Loading data into Neo4j with Google Cloud Dataflow


21 min read
Today’s enterprises don’t just need to manage larger volumes of data – they need to generate insight from their existing data. In cases such as product recommendation in retail, fraud detection in FSI, and identity management in gaming, the relationships between data points can matter more than the individual points themselves.
In order to leverage data relationships, organizations need a database technology that stores relationship information as a first-class entity. That technology is a graph database. Neo4j delivers the first graph data science platform, the most flexible graph data model and the easiest-to-use graph query language.
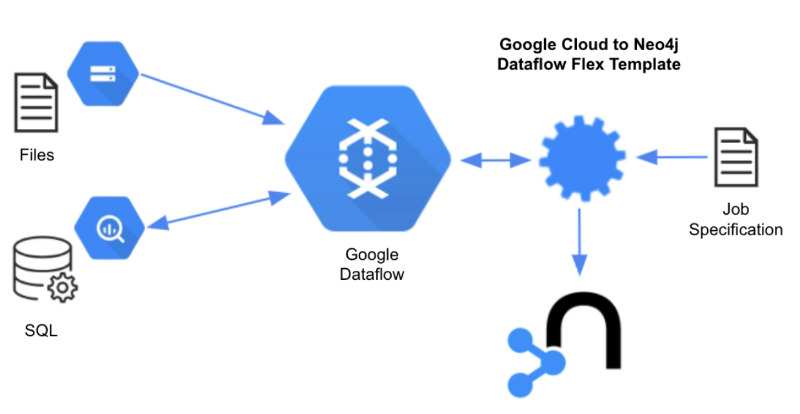
We are excited to announce that Neo4j has released flex templates for Google Cloud Dataflow, which support complex ETL processes through configuration, not code. This capability fills a gap for joint Google Cloud and Neo4j customers who are looking for cloud native data integration without having to manage complex ETL processes.
Over the past decade, graph databases have become an invaluable tool for discovering fraud, understanding network operations and supply chains, disambiguating identities, and providing recommendations – among other things. Now, BigQuery and Google Cloud Storage customers will be able to easily leverage graphs to mine insights in the data.
What is GCP Dataflow?
Google Dataflow is a fast, serverless, no-ops platform for running Apache Beam pipelines. Most Google customers will run Dataflow as a hosted service which autoscales compute. When idle, Dataflow costs nothing.
To accelerate time to value, Google packages over 40 pre-built Apache Beam pipelines that can be used to tackle common integration patterns. These templates are free to use and are published on GitHub so developers can use them as starting points when building their own custom Beam jobs.
Dataflow users can coordinate flows using the Cloud Dataflow operator in the Google Cloud Composer service which is based on Apache Airflow. Together, these tools allow orchestrated data movement across GCP native and partner solutions including: BigQuery, Spanner, Cloud Storage, Splunk, MongoDb, Elasticsearch, and more. To this list we now add Neo4j.
GCP to Neo4j Flex Template
There are many ways to move data into Neo4j. The most popular approach for bulk loading Neo4j is the LOAD CSV Cypher command from any client connection such as Java, Python, Go, .NET, Node, Spring, and others.
Data scientists tend to favor the Neo4j Spark connector and Data Warehouse connector, which both run on DataProc and are easily incorporated into Python notebooks.
For individual users, the graphical ETL import tool is very convenient and for enterprises needing lifecycle management, Apache Hop, a project co-sponsored by Neo4j, is a great option.
The Dataflow approach is interesting and different for a few reasons. Although it requires a customized JSON configuration file, that’s all that is required.
No notebooks, no Spark environment, no code, no cost when the system is idle.
Also, Dataflow runs within the context of GCP security, so if a resource is accessible to the project and service account there is no need to track and secure another resource locator and set of credentials. Finally, the Neo4j flex template implements Neo4j java API best practices.
These features make this solution ideal for copy-and-paste re-use between customer environments. For example, a best-practices mapping that loads Google Analytics (GA) from BigQuery to Neo4j could be leveraged by any GA customer. ISVs may leverage this capability to move their solutions to the Google cloud and Google Data Lake adopters will accelerate their adoption of graph as an essential side-car service in their reference data architectures.
