







Liberating Knowledge: Machine Learning Techniques with Neo4j



14 min read

Editor’s Note: This presentation was given by Rob Schley, Dr. Alessandro Negro and Christophe Willemsen at GraphConnect New York City in September 2018
Presentation Summary
Following a brief philosophical background by Rob Schley, we dive into Hume’s core by exploring their process behind turning data into real wisdom that inspires quantifiable change.
Dr. Alessandro Negro explains the steps of Hume’s process, which includes:
Then, we start to understand the main problem within this field – how do we best represent knowledge in a way that is both exhaustive and easy for the receiver to understand?
When we explore knowledge learning and construction, we begin to see the importance of quality and modeling. Christophe Willemsen explains how the way in which you model your knowledge affects the quality of the end results.
We have a multitude of tools to aid us in this endeavor as well, such as named-entity-recognition, entity and concept enrichment enrichment cleaning and topic modeling.
Finally, we take a closer look at Neo4j’s performance and how it has increased speed by three times.
Full Presentation
Rob Schley: The world is full of knowledgeable, insightful and incredibly wise people who have spent their entire lives – in some cases – learning, applying and refining their skills over time.
We all effectively possess the entire body of human knowledge, insight and wisdom.
Unfortunately, we don’t possess the technology to share our knowledge and wisdom with each other directly. For example, I can’t copy the things that are in my brain to your brain.
In order for us to share our knowledge, we have to communicate. And we’ve already invented countless ways to do so. We have gone from speech to written language to encyclopedias, books and radio to TV. We have accomplished all of this in order to share information about how the world works.
Humans are a creative species, but we didn’t do this just for fun, but rather because communication is hard. Communicating at scale is especially hard.
Information sharing is hard because we don’t have the same background or education. We don’t share the same experiences, perspectives or biases. And every time we do share, we always need to start from square one.
When we share information with each other, we actually reduce our knowledge. It gets degraded because we aren’t able to share with high fidelity. Our knowledge becomes a text document that is sent off to a publisher and put into a book. All of the nuance, detail and interconnectedness in our minds do not come through in those communication mediums.
So, what do we do?
It shouldn’t be so hard to share knowledge effectively. One day, I would like to possess the technology that allows me to copy the ideas in my mind and share them with someone else.
Until we get there, isn’t there something that we can do to take all this information and make it more accessible for people to use every day? This is the driving motivation behind Hume.
Hume is the culmination of two years of research and development. We believe Hume will dramatically impact how we interact, access and act upon information.
Alessandro Negro: I would like to start with this image below.

