’re going to want to be using Neo4j in its clustered form.
We can cluster Neo4j instances for high read throughput and high availability, and this is a feature of the enterprise version of the product. Today, Neo4j employs a traditional master/slave architecture.
Pictured below we have a cluster of three instances and at any one point of time one of those instances will be acting in the role of the master and the master is responsible for coordinating all of the writes to the system.
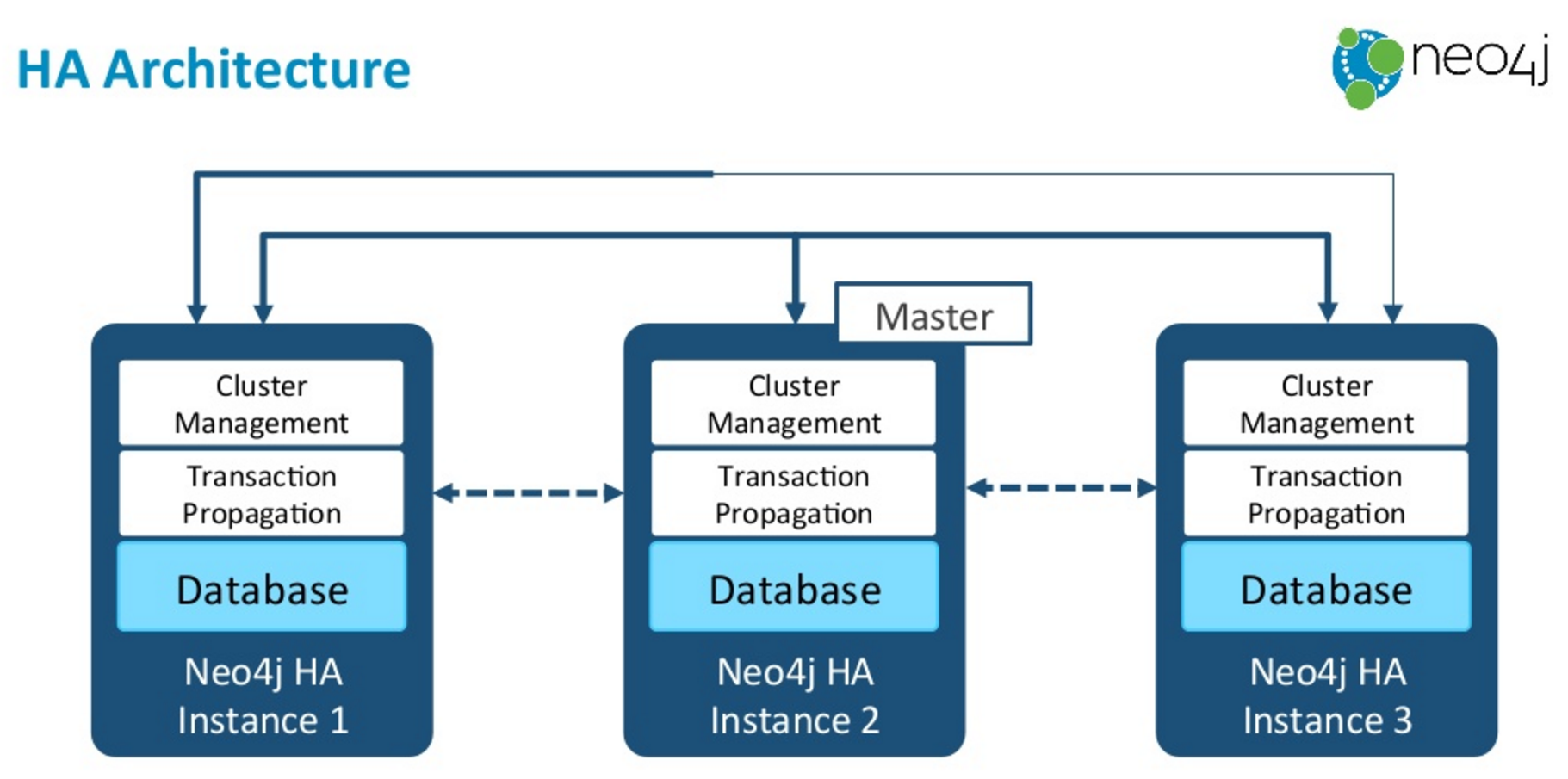
The other instances in the cluster act as slaves, and they’re polling the master at frequent intervals in order to pull transactions across.