Features and best practices
The GCP to Neo4j template was designed to allow these capabilities and best practices:
-
- No code: Customization through configuration not code. Job optimization and run-time are opinionated, taking into account best practices.
- Merge and append: Append is useful when the database is empty, otherwise use merge for incremental updates. All Cypher statements are generated automatically, internally.
- Optimized orchestration: If edges are created before nodes are committed, there will be errors. The framework commits nodes in parallel and then singly threads edges to improve performance and eliminate deadlock errors.
- Multiple sources: One single table or view from one source is often insufficient to populate a useful Neo4j model.
- Multiple targets: Multiple sources can flow to multiple target node and edge sets to facilitate ambitious projects.
- Aggregations and groupings: For sources that support SQL push down and those that do not, targets at multiple levels of grain can be populated. In addition, calculations may be defined using ANSI SQL.
- Support for run-time variables: Incremental batch processing require run-time parameterization of queries or file paths.
- Support for pre- and post-load actions: It may be necessary to log actions or initiate in-database operations after loading or refreshing data. Through declarative dependencies, complex DAGs are configurable. Soon, it will be possible to write back from Cypher to BigQuery as well.
- Throughput throttling: Batch size and parallelism can be controlled by configuration.
Creating a job
There two primary ways to run a Dataflow job, from GCloud CLI or from the Google cloud console user interface.
Google makes it easy to test Dataflow jobs from the command line with the local Dataflow runner. All pre-processing happens locally which makes it easy to see errors, often from configuration file validation.
However, to run a job this way you must clone the repository locally.
It is more likely that you will choose to script execution of Dataflow jobs using the Gcloud CLI. A prerequisite is to enable the following APIs: Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Pub/Sub, Resource Manager, App Engine, Artifact Registry, Cloud Scheduler, and Cloud Build APIs.
There are several scripts in the There are several scripts in the test resources folder which show how this is possible.
User interface invocation
Creating a job from the user interface is very easy. From the Google cloud console Dataflow user interface, we choose “Custom Template” in the job template user interface and supply this URL:
gs://neo4j-dataflow/flex-templates/images/googlecloud-to-neo4j-image-spec.json
The template JSON file describes arguments that the template expects and has a pointer to the location of the docker image that runs the pipeline.
After selecting the template, you will be prompted for two required parameters which point to files on Google Cloud Storage as shown in the screenshot below: Job configuration file, and Neo4j connection metadata file.

In addition, there are three optional parameters. For testing or ad-hoc use, you may wish to provide an SQL query or Text file source in the optional parameters below. If supplied, these will override, respectively, the source.sql and source.uri parameters defined in the job specification file.
For production jobs, you will probably need the Options JSON structure which allows you to supply key-value token pairs as a JSON string for variable substitution. In a situation where there are multiple queries and uris, supplying one of each as optional parameters will be insufficient. Rather, tokenize the strings inside the job specification and provide tokens in the Options JSON run-time string argument.
Supported sources
The GCP to Neo4j template supports the following data sources today:

Priority additions on the roadmap include Parquet, Avro, Spanner, Postgres, and MongoDb.
Configuration
The Neo4j flex template requires two paths to Google Cloud JSON documents. The first tells the template where to write data to Neo4j. The second describes how to map source data to target nodes and edges, transformations along the way, and actions to trigger during the journey.
Neo4j connection file
The Neo4j connection file is organized simply and in this initial beta release, includes no additional security. (Google secrets manager support will be added soon).
{
"server_url":"neo4j+s://.databases.neo4j.io",
"database": "neo4j",
"auth_type": "basic",
"username":"",
"pwd":""
}
It is assumed that this configuration file is not public but that it is accessible to the Dataflow service account through GCP account administration (not discussed here). Connectivity information is in its own file to facilitate job template configuration reuse.
Job configuration file
The job configuration file is organized into three sections: configuration, sources, targets, and actions. Its outline follows here:
{ "config": {}, "sources": [ {"type": "bigquery", "name": "1k orders" ... } ], "targets": [ { "node": { "source": "1k orders" ... "transform": { ... }, "mappings": { ... } } } }, { "edge": { "source": "1k orders" ... "transform": { ... }, "mappings": { ... } } } ] , "actions": [{ ... } ] }
Before reading on, it would be useful to read through an entire configuration file, of which several are found in the project resources folder: are examples showing how to populate Neo4j from text files or from a view in BigQuery.