I like it because it shows the evolutionary path that transforms data into something different, something that contains much more insight and wisdom.
We have talked a lot in the last five years about data-driven application. Data in its original nature is useless because it doesn’t provide real value for a company.
Data on its own is sparse. It is distributed across many data silos and data sources and it is unstructured – a chaotic situation in which you cannot derive anything useful.
Converting, collecting and organizing data yields results. However, the information itself is useless compared to knowledge. Migrating from information to knowledge is a hard task, and requires a lot of effort since it represents a change in quality.
Knowledge is connected information, so you need to connect the dots between information in order to obtain knowledge.
Once you get to the knowledge, you can then assign meaning to your data. At this point, you finally receive insight and wisdom from your data. In this way, though starting with something relatively useless, you can achieve a situation in which you obtain real knowledge.
From wisdom, you can extract other knowledge. This method drives methods for your company to deliver better products, analyze your production chain or deliver improved service to your end user.
With this exact idea in mind, we have designed the Hume processing pipeline that you see below.
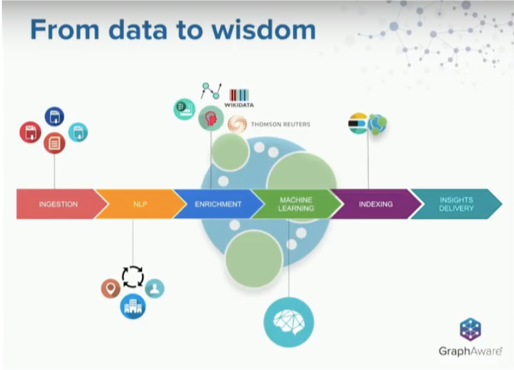
Here, you find the process of converting data, wherever you have it, into insight and wisdom. The next step involves learning from the data and drawing concrete action to benefit your company.
Collecting Data
The first step is collecting data from your data sources. Pre-process your data and start organizing it.
We will start with textual data. Textual data is generally considered unstructured data, but this is not true. Text has a lot of structure related to the relationship between words, grammar, lexicon, and the other constructs that are behind the text.
Extracting Data
For the second phase, you need to extract the hidden structure of your textual data and organize it so that a machine can process it.
However, this step alone is not enough. Sometimes, the data that you have is inadequate for making any kind of process. It also might not be the right set of data that is needed.
The enrichment process allows you to extend the knowledge that you have about your own business, thereby introducing external sources. This process allows you to gain more insight at the end of the process.
You can do this using external knowledge, and can even process the data that you already have in order to extract other knowledge.
Here’s an example.
Suppose you are analyzing different documents and can compute similarities between them. This is not outside of your knowledge; it’s already inside. You are just processing it to extract new information – the similarities between the documents.
Machine Learning
This process is useful for navigating your data. Once you have this knowledge, you have to store and manage it. You can start applying machine learning tools that will give you real insight about your data at the end of the process.
Indexing Data
You will also need to index your data, because you have to provide some kind of access to this data. At this point, you are ready to deliver insight.
Insight Delivery
Insight could entail a new kind of report for the managers or it could be a recommendation engine. It just has to relate to your initial data.
In this evolutionary path, there are two main problems, noted below.

The first problem that arises is the process of learning new knowledge itself. How are we going to construct knowledge based on the information that we gather from our data?
The second problem is how we will represent this knowledge.
Knowledge Learning and Construction
Those who work with machine learning know that representation is one of the biggest issues in the field. It’s one of the most complex and compelling tasks, especially since knowledge representation explains how information is organized. This has to be done so that an autonomous system can perform complex tasks on the knowledge.
In this way, the means in which you model your knowledge affects the quality of your end results.
In Hume, we decided to use the broader concept of a knowledge graph as a way to represent knowledge. We consider the knowledge graph as just as a way to represent RDF in a property graph.
We consider the knowledge graph as a set of interconnected entities with their related properties. At the end, we come up with a way to represent different types of relationships between items in the information.
This idea corresponds with a previous image, shown again below.

The knowledge is just connected dots that give meaning to your information.
In this evolutionary path, the knowledge graph plays a very important role because it represents the core of the artificial intelligence (AI) enabled path. All of what we build on top of our knowledge will happen on top of our knowledge graph.
So, this is where the fun part comes in – creating this knowledge graph. As you can see in the diagram below, our idea is to have a knowledge graph that starts just from the information that you can retrieve from your textual or structured data. Then, we will grow this knowledge graph at each process.
This is an iterative process, and what you receive in return can be used in different ways. You can export a vector. There are also various ways to process this vector using other machine learning tools.
You can also export a different type of document that offers views of the same set of knowledge that you have. Storing them in elastic search provides an enterprise search engine or semantic search.
Visualizing data gives people a better understanding of the set they are looking at. Since you will have already connected the dots for them, they can go over your dataset and see things that other machine learning tools cannot provide.
At the end, let’s say we see a graph like the one below.

This is a very simplified version. However, it is important to notice that your knowledge now has a lot of usable navigational patterns. Once you start storing your knowledge as a knowledge graph, every single point and relationship serves as a potential access point for your analysis, query or investigation.
You can start from a topic and ask what the general sentiment about this topic is. This is what we want to achieve at Hume.
Christophe will explain this and show you how our platform provides the right set of tools to easily start with your data and ultimately achieve a knowledge graph.
Christophe Willemsen: I will really focus on natural language capabilities enrichment and the type of machine-learning algorithms that are applicable for the resulting graph.
Once you start ingesting data, you might represent it in a simplified version, like shown in the image below.