So effectively we have two different protocols going on here: We have a Paxos-based cluster management protocol responsible for deciding who’s the master at any one point in time, and then we have a separate transaction propagation protocol which is effectively the slaves pulling transactions from the master.
If you write directly to the master, then, when the control returns to the client, you’re guaranteed your data has been made durable on disk, and the master is immediately consistent with respect to that client.
The overall system, however, is eventually consistent in the order of several milliseconds – whatever the polling interval for those slaves is. Effectively, we’re going to propagate transactions in the course of that polling interval so the overall system will be eventually consistent in the order of several milliseconds.
So we choose HA for high availability and high read throughput.
Considerations for cluster configuration
Let’s cover just a few things to be aware of when you’re configuring your clusters.
Joining clusters
The first thing is a cluster configuration option that we call initial host. Whenever you introduce a new instance into a cluster, we need to supply it with the address of at least one other instance in the cluster that is currently up and running so that it can contact that instance and discover the rest of the cluster.
You can configure it with just one other address in the cluster, or you can configure it with a list of addresses, but the important point is when that instance starts up, all of the addresses that are in that initial host value have to be up and running and contactable at that point in time.
So if you’ve got a very large cluster, and you’re introducing a new instance into it, you probably don’t want to list all of the currently running instances. Probably just limit it to one, two or three other host addresses.
Push and pull transactions
With our transaction propagation protocol, effectively the slaves are pulling transactions from the master. You configure that with this HA pulling tool:
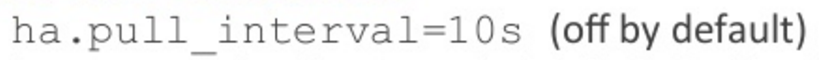
For some reason I’ve forgotten or I’ve never chosen to investigate, that tool is actually off by default. So, if you configure a cluster without specifying this pull interval, then the slaves will never bother contacting the master at all, and they’ll all hum along very happily but there will be no data being propagated around.
So be sure to configure this HA pull interval to ensure your data stays in sync.
We also have this tx_push_factor which best-efforts attempts to push transactions out to one or more slaves at the point when we’re writing to the master.
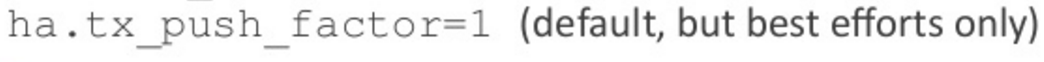
This setting is on by default, and it’s on with an initial value of one. So whenever we write to the master the master will try and contact one other instance in the cluster and push that transaction across at that point in time.
However, this approach is not the most thoroughly robust way of ensuring the most transactions are propagated. This push transaction is best-efforts only and will not signal back to the client the fact that perhaps it couldn’t contact other instances at that point in time.
So you should always be specifying the pull interval, but the push factor actually gives you the option to push data out more quickly than the pull-in tool would allow.
Tuning
Of the things that I’ve pointed out so far, probably the most important is this heartbeat timeout.
All of your Neo4j instances are sending heartbeats. By default, they’re sending heartbeats every five seconds.
We recommend you always configure the heartbeat timeout value at twice the heartbeat value plus a little extra. So if you’re sending heartbeats every five seconds, the default value for the timeout should be eleven seconds.
If an instance doesn’t hear a heartbeat from some other member after eleven seconds (in this case), then it starts suspecting that member. If that member being suspected is the master, then this could potentially trigger a master reelection.
If you find that you’re suffering frequent master reelections, and you see messages that log that some of these heartbeats are being sent after five seconds or outside of that 11-second interval, then you might consider increasing that heartbeat timeout value.
The downside of increasing the timeout value is if a machine really does go offline, then you’re going to find out about it a lot later.
With our example setting, we’re going to find out if the machine is genuinely not available after 11 seconds. If we increase that heartbeat timeout value, that window is going to be extended.
HA endpoints and load balancing
Now you’ve got your Neo4j cluster up and running. You can then begin to interrogate the cluster to discover at any point in time who is currently the master and who are the slaves.
