How to Make Small Talk with Your Boss About Music (With the Help of Graph-Based Recommendations)

Senior Pre-Sales Consultant, Neo4j
5 min read

We’re all used to the idea of digital content recommendations by now.
Netflix recommends films and shows we might want to watch based on our preferences and past viewing history. Spotify recommends songs and artists to us that we might want to listen to based on what we’ve played recently and/or most extensively. And Amazon recommends Kindle books we might want to read based on the authors and topics we’ve shown an interest in.
I like to think, though, that not only are graphs everywhere… but recommendations are everywhere, too. So I started thinking, “Where else could I apply recommendations in my own life?”
I’d been dying to load and explore a large music graph for a while now, so an idea started to form. I decided to try and figure out what the overlap might be between my musical tastes and those of Neo4j CEO Emil Eifrem. Do we like any music in common? Is the music he likes at all like the music I like? If I got stuck in a lift with Emil and had to make small talk, should I mention any of my favourite bands or recommend them to him?
First I had to find out what kind of music Emil likes, and this is where things get a little stalkerish. For the “stuck in a lift making small talk” thing to work, it has to seem completely natural and off-the-cuff, so I couldn’t just ask Emil what he listens to – I had to seek that information out elsewhere.
So I did a bit of sleuthing on social media, telling myself, “This is totally uncreepy and anyway he’ll never read this… right?”
Here’s what I found.
Emil’s public profile on Spotify lists a few playlists, which I used as my starting point. There were a few soundtracks that probably wouldn’t be too useful for my recommendations – “Moulin Rouge” and “Disney Hits” (most likely for car journeys with his daughters, though in our elevator scenario I could take a gamble and start humming “Let It Go”). The artist playlists gave me a better starting point – Robbie Williams, Robyn, Amanda Fondell and Kate Bush.
Emil’s public Facebook profile only shows one “Like” for a music artist – Loney Dear. The accounts he follows on Twitter didn’t turn up much else either; lots of tech-oriented folks, of course, but very few obvious musical artists. I only spotted James Blunt and Loney Dear (maybe he really likes Loney Dear).
So that’s my starting list of artists: Robbie Williams, Robyn, Amanda Fondell, Kate Bush, James Blunt and Loney Dear. Let’s see what I can do with it!
First, I loaded some of the data from the MusicBrainz open music encyclopedia into a graph. There were a few challenges here: it’s a fairly large datasets, stored in normalised relational database, and it contains a lot of data which probably isn’t too relevant to my recommendations engine. In the end, I decided to just load a few key entities that would allow me to see the relationships between artists, their recordings and “tag” metadata.
Here’s the graph model:
call db.schema()
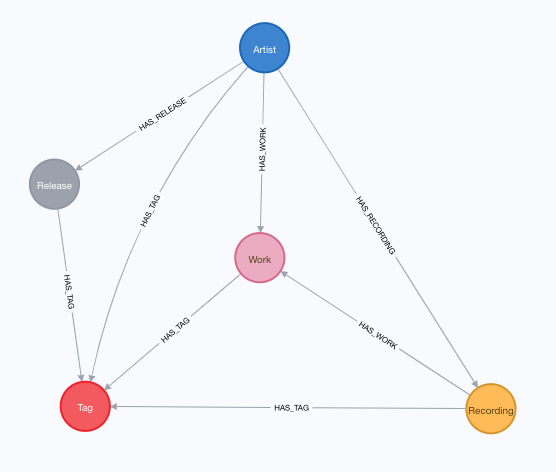
Artists and Tags are pretty straightforward, but the others probably need a brief explanation.
- A
Releaserepresents a unique release (“Issuing”) of a product – specific to the date, country, label, barcode, medium, packaging, etc. This could be a vinyl album, a CD single, etc. - A
Recordingis a representation of some distinct audio that was used on at least oneReleasedtrack. Tracks aren’t represented in our data model, to keep the database size down, and because they weren’t as useful for helping us get toTags, but they could be used to linkRecordingstoReleases. - A
Workis an intellectual or artistic creation, which can be performed by artists in one or more recordings. A cover song would have oneWork, but manyRecordings.
Once I had the database set up, I started by tagging the artists that I found that I think Emil likes:
MATCH (a:Artist) WHERE a.name in ['Kate Bush', 'Loney Dear', 'Robbie Williams', 'Robyn', 'Amanda Fondell', 'James Blunt'] SET a:EmilFave RETURN a