- Sources from BigQuery bq-northwind-job spec.json
- Sources from BigQuery, runs actions before and after load bq-northwind-actions-jobspec.json
- Sources from text embedded in-line in the job spec inline-northwind-jobspec.json
- Sources from GS hosted text file Text-northwind-jobspec.json
For text files, configuration allows handling of complex CSV encoding schemes such as Excel.
Config section
The first section, config contains global flags and parameters. The configuration section includes the following recommended parameters:
"config": {
"reset_db": false,
"index_all_properties": false,
"node_write_batch_size": 5000,
"edge_write_batch_size": 1000,
"node_write_parallelism": 10,
"edge_write_parallelism": 1
}
Note that in this release of the flex template, node and edge write parallelism are defined per source. If 10 sources are defined, it is possible that 10 workers append or merge edges. If the source and target nodes for these edges are non-overlapping, there will not be lock contention.
However, creating edges in parallel for the same source and target nodes could cause a deadlock. Our suggestion is to favor stability over performance when creating edges by limiting the total number of workers to two or three.
Beware of reset_db – it will delete everything in your database!
Sources section
Next, sources is an array containing one or more data source definitions. A singular source object (rather than an array) can be used if only one source is specified. Importantly in this initial release, there is no facility for authenticating sources. It is assumed that sources are secure externally and that access has been granted to the Dataflow service account through GCP account administration (not covered here).
There are currently two types of sources supported: text or big query. All queries require a type and name attributes. Targets include an attribute called source which refer to name tokens in sources.
Group transforms
Transforms allow post processing either in the database or in the Dataflow so that a single source can flow to multiple nodes and targets at different levels of grain and aggregation.
In this example, we have extracted a view that joins and flattens customers, products, and orders from the Microsoft Northwinds sales database. Data source files (Postgres SQL) are posted here for your convenience.
The “orders” recordset we are using here is at the level of grain of order items, same as the edges in our target. However, the nodes we will extract are for customers and products, a higher level of grain. Although the template allows you to define multiple sources, in this example we are inserting one result set from a single source into three targets – two nodes and one edge (relationship).
To support this pattern, the template re-queries the source by generating SELECT and GROUP sql statements that are pushed down when the source is relational, or computed in process byApache Beam through a SQLTransform on the PCollection.
BigQuery
Big Query sources are defined using fragments that include a query attribute describing a SELECT from table or view statement. The template reads datatypes from BigQuery and carries them forward. In these examples, the initial source query includes all fields required to populate nodes and edges downstream, even extras. The “automap” flag will map all fields in a source query to properties in target nodes and edges.
{
"type": "bigquery",
"name": "1k orders",
"query": "SELECT customer_id,contact_name,company_name,seller_id,seller_first_name,seller_last_name,seller_title,product_id,product_name,category_name,supplier_name, supplier_postal_code, supplier_country,order_id,order_date, shipped_date,required_date,quantity,unit_price,discount FROM neo4jbusinessdev.northwind.V_CUSTOMER_ORDERS"
Text
For text sources, the uri attribute refers to a Google Storage location. With Text sources on Dataflow, it is necessary to specify column names in the ordered_field_names field rather than adding this information to the first row in the file (TextIO does not support a header row).