If you’re using the server version of the product, each instance that’s running exposes these three different HA endpoints (master, slave and available):
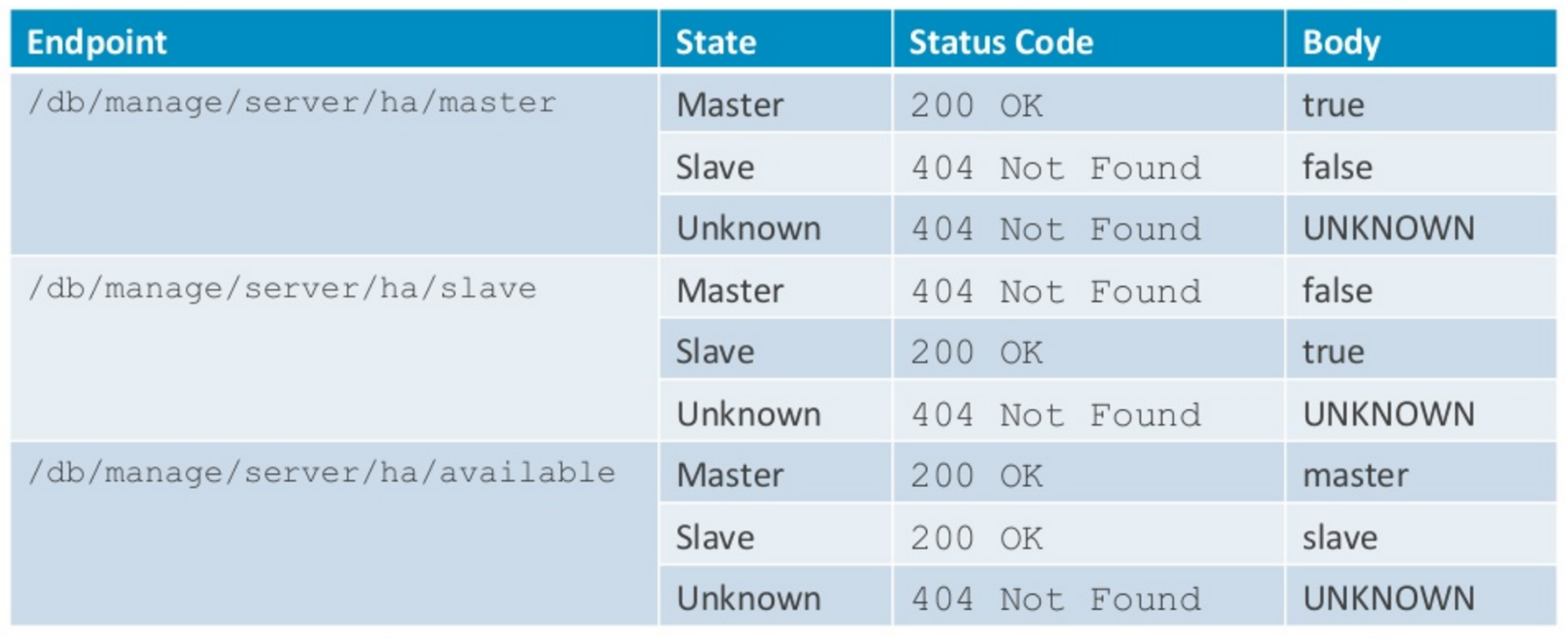
You can then issue an HTTP get request against each of the endpoints in order to discover if a machine is the master, is a slave or is it simply available?
This is very, very useful, particularly if you’re configuring a load balancer. If you want to route write directly to the master and then to round-robin read requests across the entire cluster, then we need to be polling each of the instances probably every couple of seconds to discover and remind ourselves who is the master.
In the graphic above, I’ve shown the HTTP status codes that each of these would return depending upon the state of that instance, and there’s a simple text body that’s included with every response as well (e.g., true, false, UNKNOWN).
Depending on the way you might configure a load balancer or any other application code that wants to use this, you can either use the status code or the entity body to infer the state of that particular instance.
In Neo4j 2.2, if you required authentication, then you also required authentication for these endpoints and that’s a good and proper thing to be requiring perhaps. At the same time, there’s a slight operational hurdle to overcome here: You end up having to configure your load balancers to authenticate against these endpoints as well.
In Neo4j 2.3, there is an additional configuration property here that allows us to switch off the authentication just for these HA endpoints.
Everything else will still be secured, but these HA endpoints can still be contacted without having to supply credentials. (The Neo4j team included this feature based on feedback from customers and users who preferred the simplicity of this model without having to configure their load balancers with credentials.)
