APOC: An introduction to user-defined procedures and APOC

Head of Product Innovation & Developer Strategy, Neo4j
14 min read

This is the first in a series of blog posts in which I want to introduce you to Neo4j‘s user defined procedures and the APOC procedure library in particular.
Besides many other cool things, of the best features of our recent Neo4j 3.0 release were callable procedures.
Built-in procedures
There are a number of built-in procedures, that currently provide database management and introspection functionalities. Going forward, more functionality will be provided through these procedures (e.g., user management and security, transaction management and more).
But even more interesting than the built-in procedures are “User-Defined Procedures.” You might know them from other databases as “Stored Procedures” or “User-Defined Functions/Views.”
Essentially they are a way to extend the given query language, in our case Cypher, with custom functionality that adds new capabilities.
Calling procedures
You can call procedures stand-alone as a singular statements, or as part of your more complex Cypher statement.
Procedures can be called with parameters, and their return values are a stream of columns of data.
Here are two examples:
Call a procedure as only content of a statement
CALL db.labels();
| label |
|---|
|
Movie |
|
Person |
If you call a procedure as part of a Cypher statement you can pass in not only literal parameter values (strings, numbers, maps, lists, etc.), but also nodes, relationships and paths. This enables a procedure to execute graph operations from simple neighborhood expansions to complex iterative algorithms. For the result columns that are returned by a procedure, you have to use the YIELD keyword to select which of those are introduced and potentially aliased into the query.
Call a procedure as part of a more complex statement – list procedures grouped by package
CALL dbms.procedures() YIELD name RETURN head(split(name,".")) as package, count(*), collect(name) as procedures;
| package | count(*) | procedures |
|---|---|---|
|
db |
5 |
[db.constraints, db.indexes, db.labels, db.propertyKeys, db.relationshipTypes] |
|
dbms |
4 |
[dbms.changePassword, dbms.components, dbms.procedures, dbms.queryJmx] |
|
apoc |
203 |
[apoc.algo.aStar, apoc.algo.aStarConfig, apoc.algo.allSimplePaths, … ] |
When and how to write a procedure
Procedures can be small, generic helper functions for common tasks, but also very specific solutions and additions to your specific use case.
So consider them when:
-
Cypher lacks a feature that you really need (but make sure to consult the documentation and ask in our public Discord first) or
-
You need that last little bit of performance for a graph algorithm or operation where you can’t afford any indirection between your code and the database core.
Only then should you consider writing a user-defined procedure.
Writing a user-defined procedure is pretty straightforward in most programming languages on the JVM.
You just need to create an method annotated with @Procedure that takes in any of the Cypher types as named parameters and returns a stream of data transfer objects (DTOs) each of whose fields becomes a column in the procedure output.
One very simple procedure that I also used before to explain this feature is providing the capability to generate UUIDs. As you probably know, that’s something very easy to do in Java, but not so much in Cypher, and still sometimes you want to add uniquely identifying IDs to your nodes.
In our example, we will provide the uuid procedure with a number which indicates how many UUIDS we’re interested in. Note that the only numeric types supported by Cypher are long and double which encompass their smaller size brethren.
For our results, we use a dedicated Java DTO, that contains our two result columns as public final fields.
As a fun side-effect of using Neo4j procedures, you also get to play with Java 8 streams, but please don’t overdo it.
@Procedure("example.uuid")
public Stream<UuidResult> uuid(@Name("count") long count) {
return LongStream.range(0,count)
.mapToObj(row -> new UuidResult(row, UUID.randomUUID()));
}
static class UuidResult {
public final long row;
public final String uuid;
UuidResult(long row, UUID uuid) {
this.row = row;
this.uuid = uuid.toString();
}
}
We then use our favorite build tool (gradle, maven, sbt, etc.) to package our procedure as a jar and put it into the $NEO4J_HOME/plugins directory. Please make sure that all dependencies also become part of that jar, otherwise they won’t be found when your procedure is loaded.