{
"type": "text",
"format": "EXCEL",
"name": "1k orders",
"uri": "gs://neo4j-datasets/northwinds/nw_orders_1k_noheader.csv",
"delimiter": ",",
"ordered_field_names": "customer_id,contact_name,company_name,seller_id,seller_first_name,seller_last_name,seller_title,product_id,product_name,category_name,supplier_name,supplier_postal_code,supplier_country,order_id,order_date,shipped_date,required_date,quantity,unit_price,discount"
}
The text parser leverages Apache CSVFormat so the format attribute supports these values here. The EXCEL format for example, supports delimited text such as inline quotes and commas:
Lager,Beverages,”Pavlova, Ltd.”,3058,Aust
For testing, it may be convenient to specify text files inline:
"data": "ALFKI,Maria Anders,Alfreds Futterkiste,6,Michael,Suyama,Sales Representative,28,Rössle Sauerkraut,Produce,Plutzer Lebensmittelgroßmärkte AG,60439,Germany,10643,1997-08-25,1997-09-02,1997-09-22,15,45.6,0.25~ALFKI,Maria Anders,Alfreds Futterkiste,6,Michael,Suyama,Sales Representative,39,Chartreuse verte,Beverages,Aux joyeux ecclésiastiques,75004,France,10643,1997-08-25,1997-09-02,1997-09-22,21,18,0.25~ALFKI,Maria Anders,Alfreds Futterkiste,4,Margaret,Peacock,Sales Representative,76,Lakkalikööri,Beverages,Karkki Oy,53120,Finland,10702,1997-10-13,1997-10-21,1997-11-24,15,18,0",
"delimiter": ",",
"separator": "~",
That is possible by specifying a data key and a delimiter such as tilda (~) as shown above.
Javascript arrays like this will also work:
"data": [["ALFKI","Maria Anders","Alfreds Futterkiste","6","Michael","Suyama","Sales Representative","28","Rössle Sauerkraut","Produce","Plutzer Lebensmittelgroßmärkte AG","60439","Germany","10643","1997-08-25","1997-09-02","1997-09-22","15","45.6","0.25"],["ALFKI","Maria Anders","Alfreds Futterkiste","6","Michael","Suyama","Sales Representative","39","Chartreuse verte","Beverages","Aux joyeux ecclésiastiques","75004","France","10643","1997-08-25","1997-09-02","1997-09-22","21","18","0.25"],["ALFKI","Maria Anders","Alfreds Futterkiste","4","Margaret","Peacock","Sales Representative","76","Lakkalikööri","Beverages","Karkki Oy","53120","Finland","10702","1997-10-13","1997-10-21","1997-11-24","15","18","0"]]
Data is cast from strings to native types prior to insertion into Neo4j so there is no need to worry about data types in the JSON source.
Targets section
The targets section is an array containing one or more node and edge objects. Each target refers back to a source through the name property. Other common properties include active (boolean), mode (append or merge), and transform. A simple transform like this would be used to extract distinct dimensions (such as customers) from a highly granular source (like orders):
"transform": {
"group": true
},
Transform will group on fields mentioned in target keys, labels, sources, targets, types, and properties. If group is not true, any duplicate data will be pushed down to Neo4j, causing errors on append or making merge less efficient. In addition, they can include scalar functions to reproject data from the source.
A more sophisticated transform supports calculated fields and row limits:
"transform": {
"aggregations": [
{
"expr": "SUM(unit_price*quantity)",
"field": "total_amount_sold"
},
{
"expr": "SUM(quantity)",
"field": "total_quantity_sold"
}
],
"group": true,
"limit": -1
},
In this example, the token field is an alias for the calculation found in expr. Calculations can be written in ANSI sql and require group to be true.
Mapping sources to targets
In target configuration, there are multiple ways to specify field mappings, which will become more clear next. A field mapping relates a source data field (field) to a target property in Neo4j. By default, properties will inherit the name of fields, literally. Using the notion below, we can target a different name alias. The alias will be the property name in Neo4j.
Individual source fields:
"field_name"
Multiple source fields:
["field1_name","field2_name"]
Several source fields with graph field names:
[{"field_name": "graph property name"},
{"field_name": "graph property name"}]
Constants, such as label or type names are denoted escaped quotes, such as “”Purchases””. Otherwise the word will be read as a dynamic field variable.
Node targets
For nodes, there are two required keys: label and key and optional properties. Together, the label and key qualify a source or target for a relationship. Other keys are organized for data typing and constraints.
By default, fields specified in unique or indexed or created as string fields. You can override the data types by including fields in the dates, longs, or doubles arrays. A string array is also offered for properties that need no indexes or unique constraints.