High availability JMX endpoint
We can also discover some additional information about each instance using JMX (Java Management Extensions). Neo4j exposes a lot of internal counters and a lot of internal state by JMX.
Neo4j also exposes some of that JMX information at certain URIs. There are some URIs by way of which we can also gain some of that JMX information.
The most important one is this one here:
/db/manage/server/jmx/domain/org.neo4j/instance%3Dkernel%230%2Cname%3DHigh%20Availability
If we issue a get request against this URI, then we’ll get back a JSON document that describes this particular instance’s view of itself and its view of the rest of the cluster.
The kind of information that will be included here is:
- Am I alive?
- What particular role am I fulfilling at this point in time?
- Am I a master?
- Am I a slave?
- The last committed transaction ID for this particular instance
- This particular instance’s view of the rest of the cluster
These last two pieces of information are really, really useful when you build monitoring tools and you want to understand the state of your cluster. Let’s break both of them down.
First, the last committed transaction ID: As I said before, we’ve got all of the slaves pulling transactions from the master. The master is coordinating all the writes so therefore the master is responsible for assigning all of those transaction IDs.
If we’re in a very high-throughput scenario, there may be situations in which some of the slaves begin to drift a little behind the master and need to catch up, and we can identify that need by polling each of the instances in the cluster and comparing the last committed transaction IDs.
If we see the delta beginning to increase over time, then we can infer that one of those slaves or some of those instances are beginning to fall behind in their catch-up strategy.
Second, the instance’s view of the rest of the cluster: We can use this information in the JSON document to further reinforce our view of whether the cluster is stable and healthy.
If we poll all of the instances and they all agree that there’s one master and two slaves, and we see that in this additional information, then we can be doubly reassured that we’ve got a nice, healthy, stable cluster.
This HA JMX endpoint that we expose at the end of a URI is not well known, but it’s actually a very, very useful piece of additional monitoring information that we supply to you.
Configuring cross data center clusters
Many teams create cross data center clusters for failover purposes, but occasionally they want to have secondary parts of the cluster located close to some of their consumers elsewhere on the planet (especially if they have a globally available application).
If you’re building a cross data center cluster, our recommendation is that ideally you use a VPN. You need your cluster to be on the same subnet, and you need to ensure that the bandwidth between those data centers is aligned with the right throughput.
You need this bandwidth aligned both because you’re pushing transactions out from the master and also because all your slaves require significant transaction propagation when they contact the master. So you need to provision that bandwidth appropriately to ensure that you can actually get your data pretty fast between physical locations.
Another scenario: You might also have a cluster that spans multiple data centers where – if there’s a master reelection – the master could hop from one data center to the other, even though very often that’s not actually what you want.
What you really want is this: A primary data center where the core of your application is located and where, if there is a master reelection, you want to guarantee that it takes place within that data center.
In this case, your secondary data centers are effectively slave-only instances. They’re still all part of the same cluster, but you can configure instances in secondary data centers to have the slave-only property to be true.
Those secondary data center instances will only ever act in the role of a slave and – by setting this property – we effectively restrict master reelection to the instances in the primary data center.
Scaling horizontally for high read throughput
Once we’ve got our clustered Neo4j, we’re effectively scaling out the high read throughput.