And mark the Neo4j dependencies (and other libraries that are already within the Neo4j distribution) as provided so that they are not packaged with and blow up the size your procedure jar.
After restarting your server, your procedure should be listed when you CALL dbms.procedures(). If not please check $NEO4J_HOME/logs/debug.log.
Now we can call our newly minted procedure to create nodes with UUIDs.
WITH {data} as rows
CALL example.uuid(size(rows)) YIELD row, uuid
CREATE (p:Person {id:uuid}) SET p += rows[row]
RETURN row, p;
We provide detailed documentation on how to do it in our Developer’s Manual and in an example project on GitHub that is ready for you to fork and adapt.
APOC
While Neo4j 3.0 was maturing, I pondered about all the questions and feature requests I’ve gotten over the years regarding certain functionality in Cypher, and I felt that it was a good idea to create a generally usable library of procedures that covered these aspects and more.
Drawing from the unlucky technician in The Matrix movie and the historic Neo4j acronym “A Package Of Components,” the name APOC was an obvious choice, which also stands for “Awesome Procedures On Cypher”. So the hardest part of all the work was done.
Starting with a small selection of procedures from various areas, the APOC library grew quickly and already had 100 entries for the Neo4j 3.0 release and now contains more than 200 procedures from all these areas:
- Graph algorithms
- Metadata
- Manual indexes and relationship indexes
- Full text search
- Integration with other databases like MongoDB, ElasticSearch, Cassandra and relational databases
- Loading of XML and JSON from APIs and files
- Collection and map utilities
- Date and time functions
- String and text functions
- Import and export
- Concurrent and batched Cypher execution
- Spatial functions
- Path expansion
In this blog series, I want to focus on each of these above-mentioned areas with a specific blog post, but today I just want to mention a few of the procedures to excite you about what’s to come.
Installation
Just download the APOC jar file from the latest release on GitHub and put it into $NEO4J_HOME/plugins directory.
After restarting your Neo4j server, a lot of new procedures should be listed in CALL dbms.procedures().
You can also CALL apoc.help("apoc") or CALL apoc.help("apoc.algo") for the help function built into the library.
If you want to use any of the database integrations (e.g., for relational databases, Cassandra or MongoDB), make sure to add the relevant jar files for the drivers for those databases too. It’s probably easiest to clone the repository and run mvn dependency:copy-dependencies to find the relevant jars in the target/dependency folder.
Many of the APOC procedures just return a single value which is of the expected return type and can be aliased. Some of them act like Boolean filters, i.e., if a certain condition does not match (e.g., isType or contains) they just return no row, otherwise they return a single row of “nothing”, so no YIELD is needed.
As there are no named procedure parameters yet, some APOC procedures take a configuration map which can be used to control the behavior of the procedure.
apoc.meta.graph

One very handy feature are the metadata capabilities of APOC. Being a schema-free database, you probably wondered in the past, what the underlying graph structure looks like.
The apoc.meta.* package offers procedures that analyze the actual content or database statistics of your graph and return a meta graph representation.
The simplest procedure, apoc.meta.graph, just iterates over the graph and records relationship-types between node labels as it goes along. Other more advanced procedures either sample the graph or use the database statistics to do their job.
The visual metadata procedures return virtual nodes and relationships which don’t exist in the graph but are returned correctly to the Neo4j Browser and client, and are rendered just like normal graph nodes and relationships. Those virtual graph entities can also be used by you to represent an aggregated projection of the original graph data.
apoc.load.json
Loading data from web and other APIs has been been a favorite past time of mine.
With apoc.load.json, it’s now very easy to load JSON data from any file or URL.
If the result is a JSON object, it is returned as a singular map. Otherwise, if it is an array, it is turned into a stream of maps. Let’s take the Stack Overflow example linked above.
The URL for retrieving the last questions and answers of the Neo4j tag is this:
Now it can be used from within Cypher directly, let’s first introspect the data that is returned.