"node": {
"source": "1k orders",
"name": "Customer",
"active": true,
"mode": "merge",
"transform": {
"group": true
},
"automap": false,
"mappings": {
"labels": [
""Customer""
],
"keys": [
{"customer_id": "Customer Id"}
],
"properties": {
"unique": [],
"indexed": [
{"contact_name": "Contact Name"},
{"company_name": "Company Name"}
]
}
}
}
Edge targets
For edges, there are three required keys: type, source, target, and optional properties.
As with nodes, there are common configurations in the target root section.
"edge": { "source": "1k orders", "name": "Purchase Edges", "mode": "merge", "active": true, "transform": { "aggregations": [ { "expr": "SUM(unit_price*quantity)", "field": "sum_amount" }, { "expr": "SUM(quantity)", "field": "sum_quantity" } ], "group": true, "order_by": "product_name ASC", "limit": -1 }, "automap": false, "mappings": { "type": ""Purchases"", "source": { "label": ""Customer"", "key": {"customer_id": "Customer Id"} }, "target": { "label": ""Product"", "key": {"product_id": "Product Id"} }, "properties": { "indexed": [ {"order_id": "Order Id"} ], "longs": [ {"sum_quantity": "Calculated order quantity"} ], "doubles": [ {"sum_amount": "Calculated order amount"} ], "dates": [] } }
Actions section
The actions section contains commands that can be run before, after, and within data loads. Action types currently supported include http_post, http_get, bigquery, and cypher.
{
"name": "Post Action POST test url",
"execute_after": "loads",
"execute_after_name": "",
"type": "http_post",
"options": [
{"url": "https://httpbin.org/post"},
{"param1": "value1"}
],
"headers": [
{"header1": "value1"},
{"header2": "value2"}
]
}
Query actions require an sql option. Http actions require a url option. Cypher actions require a cypher option. By default, actions execute after edges and nodes process, execute_after is “loads“. Other stages of the execution pipeline that are valid values for execute_after include: start, sources, nodes, edges, loads, and preloads. To execute an action after execution of a particular node or edge, specify the type in the singular form and name this way:
“execute_after”: “edge”,
“execute_after_name”: “Purchase Edges”,
Supported types include source, node, edge, and action, all of which do have names.
Variable substitution
For production use cases it is common to supply date ranges or parameters based on dimensions, tenants, or tokens. Key-values can be supplied to replace $ delimited tokens in SQL, URL, or parameters. For example, you may want script execution to pick up where it left off the prior day.
Variables must be escaped with the $ symbol such as the variable $limit. Replaceable tokens can appear in job specification files or in readQuery or inputFilePattern (source URI) command-line parameters or in action options or headers.
CLI local testing
Google makes it easy to test Dataflow jobs from the command line with the local Dataflow runner. All pre-processing happens locally which makes it easy to see errors, often from configuration file validation. You will want to clone this GitHub project and review this README to get started.
There are several scripts in the local test resources folder which show how to run the template locally.
In this example using local test runner, we populate Neo4j from BigQuery. We provide a parameterized SQL statement and supply the parameter $limitin the optionsJson argument.
export PROJECT= export GS_WORKING_DIR=gs:// export APP_NAME= export JOB_NAME= export REGION= export MACHINE_TYPE= mvn compile exec:java -Dexec.mainClass=com.google.cloud.teleport.v2.neo4j.GcpToNeo4j -Dexec.cleanupDaemonThreads=false -Dexec.args=" --runner=DataflowRunner --project=$PROJECT --usePublicIps=true --stagingLocation=$GS_WORKING_DIR/staging/ --tempLocation=$GS_WORKING_DIR/temp/ --jobName=$JOB_NAME --appName=$APP_NAME --region=$REGION --workerMachineType=$MACHINE_TYPE --maxNumWorkers=2 --readQuery="SELECT customer_id,contact_name,company_name,seller_id,seller_first_name, seller_last_name,seller_title,product_id,product_name,category_name,supplier_name, supplier_postal_code, supplier_country,order_id, quantity,unit_price, discount FROM neo4jbusinessdev.northwind.V_CUSTOMER_ORDERS LIMIT $limit" --optionsJson="{"limit":100}" --jobSpecUri=gs://neo4j-dataflow/job-specs/testing/bigquery/bq-northwind-jobspec.json --neo4jConnectionUri=gs://neo4j-Dataflow/job-specs/testing/common/auradb-free-connection.json"
This template requires Java 8 or newer.