This graph has been through a first pass of natural language processing.
You have your documents and annotated texts that represent the entry points of the natural language processing (NLP) view of the same document. These annotations do not interfere with your original domain.
Then you have sentences, entities and words that are in the document. Tags are tokens and entities.
The quality of your entities is very important. This is because entities represent real-world concepts, like people and organizations.
You can rely on probabilistic models, but entities are not 100 percent accurate. This means that there will always be wrong results, which is something that will always happen.
The problem is that the quality of your entities determines the quality of all the further steps that will apply to your graph.
Another problem we need to look out for is ensuring that organizations and locations are not recognized in the wrong context. An example is Amazon. In one sense, it refers to the company, and in the other, it refers to the rainforest in South America. If you have the wrong entity, the graph analysis – or usage of this graph – will produce problems.
Named Entity Recognition
This is why quality of the entities is important. By default, NLP tools provide general entity recognition models. These include people, locations, organizations, money, numbers, or dates and time, which are all very generic because they apply to every domain.
In Hume, we have the capability to train your models based on your domain.

This is essential; for example, if you are working in the insurance industry, you need to recognize the cause of an accident. Or if you are working in finance, you need to recognize startup or company names more efficiently than with a general model.
Healthcare is also a very specific domain, since a drug in one realm of healthcare could be beneficial, while detrimental in other realms.
Therefore, it is very important to have great entity recognition models. At Hume, we use the capabilities of Stanford LLP based on a general entity recognition model. We also have the ability to train our own model. However, when doing this, you always have noise.
But, we actually found a technique to remove the noise by combining deep learning-based model https://en.wikipedia.org/wiki/Word2vec Word2Vec based on the context of the text in which the entities appear.
To give you an example, Word2Vec returns a vector representation of a word or an entity. After obtaining this vector representation, we can then apply mathematical operations on them.
One operation that we can apply is cosine similarity. This is a well-known similarity that is accurate in computing the distance between vectors. It also removes words or entities that are irrelevant to our context.
Entity Recognition
The advantage is that cosine accomplishes 99 percent precision on very complex domain models.
Here is an example of applications and why those entities are important.
I might want my user to access a document very easily. We extract entities that represent locations or geographic latitude and longitude points in the documents.
When it is a location (as shown below), we can use geolocation application programming interfaces (APIs). These could be Google APIs, and we store them in the graph.

With Neo4j, it is now very easy for a user to click on the map and find the document that mentions entities located about 100 miles around the click. This offers a very easy way for business people to retrieve documents.
Entity and Concept Enrichment
However, entity recognition is not the only problem nor the only way to enrich your graph.
You can also use external knowledge bases like Wikidata or ConceptNet 5. Wikidata offers the ability to enrich entities. It can discover that Amazon is a company, but that it is also a rainforest. ConceptNet 5 allows us to understand that Secret is a device, and that San Francisco is located in California.
You can also create new connections into the graph between your documents. For example, if you take a document with San Francisco and a document with Los Angeles, there is nothing that the entity recognizes that will relate the two.
However, by using external knowledge, you can create a new connection with California, United States. This will automatically enrich your graph, share connected data, and increase knowledge about your documents.
We arrive to a graph approximately like below.
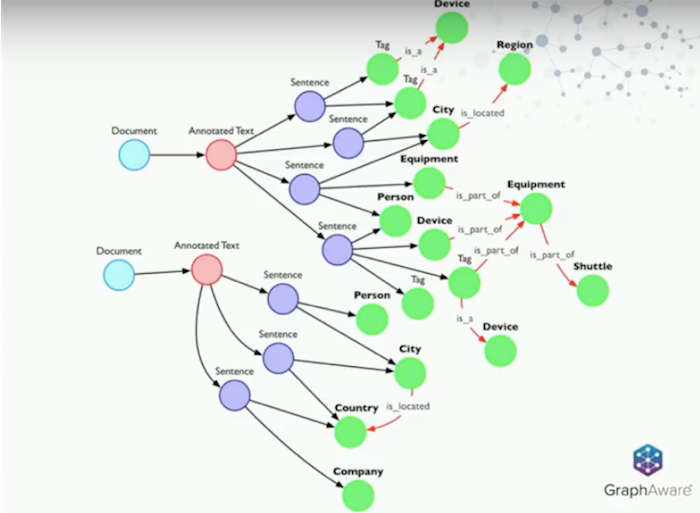
In the graph above, we see that tags, tokens and words can be recognized as a device. We also recognize a city that is located in a region or equipment that is part of other equipment.
If you bring that to hundreds, thousands or a million documents, you will have a lot of connected data. You will also have the ability to provide services that are based only on the graph analysis of your documents.
Enrichment
We have created procedures for our enrichment process on top of Neo4j. For example, Elon Musk is the founder of Tesla, which is in the car industry. This is not only text. If you take articles, they contain images, like the one shown below.