Then I found some of my favourite artists and tagged them, too.
I have pretty eclectic musical tastes, so I tried to pick a range of styles and decades to give myself the best chance of finding interesting connections with the list of artists tagged for Emil. I also had to be quite specific, as some of the artists’ names are duplicated in the database (James Brown is a super-common artist name, who knew?).
MATCH (a:Artist) WHERE a.name in ['Pink Floyd', 'Daft Punk', 'LCD Soundsystem', 'The Flaming Lips', 'ESG', 'Parquet Courts', 'The Velvet Underground', 'Nina Simone', 'Hercules and Love Affair'] OR (a.name = 'James Brown' and a.comment = 'The Godfather of Soul') OR (a.name = 'Air' and a.comment = 'French band') OR (a.name = 'Interpol' and a.comment = 'NYC post-punk band') SET a:JoeFave RETURN a

To start my search for matches, I listened to a few tracks by Robyn on Spotify. She’s an artist I’ve heard of, and have probably heard before, but I’m not familiar with her body of work. The first thing I thought was, “Hey, this sounds similar to one of my favourite bands, Hercules & Love Affair.”
So I wrote a Cypher query for my graph to see whether these artists are somehow connected, and what the graph might look like between them.
MATCH (startNode:EmilFave {name: 'Robyn'}), (endNode:JoeFave {name: 'Hercules and Love Affair'}),
path = allShortestPaths( (startNode)-[*]-(endNode) )
RETURN path

As it turns out, they both have a number of Releases that have the same tags!
Both Robyn and Hercules & Love Affair are associated with the tags Electronic, Synth-pop, Pop, House, Electro, Europop and Dance. I would certainly say that I like many of these musical genres, and if Emil does too, then I’m sure we’d have lots to talk about!
Next, I thought I’d see if any of my favourite artists performed the same songs (or “Works”) as those from Emil’s list:
MATCH path = (:EmilFave)-[*]->(:Work)<-[*]-(:JoeFave) RETURN path