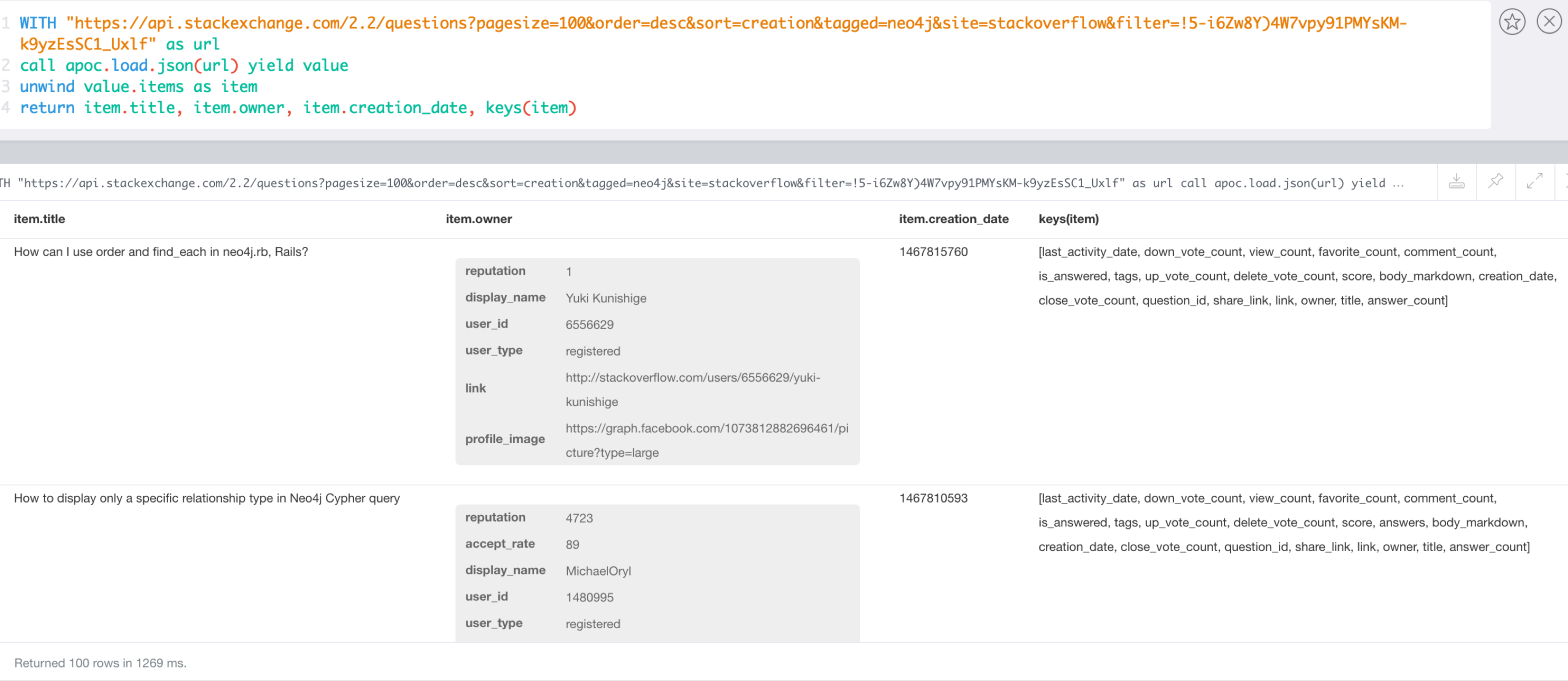
JSON data from Stack Overflow
WITH "https://api.stackexchange.com/2.2/questions?pagesize=100&order=desc&sort=creation&tagged=neo4j&site=stackoverflow&filter=!5-i6Zw8Y)4W7vpy91PMYsKM-k9yzEsSC1_Uxlf" AS url CALL apoc.load.json(url) YIELD value UNWIND value.items AS item RETURN item.title, item.owner, item.creation_date, keys(item)
Combined with the Cypher query from the other blog post, it’s easy to create the full Neo4j graph of those entities.