CLI invocation
For operational use cases you can script execution of Dataflow jobs using the Gcloud CLIA prerequisite is to enable the following APIs:
Dataflow, Compute Engine, Logging, Cloud Storage, Cloud Storage JSON, BigQuery, Pub/Sub, Resource Manager, App Engine, Artifact Registry, Cloud Scheduler, and Cloud Build APIs.
There are several scripts in the local cli-script resources folder which show how this is possible.
- Sources from BigQuery TEST-BQ.md
- Sources from text embedded in-line in the job spec TEST-TEXT-INLINE.md
- Sources from GS hosted text file TEST-TEXT.md
Executing a job through the CLI is functionally equivalent to using the user interface. Accepting the defaults yields a very minimalistic script:
export TEMPLATE_GCS_LOCATION="gs://neo4j-dataflow/flex-templates/images/gcp-to-neo4j-image-spec.json" export REGION=us-central1 gcloud dataflow flex-template run "test-bq-cli-`date +%Y%m%d-%H%M%S`" --template-file-gcs-location="$TEMPLATE_GCS_LOCATION" --region "$REGION" --parameters jobSpecUri="gs://neo4j-dataflow/job-specs/testing/bigquery/bq-northwind-jobspec.json --parameters neo4jConnectionUri="gs://neo4j-dataflow/job-specs/testing/common/auradb-free-connection.json"
The REST version looks like this:
curl -X POST "https://Dataflow.googleapis.com/v1b3/projects/neo4jbusinessdev/locations/us-central1/flexTemplates:launch" -H "Content-Type: application/json" -H "Authorization: Bearer $(gcloud auth print-access-token)" -d '{ "launch_parameter": { "jobName": "test-bq-rest-'$(date +%Y%m%d-%H%M%S)'", "parameters": { "jobSpecUri": "gs://neo4j-dataflow/job-specs/testing/bigquery/bq-northwind-jobspec.json", "neo4jConnectionUri": "gs://neo4j-Dataflow/job-specs/testing/common/auradb-free-connection.json" }, "containerSpecGcsPath": "gs://neo4j-Dataflow/flex-templates/images/gcp-to-neo4j-image-spec.json" } }'
Debugging
To debug your solution, read the launcher and run-time logs. Run-time worker logs are exposed in the primary DataFlow user interface. To see launcher logs which include the ingested job spec and action parameters, you can use the DirectRunner locally (requires pulling the github project) or finding the launcher logs through the Logs Explorer
Filter your query to isolate these logs from all others:
- RESOURCE TYPE: “Dataflow Step”
- SEVERITY: “Info”
- PROJECT ID: “<Your project>”
- JOB ID: “<Your dataflow job Id>”
- LOG NAME: “dataflow.googleapis.com/launcher”

Logs will appear as shown:

Neo4jIO
A customary pattern for Dataflow template development is to start with a sink/source IO connector such as BigQueryIO, TextIO, ClickHouseIO, SplunkIO, JdbcIO, AvroIO, and others. These become building blocks for templates which expose parameters in the Dataflow user interface.
The Neo4jIO connector committed in Beam 2.38 wraps the Neo4j java sdk and includes cypher read and batch, unwind write functions. Methods in this source/sink return PDone which is perfect for some applications. The flex template makes use of a blocking function which returns an empty PCollection.
Take the next steps
For application development, if you aren’t already an Aura user, you can sign up for AuraDB to get started right away. For data science, sign up for AuraDS hosted on the Google Cloud.
To roll your own Neo4j cluster on the Google Cloud, check out the incrementally billed marketplace listing.
Take action
If you have data on Google Cloud and want to see what graph insights it may contain, the Dataflow Neo4j FlexTemplate ought to save considerable time and effort with data loading.
Share your feedback
The Google Cloud to Neo4j flex template has been released as beta software, open source for customer feedback.
Please join the Neo4j community and share your experiences with the GCP to Neo4j dataflow template.
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher


SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3


