
Insider Guide to Graph Data Science: First, a Brief Overview


5 min read

What does the insider’s guide to graph data science (GDS) entail?
We like to think of it as all the really cool stuff in GDS that’s not the algorithms – what tips and tricks GDS pros need to know.
During this blog series, we’ll cover a variety of topics, from memory management to transforming your graph, as well as what’s in the graph catalog that lets you reshape your transactional database to the right subset of data you want to run algorithms on. We’ll discuss RBAC integration for fine-grained security that we just rolled out in GDS 1.3, algorithm tuning and graph versioning using graph export.
We’ll also explain the tiers of graph algorithms and the alpha tier for early access to new features, with a sneak peak of some graph embeddings.
Lastly, we’ll talk you through running your own algorithms and writing your own algorithms using the Pregel API in Java.
This post provides a quick overview of the capabilities of the Graph Data Science™ Library, Neo4j’s products to support your data science journey, and an overview of some of the updates and changes we’ve made to algorithms over the last few releases.
Background on the Graph Data Science Library
Before we jump into GDS Library pro tips, we want to give some background on graph data science.
If you’re wondering why you’d use graphs with machine learning (ML) for analytics in the first place, the very easy answer is you can get better predictions with the data you already have.
We often hear data scientists say, “If I just had more data, then I could improve my predictive lift.” But the thing is, you already have more data – they’re called relationships, and they’re already hiding in your data sets.
A lot of current data science approaches tend to ignore the connections between data points, and the extended topology of that network – which can actually be very predictive.