Graph data created via loading JSON from Stack Overflow
WITH "https://api.stackexchange.com/2.2/questions?pagesize=100&order=desc&sort=creation&tagged=neo4j&site=stackoverflow&filter=!5-i6Zw8Y)4W7vpy91PMYsKM-k9yzEsSC1_Uxlf" AS url
CALL apoc.load.json(url) YIELD value
UNWIND value.items AS q
MERGE (question:Question {id:q.question_id}) ON CREATE
SET question.title = q.title, question.share_link = q.share_link, question.favorite_count = q.favorite_count
MERGE (owner:User {id:q.owner.user_id}) ON CREATE SET owner.display_name = q.owner.display_name
MERGE (owner)-[:ASKED]->(question)
FOREACH (tagName IN q.tags | MERGE (tag:Tag {name:tagName}) MERGE (question)-[:TAGGED]->(tag))
FOREACH (a IN q.answers |
MERGE (question)<-[:ANSWERS]-(answer:Answer {id:a.answer_id})
MERGE (answerer:User {id:a.owner.user_id}) ON CREATE SET answerer.display_name = a.owner.display_name
MERGE (answer)<-[:PROVIDED]-(answerer)
)

The documentation also contains other examples, like loading from Twitter and Geocoding.
apoc.coll.* and apoc.map.*
While Cypher sports more collection and data structure operations that most other query languages, there is always that one thing you couldn’t do yet. Until now.
With procedures it is easy to provide solutions for these missing pieces, oftentimes just a one-liner in the procedure. That’s why APOC contains a lot of these utility functions for creating, manipulating, converting and operating on data.
Here are two examples:
Creatings pairs of a list of nodes or relationships can be used to compare them pair-wise, without a double loop around over an index value.
Create a list of pairs from a single list
WITH range(1,5) as numbers CALL apoc.coll.pairs(numbers) YIELD value RETURN value
|
value |
|
[[1,2],[2,3],[3,4],[4,5],[5,null]] |
Currently you can’t create a map from raw data in Cypher, only literal maps are supported and the properties() function on nodes and relationships. That’s why APOC has a number of convenience functions to create and modify maps based on data from any source.
Create a map from pairs of data
WITH [["Stark","Winter is coming"],["Baratheon","Ours is the fury"],["Targaryen","Fire and blood"],
["Lannister","Hear me roar"]] as pairs
CALL apoc.map.fromPairs(pairs) YIELD value as houses
RETURN houses
|
houses |
|
{Stark:”Winter is coming”, Baratheon:”Ours is the fury”, Targaryen:”Fire and blood”, Lannister:”Hear me roar”} |
apoc.date.* – Date and time functions
Converting between numeric time information and its string counterparts can be cumbersome.
APOC provides a number of flexible conversion procedures between the two:
CALL apoc.date.format(timestamp(),"ms","dd.MM.yyyy")
// -> 07.07.2016
CALL apoc.date.parse("13.01.1975 19:00","s","dd.MM.yyyy HH:mm")
// -> 158871600
More details can be found in the documentation.
apoc.export.cypher*
Exporting your database with the dump command that’s built into neo4j-shell generates a single large CREATE statement and has a hard time dealing with large databases.
Using the original export code I wrote a few years ago, the apoc.export.cypher* procedures can export your graph data to a file with Cypher statements. The graph data to be exported can be:
- The whole database
- Collections of nodes of relationships
- Results of a Cypher statement
The procedure first writes commands to create constraints and indexes. Nodes and relationships are created in singular Cypher statements, batched in transactional blocks.
For node lookup, it uses constrained properties on a label (kind of a primary key) if they exist. Otherwise it adds a temporary, artificial label and property (the node-id) which are cleaned up at the end.