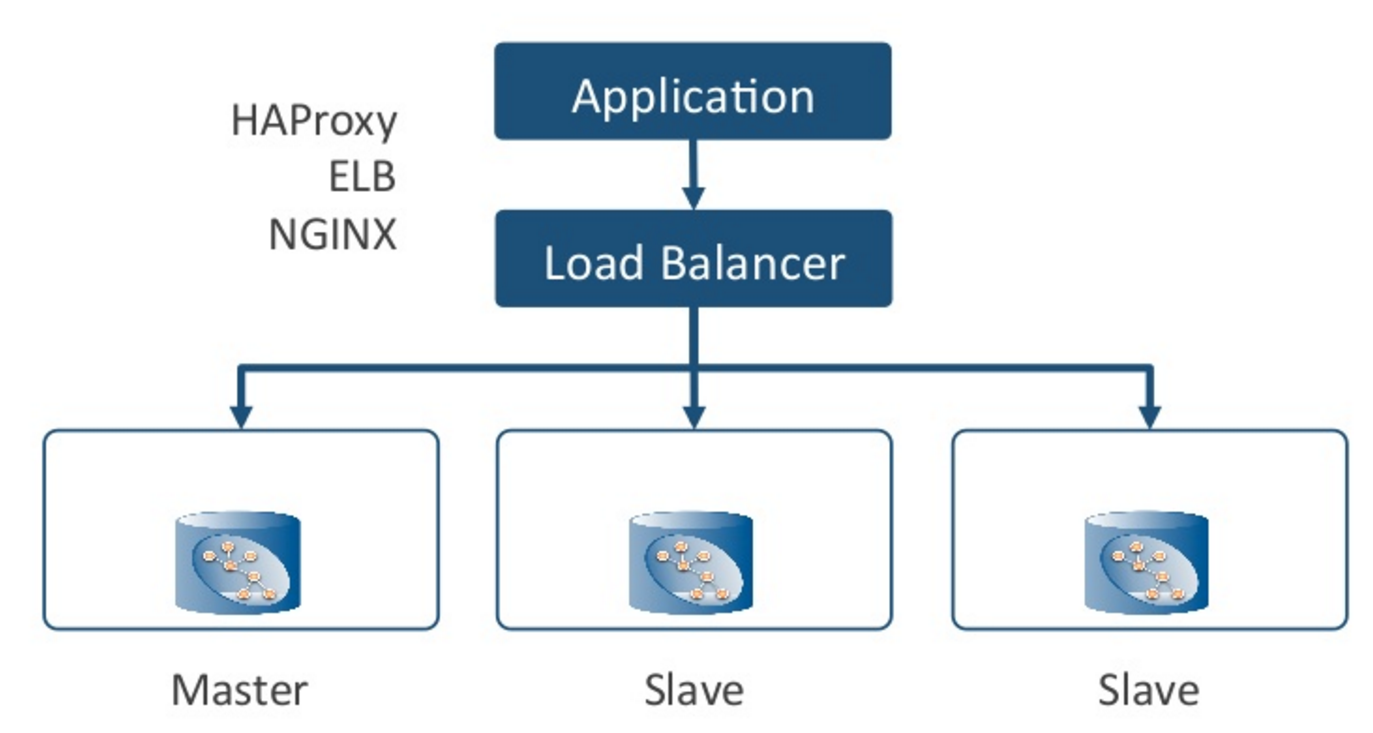
Pictured below is a typical application architecture where you’ve got the core of your own application code at the top, and then you’re talking to Neo4j using a client driver but inserting a load balancer in between, such as HAProxy, NGINX or Elastic Load Balancer (with Amazon).
An equivalent architecture would be one like this (below), with a pair of load balancers.
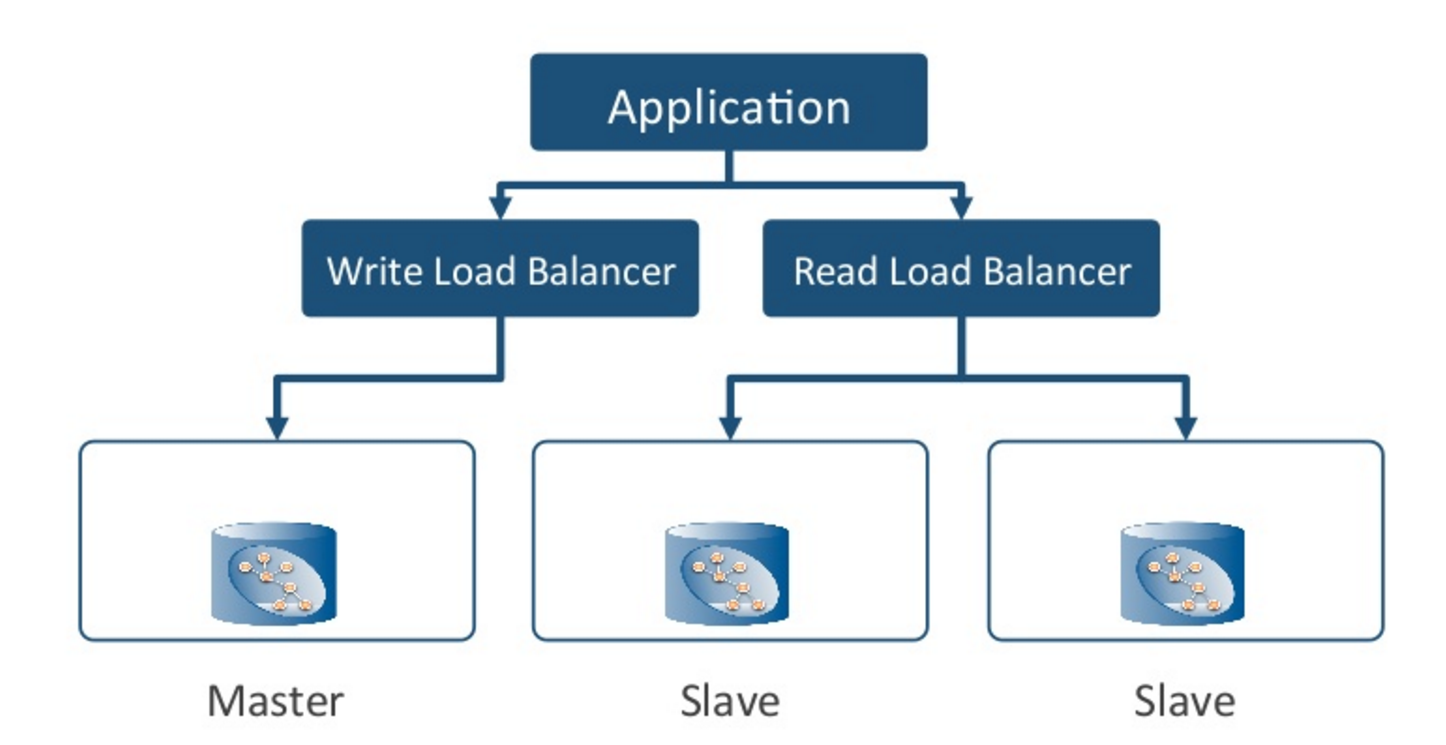
In this architecture, you’ve got one (logical) load balancer that is responsible for identifying the master, even if the master switches over time. The application will send all of its write requests to the write load balancer, and it will forward them directly to the master.
Then you have a second load balancer which is responsible for servicing read requests. That can either just load-balance across the slaves or it could actually round-robin across the entire cluster.
My colleague, Stefan Armbruster, has written a good blog post about how to configure HAProxy for doing some of these things I’ve already discussed. For time’s sake, I won’t go into all of these details, but there is a lot of rich information in Stefan’s post about identifying the master, routing writes to the master and load balancing reads across the rest of the cluster.
Load balancing and cache sharding
The advantage of using a load balancer is that we can employ a strategy called cache sharding. This is incredibly useful when you have a very, very large store.
Even though you may have a lot of RAM, for really large stores you’re never going to fit all of those stores into memory or into that page cache at any one point in time.
So what we want to be able to do is to reliably route requests to instances in the cluster where that page cache has been warmed with a portion of the graph that’s relevant to that particular query. Effectively, we’re using traditional consistent routing techniques in the load balancer between shorter requests consistently routed to specific instances in the cluster.
In this example pictured below, if we’ve got a read request matching country Australia, we will direct all of those countries beginning with A-I will go to instance one. Norway will go to instance two, Zambia to instance three.