By explicitly incorporating relationships, and adding structural information into your data, you can significantly boost results. Including predictive “graphy” features to your machine learning models, or whatever forecasting you might be doing, help you answer questions that you otherwise couldn’t – because you’re not actually using the relationships.
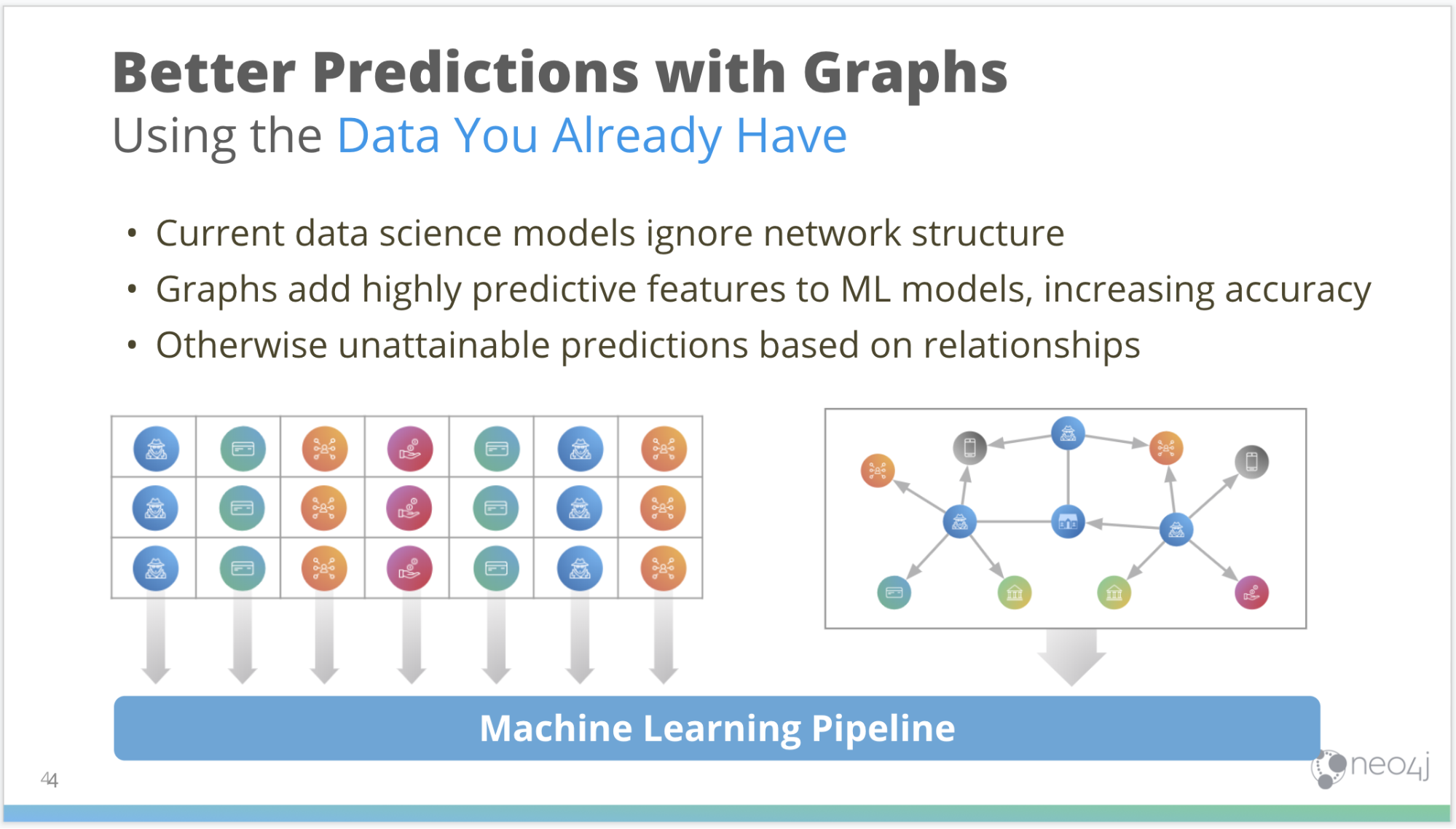
One important thing to say is that we’re not asking you to throw out what you’re already doing.
The nice thing about graphs, and in particular graph-feature engineering, is you can add it to your current analytics and ML pipelines. So keep doing what you’re doing – but add in those relationships as well.
How does Neo4j help me do graph data science?
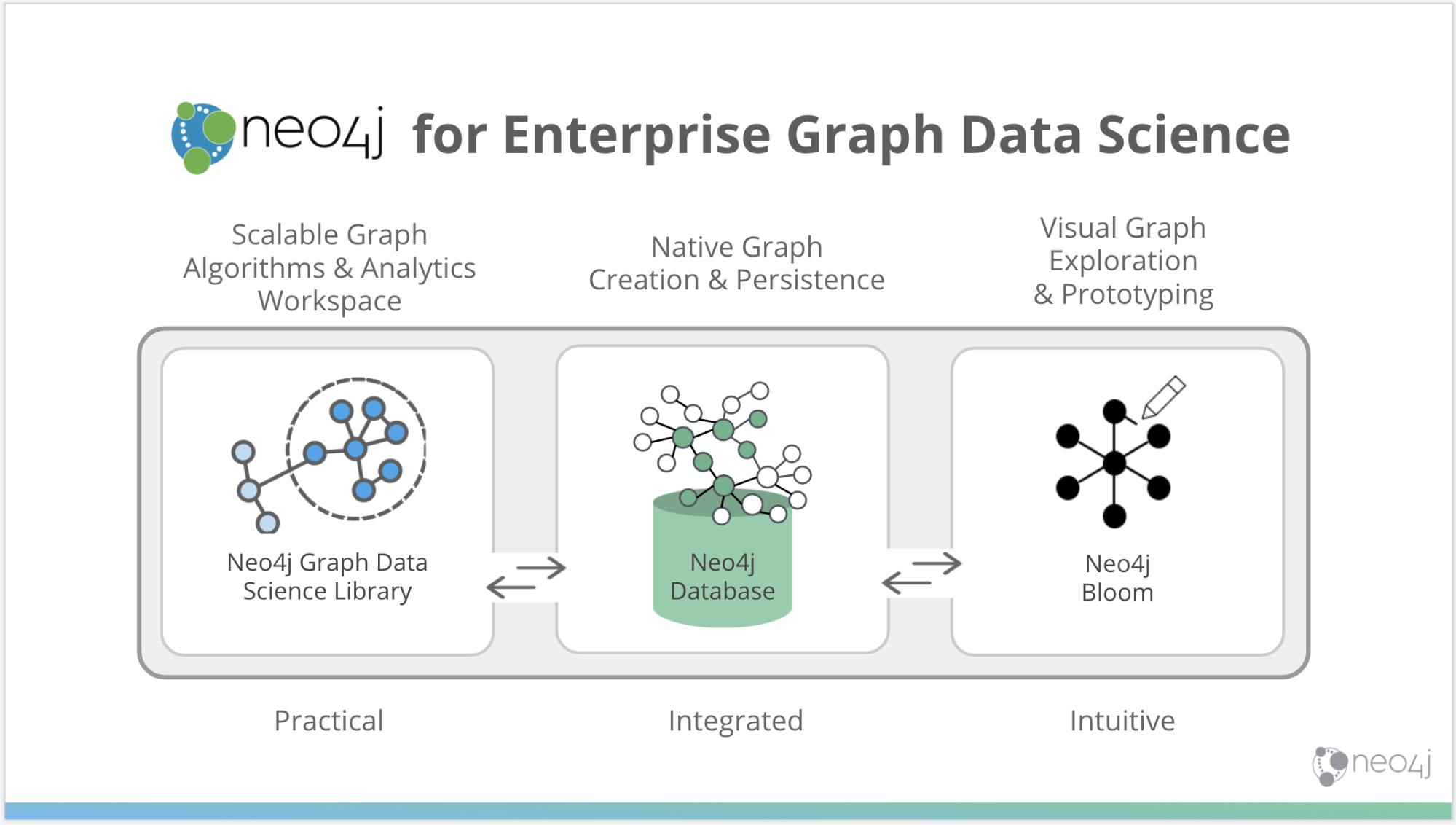
Neo4j is the leading enterprise graph database – a scalable, secure and performant system to store your connected data. But Neo4j is also the industry’s largest dedicated investment in graphs. What does that mean for you? We offer practitioners not only a database, but other dedicated products to democratize graph data science.
- Neo4j Graph Database
Store your connected data in a persistent graph database, and make it easy to store and retrieve data science results. - Graph Data Science Library
A plugin that provides an analytics workspace and over 50 algorithms. - Neo4j Bloom
Neo4j’s data visualization and exploration tool.
When you’re doing graph data science, it’s not just the algorithms. You need somewhere to store your graph data in the right shape (a database). And data scientists have to be able to visually explore their findings and explain that to their line of business or their subject matter experts – so a visualization tool like Bloom is critical.
Taken together, Neo4j provides a complete tool set of what you need to do graph data science.