Export Full Database
CALL apoc.export.cypherAll('/tmp/stackoverflow.cypher', {})
Export Specific Nodes and Relationships
MATCH (q:Question)-[r:TAGGED]->(t:Tag)
WITH collect(q) + collect(t) as n, collect(r) as r
CALL apoc.export.cypherData(n, r, '/tmp/stackoverflow.cypher', {batchSize:1000})
YIELD nodes, relationships, properties, time
RETURN nodes, relationships, properties, time
Export From Statement
CALL apoc.export.cypherQuery('MATCH (:Question)-[r:TAGGED]->(:Tag) RETURN r',
'/tmp/stackoverflow.cypher', {nodesOfRelationships: true})
╒═════════════════════════╤════════════════════════════════╤══════╤═════╤═════════════╤══════════╤════╕ │file │source │format│nodes│relationships│properties│time│ ╞═════════════════════════╪════════════════════════════════╪══════╪═════╪═════════════╪══════════╪════╡ │/tmp/stackoverflow.cypher│statement: nodes(181), rels(283)│cypher│181 │283 │481 │25 │ └─────────────────────────┴────────────────────────────────┴──────┴─────┴─────────────┴──────────┴────┘
Resulting Export File
begin
CREATE (:`Question` {`id`:38226745, `favorite_count`:0, `share_link`:"https://stackoverflow.com/q/38226745",
`title`:"How can I use order and find_each in neo4j.rb, Rails?"});
...
CREATE (:`Question` {`id`:38038019, `favorite_count`:0, `share_link`:"https://stackoverflow.com/q/38038019",
`title`:"Convert neo4j Integer object to JavaScript integer"});
CREATE (:`Tag`:`UNIQUE IMPORT LABEL` {`name`:"ruby-on-rails", `UNIQUE IMPORT ID`:500});
...
CREATE (:`Tag`:`UNIQUE IMPORT LABEL` {`name`:"fuzzy-search", `UNIQUE IMPORT ID`:580});
commit
begin
CREATE INDEX ON :`Tag`(`name`);
CREATE CONSTRAINT ON (node:`Question`) ASSERT node.`id` IS UNIQUE;
CREATE CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT node.`UNIQUE IMPORT ID` IS UNIQUE;
commit
schema await
begin
MATCH (n1:`Question`{`id`:38226745}), (n2:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`:500}) CREATE (n1)-[:`TAGGED`]->(n2);
...
MATCH (n1:`Question`{`id`:38038019}), (n2:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`:532}) CREATE (n1)-[:`TAGGED`]->(n2);
MATCH (n1:`Question`{`id`:38038019}), (n2:`UNIQUE IMPORT LABEL`{`UNIQUE IMPORT ID`:501}) CREATE (n1)-[:`TAGGED`]->(n2);
commit
begin
MATCH (n:`UNIQUE IMPORT LABEL`) WITH n LIMIT 20000 REMOVE n:`UNIQUE IMPORT LABEL` REMOVE n.`UNIQUE IMPORT ID`;
commit
begin
DROP CONSTRAINT ON (node:`UNIQUE IMPORT LABEL`) ASSERT node.`UNIQUE IMPORT ID` IS UNIQUE;
commit
Conclusion
Even the journalists of the ICIJ used APOC as part of the browser guide they created for the downloadable Panama Papers Neo4j database. Really cool!
The next blog post in this series will cover data integration with APOC.
Please try out the procedures library, you can find it here on GitHub, and might find its documentation (WIP) helpful.
If you have any feedback or issues, please report them as GitHub issues.
I want to thank all the contributors that provided feedback, code and fixes to the library.
Want to take your Neo4j skills up a notch? Take our (newly revamped!) online training class, Neo4j in Production, and learn how scale the world’s leading graph database to unprecedented levels.