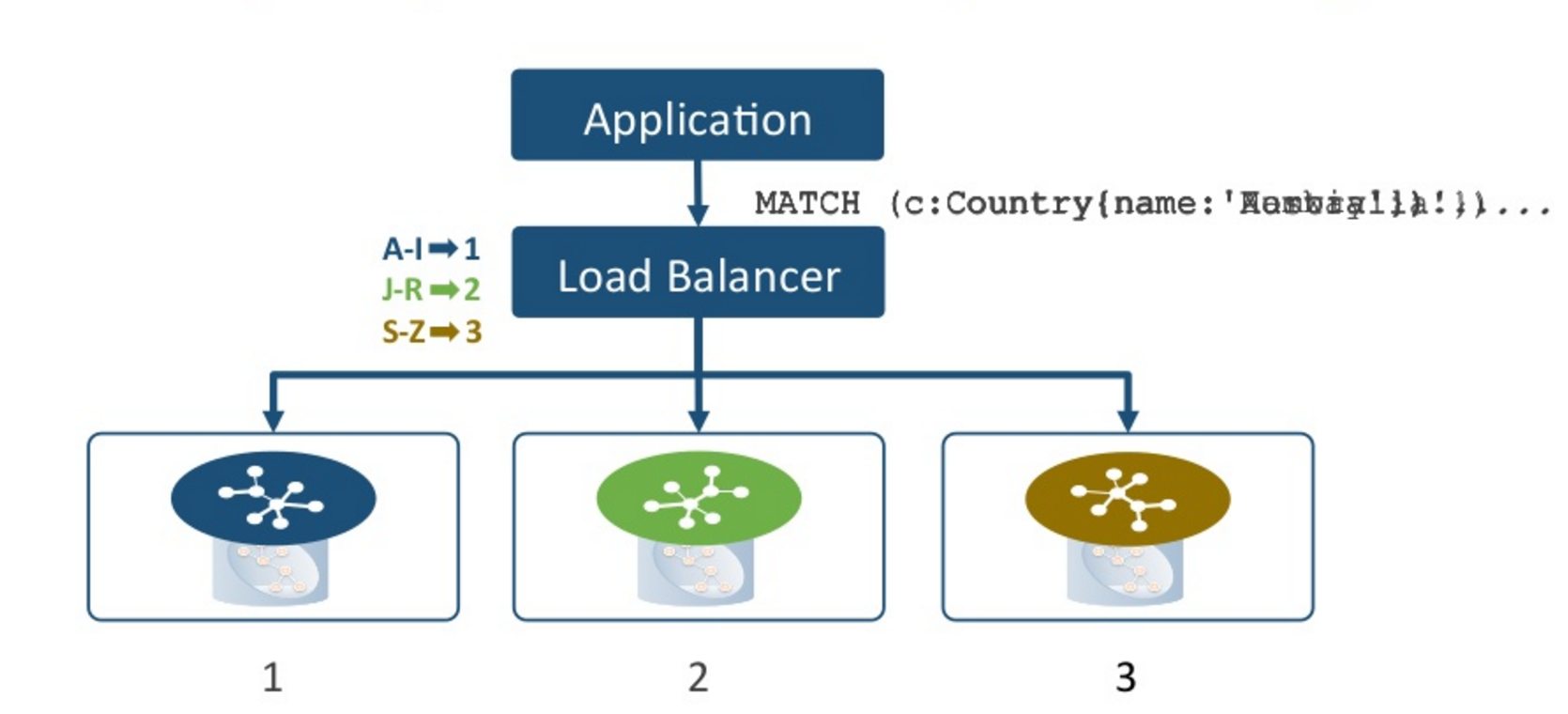
What’s happening here is that you’re consistently routing requests to specific instances in the cluster where that page cache has been warmed up with portions of the graph relevant to that particular part of the domain.
In order to make this work, you need to choose some domain-specific information or insert something into a header that will help you do that consistent routing. This practice provides an effective use of clustered Neo4j for servicing a very high read throughput scenario with a very large data store.
So that wraps up the use of clustered Neo4j and some of the strategies that we can employ when we’re using Neo4j High Availability.
Online backups with Neo4j
Now I’m going to talk about some of the operational activities that we’re going to want to do moving our apps into production. The first is backups.
Backup modes
Neo4j Enterprise supports online backups so you can backup a running instance without having to stop it, take it down or anything like that.
There are two kinds of backup. You can do a full backup and then, having got a full backup, you can do a series of incremental backups – so you do an incremental backup based upon some previous backup.
In order to be able to do an incremental backup, you need access to all of the logical logs that have been created since the last backup took place.
So typically you need to plan on keeping those logical logs for up to twice the backup interval. If you’re doing incremental backups every two hours, then you need to keep those logical logs for at least four hours.
By default, Neo4j Enterprise actually keeps logical logs for seven days. But if you’ve got a very high write throughput scenario, then it might be that you’re generating gigabytes of logical logs, and naturally, you might want to dial that down a bit.
But ultimately you need to ensure you’ve got sufficient logical logs in order to be able to do an incremental backup at any point in time.
Consistency check
Included with the backup tool is another one called the Consistency Check tool that will run by default every time you do a backup. It’s there just to check the health of the store and the health of the backup that it’s created.
We also expose this consistency check as a stand-alone tool so you can either run it as part of a backup or against a previous backup. Effectively, it’s purpose is to evaluate the store health.
But doing a consistency check can take quite a while. If you’ve got a really big store, then you’re looking at tens of hours or even perhaps a couple of days for several hundred gigabytes of data.
