Kafka for Neo4j AuraDB is available now

Senior Director of Developer Relations, Neo4j
7 min read
Neo4j recently released the Neo4j Connector for Apache Kafka, version 4.1. In this post, I’d like to cover some of the important changes and new functionality. Today, we’re announcing availability of the Kafka Connect Source approach, which allows you to produce data from Neo4j AuraDB to Kafka via Kafka Connect, and we are deprecating the database plugin of the same functionality.
These features are very important to support the growing customer base using Neo4j AuraDB. We’re pleased to announce these and to make sure that customers know that everything described in this post works with Neo4j AuraDB Enterprise and Professional, and also with Neo4j Enterprise Edition (self-managed), and even Neo4j Community.
Kafka Connect source
With version 4.1, the connector now supports a source connector that lets you produce the results of Cypher queries to any Kafka topic. This new functionality uses Kafka Connect, the tool for scalably and reliably streaming data between Apache Kafka and other data systems. It makes it simple to quickly define connectors that move large data sets into and out of Kafka.

This is important functionality, because up until recently, customers on Neo4j AuraDB could only use the Kafka Connect Sink – meaning that they could write data from Kafka to Neo4j AuraDB, but not the other way around. With this release, we’re enabling source connectivity so that Neo4j AuraDB users can have full bi-directional support to and from Kafka.
Use cases
Bi-directional communication with Kafka unlocks some powerful use cases, such as flexible fraud detection. We’d like to give you a taste with a real example, but it’s simply one example. Neo4j has been working with customers for years to build these types of architectures for recommendation and personalization systems, compliance systems, and more. The core value hasn’t changed, it’s just gotten easier to take advantage of, and to plug into the rest of a customer’s enterprise.
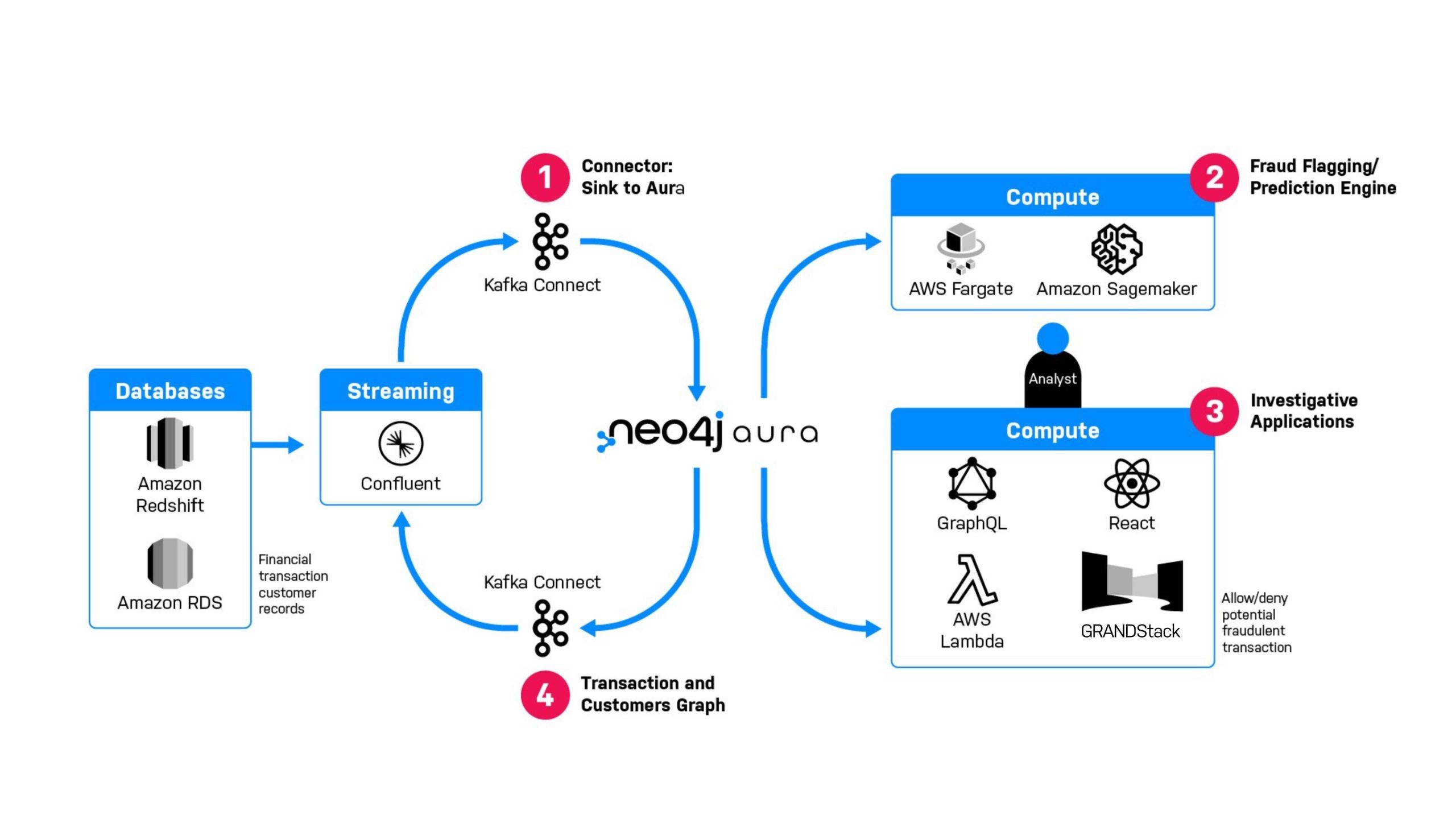
In this architecture, at step 1 we feed data from upstream systems into an AuraDB transactions and customers graph using the Neo4j Connector in sink mode. Because we now have that graph, we can use the full power of different connected data techniques, using any combination of Cypher analytic queries, bloom visualization, or even external platforms in step 2 to flag any transaction as potentially fraudulent.
In step 3, an application that utilizes the graph can present potentially fraudulent transactions to an analyst, who can block or allow certain financial transactions. Both the potentially fraudulent flagged transactions, and the final adjudication, can be produced back out to the streaming platform in step 4, to notify other systems in the enterprise to take other action on an account.
In effect, because we have this bi-directional support, we can add graph superpowers to any existing application that works with Kafka. The overall pattern allows any kind of data to be taken from Kafka, turned into a graph, substantial value added to that data using Neo4j’s core strengths, and produced back onto a different Kafka topic for use in other systems.
How it works
Following the pattern established by well-known other connectors in the Confluent ecosystem such as the JDBC connector, Neo4j’s Kafka Source Connector lets you define a polling query and interval. The connector handles fetching all data that has changed since the last poll, and producing all of the resulting information to the topic of your choice.
For example, if you configured your connector with:
neo4j.streaming.poll.interval.msec=5000
neo4j.streaming.property=lastUpdated
neo4j.source.query=MATCH (p:Person) WHERE p.lastUpdated > $lastCheck RETURN id(p) as id,p.name as name, p.lastUpdated as lastUpdated
topic=person
Then the connector would check Neo4j AuraDB every five seconds (5000 msec) for changes and produce those changes to the topic person. It’s important to note that this requires a property (such as lastUpdated), which is in the return query and indicates when a node changed – this permits the connector to produce only things that have changed since the last query. This pattern is similar to the “incremental query” based on a timestamp or incrementing integer found in other Kafka connectors.