In this way, you can add additional metadata to your graph. This is especially useful in conjunction with image recognition platforms like IBM Watson Recognition, Google or Microsoft Computer Vision.
These platforms produce results of the recognition electrical devices, colors, mechanisms and machines. Moreover, it will add this information into your graph to provide improved access patterns to your users.
It also adds more connected data and the ability to provide relationships between related documents.The quality of what you bring in your graph will determine the quality of the applications you build.
Enrichment Cleaning
This is why we have used a deep learning-based model like Word2Vec. There are also GloVe, Wikidata and FastText models to filter out the labels returned by IBM Watson or other services. These platforms remove words that are out of context, as well as words that result from external bases.
There are more techniques that can enrich your graph. Doc2vec applies mathematical operations like cosine similarity to compute the distance of meaning between documents.
If you store the top 500 documents or the top 100 related documents, you will improve your graph-based search or recommendation engine because of the graph structure. You don’t have to compute the similarity or traversals because you will already know the top 100 related documents.
As seen below, you only need to store a relationship between two documents or concepts. Then you will discover the similarity between them.

Topic Modeling
Topic modeling offers the ability to cluster your documents in an unsupervised manner, so you don’t have to have labeled data. It analyzes your text and the clusters between them, and makes groups based on meanings.
In the image below, the topic nodes are in the top and bottom left.

By just looking at this graph, adding additional information, provides new ways of producing relevant results to your user.
This is not only useful for searching or finding related documents. It’s also important in the types of applications that ensure that your business or subject matter experts are involved in the whole process.
If you start a Neo4j cluster within two to three days, it will analyze a lot of data and build a model with Doc2Vec. Using this model, you will have approximately the same accuracy as that of Stanford. However, you will be able to obtain results in only seven milliseconds.
Once you want to go to scale or adopt pipelines, it is really important to know the tools you are using. It is also important to have components that are able to solve your needs. For example, customer support for an airline cannot afford 22 seconds for a document. They need it to be extremely fast-paced.
Imagine what we can extract from only one document like the one below.

The image shown below is already a huge knowledge graph. Imagine multiplying this by one thousand or one million.

It would be an awesome knowledge graph.
Neo4j Performance
In terms of performance, this image below depicts the performance for one Neo4j node.

If you have a three-node cluster, it will be approximately three times faster.
Let’s say we have a longer text document like a research paper. It may take approximately one day to process one million documents.
With Neo4j, you can take the same code, build up a spring boot application with only the code in your palm, and scale it as much as you want.
At the end, there is an ecosystem of components that you can compose in order to solve an information need. It is very important that you have an information need, since it represents the difference between data-driven and knowledge-driven logics.
Rob Schley : Every day, I’m asked what Hume is. Hume is an approach aimed at turning machines from passive things into active things. It’s about building machines that collaborate with us to understand huge amounts of information – quickly, efficiently, precisely and reliably. The whole idea is to turn information into knowledge for people.
Share Article



Explore
Related Articles
A Knowledge Layer For Your Agentic Systems on Google Cloud

The Context Gap: Why Your Smart-Sounding AI Struggles to Reason

From Data to Intelligence: Why Every Enterprise Needs an AI Knowledge Layer

Why Healthcare CIOs Can’t Afford to Scale AI Without a Knowledge Graph Foundation