It may be that you don’t want to consistency check every single backup, and in that case, you can supply a verified false flag just to do the backup and not to do the health or consistency check.
Backup strategies
Nothing too surprising here.
You can do a local backup on the instance where the database is running, but we recommend that you do a remote backup.
Introduce another machine into your environment and then you just need the backup tool on that machine. You don’t need a running instance of Neo4j, you just need the backup tool, and that backup tool can do a remote backup from one of your instances in the cluster.
If you’re doing a consistency check, you’re effectively doing it offline with respect to the database, so the hard work is actually pulling all the data across in the first place. Once that’s done, the database just continues as normal, and we’re left doing the consistency check on the separate machine.
If you’ve got a large cluster, it may be that you assign one of those instances to be a dedicated backup slave so that you’re always targeting that particular instance for your backups.
An alternative strategy is to round-robin: Each time you do a new backup you pick another instance in the cluster so that you’re spreading the load over time.
In the long-running soak tests that we do, we typically have clusters of three or five instances with we have a separate machine elsewhere in our environment so we’re always doing remote backups.

We tend to round-robin across those instances and do a full backup followed by five incremental backups. So we do a full backup against A; an hour later perhaps, a full backup of B; full backup of C and so on.
Then, when we go back to A again, we’ll do an incremental backup. We’ll do that over and over until we’ve done five incremental backups of A. Then I’ll do a full backup again.
We’re always tracking the last successful backup because that one is effectively the backup that we would use to seed a new instance in the cluster – if necessary – to restore an instance in the cluster.
Restoring a backup
To restore from backup is simple.
A backup is a full copy of the store. If you need to ever restore from a backup, you stop a particular instance, you remove the old version of the store, you delete the graph DB directory, then you replace it with the backup and restart the instance.
That’s all that you have to do in order to be able to restart from the backup.
Monitoring your production environment
Let me talk very briefly about monitoring.
For years, we’ve exposed all those JMX counters, but in Neo4j 2.3, we’ve now starting exposing additional counters that we can push or that the database can publish. Today we support publishing to Graphite, Ganglia and to CSV files.
The kind of information that we’re capturing includes data about the node counts, entity counts, HA network usage, the page cache behavior, running or committed transitions and then some JVM-specific counters as well.
In our soak testing, we use those aforementioned metrics together with things like collectd to collect information about the system itself. We also tail messages.log looking for errors and warnings. We use those HA endpoints to determine who’s the master and who are the slaves. We look at the HTTP log to calculate the latencies on the server for each request. There are additional slow Cypher query logs that we can switch on.
Then, in our application itself or in our load generator, we’ll also have the client’s view of the behavior of the system, including the overall latencies as far as the client’s concerned.
Finally, we bring all of that stuff together in something like Graphite, so we have an internal and an external view of the system at the same time. We can then often correlate between the client starting to see some very, very large latencies here, or look at the behavior of the JVM over there, or the behavior of the page cache.
Testing your Neo4j app at scale
When you’re putting your app into production, for a long time beforehand, you should be testing at scale. This is exactly what we’re doing on your behalf, but we can’t anticipate all the different application architectures, all the different datasets or all the different kinds of queries, but we did our best.
Over the last six weeks before introducing Neo4j 2.3, we had up to 300 instances, often 30 or more clusters running in AWS for many, many days doing all of this kind of stuff, like running client workloads, very aggressively maxing out the instances, doing lots of operational things such as backups, replacing instances and doing some naughty stuff like killing instances and introducing partitions and stuff like that.
We did all this just to be confident that Neo4j remains stable over a long period of time. That’s exactly what we’d expect you to be doing as well when you’re putting this stuff into production.
This has been a very, very quick tour of moving Neo4j graphs to production at scale. I hope it’s been useful, but let me know if you have any questions.
Inspired by Ian’s talk? Register for GraphConnect Europe on April 26, 2016 at for more industry-leading presentations and workshops on the evolving world of graph database technology.
Share Article



Explore
Related Articles

A workbench for teams to query, explore, and visualize graph data

1 of 3: The difference between a graph, a knowledge graph, and a context graph

2 of 3: Why graphs, knowledge graphs, and context graphs matter to customers

3 of 3: The graph ecosystem: Bringing connected context to enterprise AI

Digital twins that learn: connected asset intelligence with Neo4j and Databricks