Catch up with the rest of the Introduction to APOC blog series:
Share Article



Explore
Related Articles

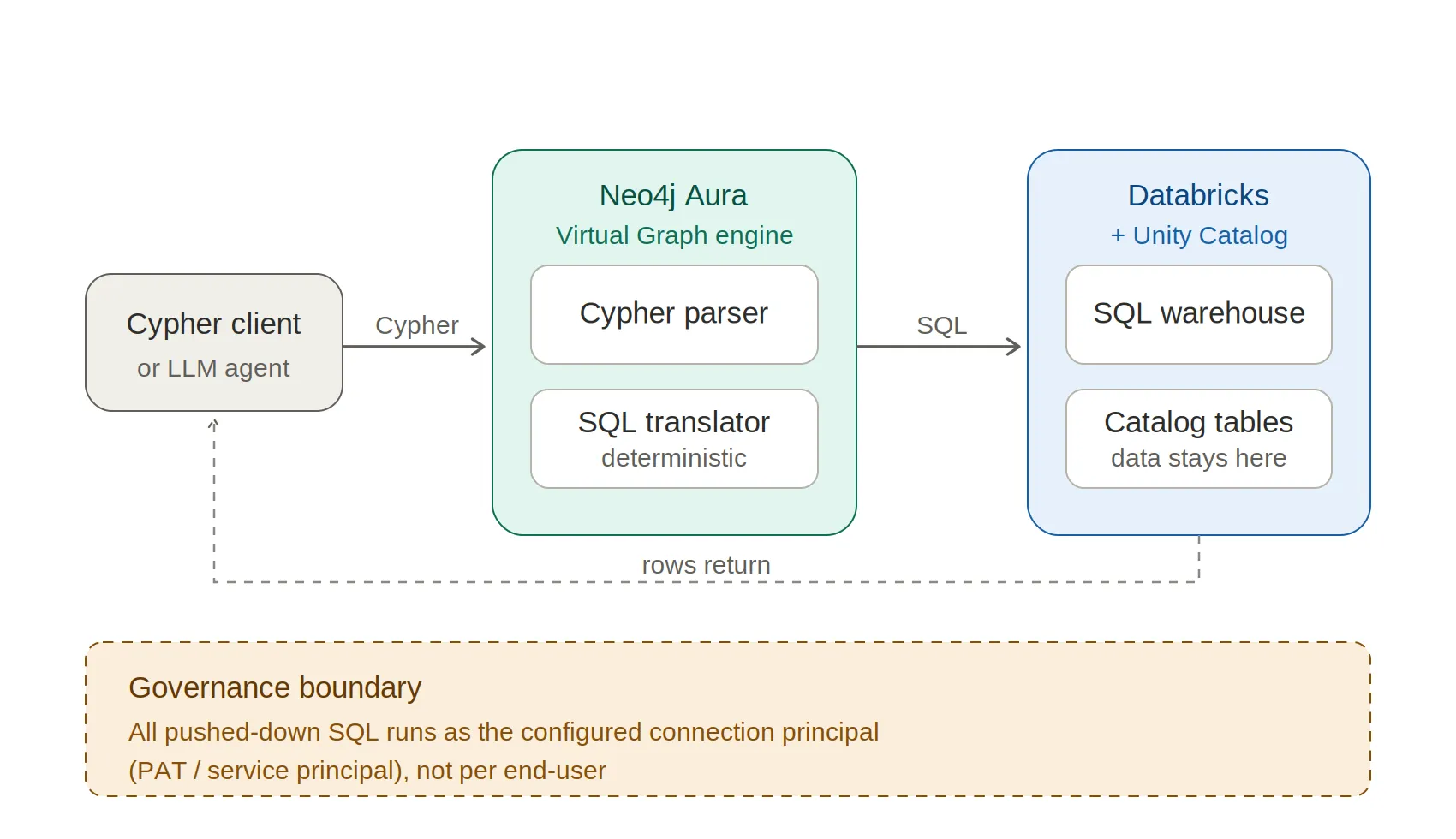
Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher




Zero-Copy Graph Reasoning on Snowflake: Getting Started With Neo4j Virtual Graph