What’s in the Graph Data Science Library?
The GDS Library provides the infrastructure to create your in-memory graph (the analytics workspace), as well as over 50 graph algorithms.
These algorithms range from path finding and centrality to community detection and link prediction. We have many algorithms to help you understand the topology and compute metrics of your graph. These algorithms are very parallelized, so you’re able to perform and scale to 10s of billions of nodes.
We’ve been very impressed with all the work that the Neo4j engineering team has done to make GDS as scalable as possible. The Neo4j database has a native graph storage that is very compact, and works really well for data storage and transactional workloads.
Our engineering team has created an analytics workspace that automatically transforms a transactional graph into a computational graph that has been optimized for large global aggregations and traversals.
The in-memory workspace allows you to do things like reshape your graph, or subset it, and layer on different graph algorithms before ever writing back results. Then, when you’re ready, you can update your underlying database or export results to a completely new database.
If you haven’t upgraded to the latest GDS Library, you’ll definitely want to take a look at the new capabilities. Recent additions to the GDS Library include new and improved algorithms, expressive and performance in-memory graph and advanced feature support.
New GDS Library Additions
Now that we’ve covered the background information: What’s new?
New Algorithms
We’ve added seven new algorithms since our 1.0 release, including a whole new category: graph embeddings. In addition, we’ve added new features to existing algorithms, such as seeding for consistency, distribution statistics and consecutive community IDs.
More Expressive In-Memory Graph Capabilities
We’ve also added in more expressive features that allow for better performance and expressivity with the in-memory graph. This includes mutability (updating the in-memory graph), advanced capabilities for combining and transforming properties, and new ways to query and interact with the data in your in-memory graph.
We’ve also added performance optimizations to our graph loaders (to make your data transformations faster) and improved compression to minimize the memory footprint of the analytics workspace.
Advanced Features and Database Integration
Finally, there are some general advanced features that we’ve added to improve how the GDS Library works with the core database. Those include support for role-based access to security and support for Neo4j.
We’ve also added improved memory management to prevent users from accidentally crashing their database when they haven’t configured it correctly. We’ve also added the Pregel API for implementing your own algorithms.
Conclusion
This is a super fast summary of what’s been added recently, and we’ll go into greater detail with a future blog in this series.
In the second installment of this blog series on graph data science, we’ll discuss insider tips and tricks like verifying memory needs with estimation functions, transforming and reshaping your graph with the graph loaders and applying fine-grained security with RBAC.
Share Article



Explore
Related Articles

What Are the Different Types of Graph Algorithms & When to Use Them?



Turning Your Tabular Data Into a Graph Using Cypher

Mix and Batch: A Technique for Fast, Parallel Relationship Loading in Neo4j