A full installation and quick start example for Kafka Connect can be found in the documentation.
Deprecation of the Neo4j-Streams plugin
With the release of version 4.1 of the connector, we are deprecating the use of the Neo4j Database plugin – that is, the JAR file which is installed into the plugin’s directory of the database itself. The plugin will continue to be supported for customers who are already using it up to and including Neo4j Database version 4.3. For customers moving forward beyond 4.3 in the future, we will work with them to implement the Kafka Connect approach instead.
This does not mean any change today for any customer who is running the plugin and is happy with it, but it may mean change in the future when new releases of Neo4j Enterprise Edition come out, and so it’s important we take the time to describe the reasons why this transition makes sense.
Up until version 4.1 of the connector, the benefit of this plugin was that it provided bi-directional communication to Kafka, and some utility stored procedures, such as the ability to use Cypher to query the database and publish messages directly to any Kafka topic.
But this plugin came with a number of drawbacks and downsides:
- As it required a database plugin, this required customers to allocate extra heap memory and/or CPU for Kafka message processing that wasn’t best done inside of the database.
- As a plugin, it is harder to install, use, and configure in the context of Neo4j AuraDB, which is seeing increasing adoption, as the best managed service offering for graph.
- The plugin can be tricky to configure, particularly in dynamic situations where customers were creating or destroying Neo4j databases, or changing the cypher query they were using to publish data to a topic.
- The Neo4j plugin subsystem did not provide a monitoring approach. That meant that short of looking at the log files, it could be tricky to debug in complex scenarios.
With the introduction of Kafka Connect Source capability, we have a bi-directional Kafka integration which addresses those challenges, point by point:
- As Kafka Connect runs outside of the database, no extra heap memory planning is needed; to the database, Kafka Connect is like any other bolt client. This means that its connections, queries, and tasks can be managed as you would any other query workload.
- As no database plugin is required, the connect approach meshes quite nicely with Neo4j AuraDB.
- Kafka Connect already has a rich configuration system, including the use of REST APIs, that is even easier for Kafka pros to manage, as they typically have many other connectors they’re already using.
- Kafka Connect workers have a thought-out monitoring experience that is already well documented.
As a result, we are deprecating the plugin because we’ve found a better solution that is more future-proof, and benefits from the excellent work our partners at Confluent have put into the connect framework over time.
Where to get more information
The best place to find out more about this release is via the official documentation, which you can find here. You can also drop by the Neo4j Community Site to ask questions, or get in touch directly with your Neo4j representative.
Conclusion
If you are a Neo4j AuraDB customer, this release is great news. We’ve made bi-directional integration with Kafka possible using the Kafka Connect framework. You can get started today, whether you’re using AuraDB Free, Professional, or Enterprise.
If you are running Neo4j Enterprise Edition, you can do exactly the same. If you’re a customer running Neo4j 4.0, 4.1, or 4.2 and you’re using the database plugin directly, no change is required at this moment; the database plugin will continue to work and be supported by Neo4j. But it’s a good idea to have a look at the Kafka Connect approach we describe above, as future versions of Neo4j will require this approach for upgrades, due to the numerous advantages.
We’ve already seen customers build a variety of really cool applications using Neo4j AuraDB and Kafka together, and we can’t wait to see what you will build next.
Share Article



Explore
Related Articles
Introducing Document Intelligence: From documents to a knowledge graph, right inside Aura

Getting started with Neo4j Aura: A guide to the leading cloud graph database


Finding hidden bottlenecks in flight networks with Aura graph analytics on Databricks

Find impactful graph-powered insights in Databricks