From the query results, I can see that Robbie Williams has performed two of the same works in the database as Nina Simone, though if I’m sure if you asked them they’d each insist they did it “My Way.”
Robbie has also performed one of the same works as The Flaming Lips, which is a link I would never have guessed! It would be interesting to compare the Flaming Lips version of “Sgt. Pepper’s Lonely Hearts Club Band” with the version by Robbie Williams (which seems like it was part of the Take That “Progress Live” Tour setlist). I’m sure they are very different performances, indeed. I know which I’d prefer – maybe someday I’ll get to find out which one would be Emil’s favorite.
One of the artists that Emil follows on social media, Loney Dear, was entirely new to me, so I found some tracks on Spotify and gave a listen. I really liked what I heard!
I wanted to see if Loney Dear was in any way connected to any of the artists I tagged as my favourites:
MATCH (a:Artist {name: 'Loney Dear'}), (jf:JoeFave)
MATCH p = shortestPath( (a)-[:HAS_RELEASE|HAS_RECORDING|HAS_WORK*]-(jf) )
RETURN p
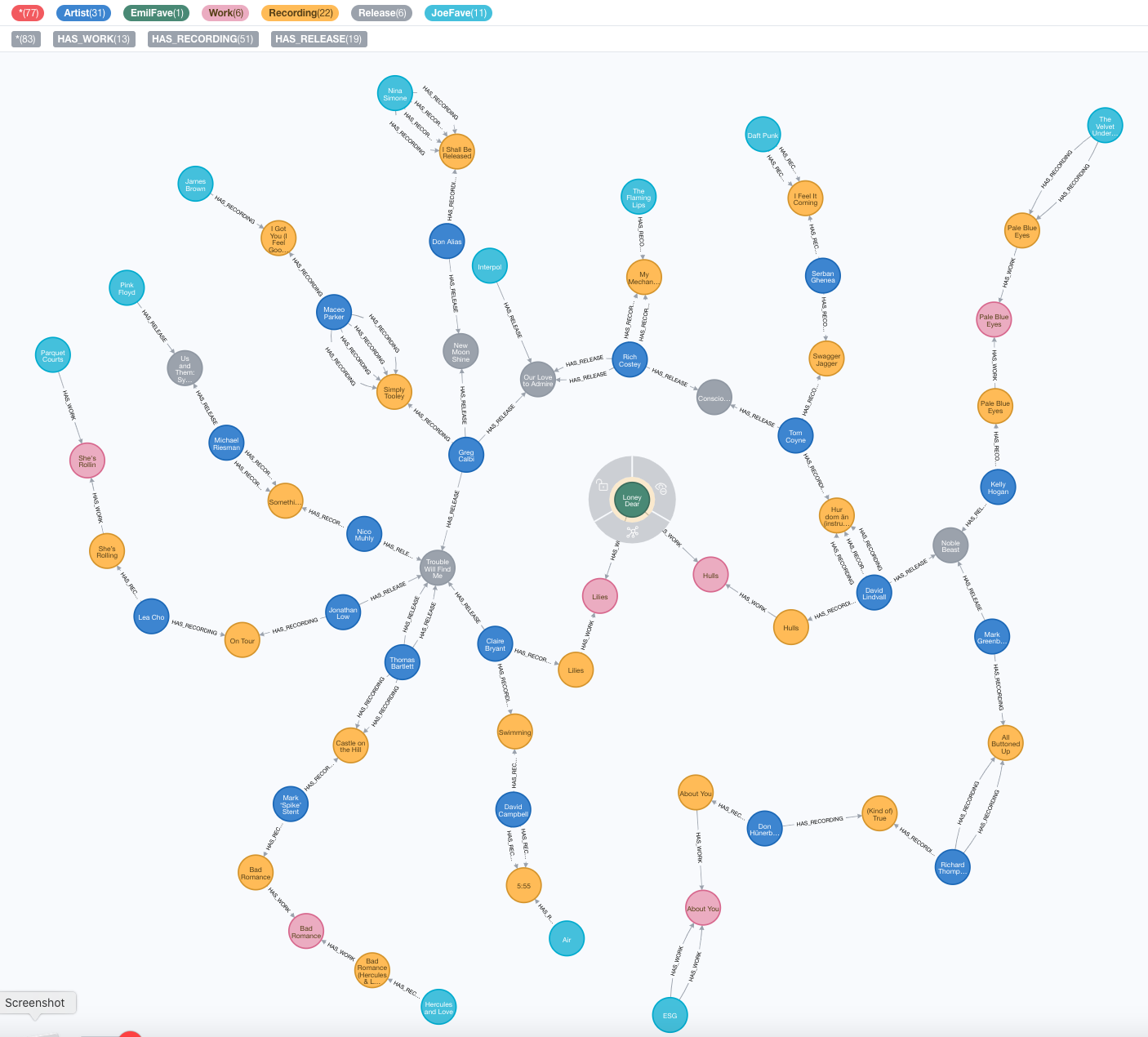
It turns out that Loney Dear is connected to 11 out of my 12 favourite artists in the graph – all but LCD Soundsystem.
Interestingly, all of his connections to my favourite artists are made via two artists who played on his recordings Lilies (Claire Bryant) and Hull (David Lindvall). I call this one “The Six Degrees of Loney Dear.”
Finally, I wanted to see which of the artists I think Emil likes are most similar to the artists I’ve tagged as my favourites.
I created a new type of direct relationship between an Artist and a Tag, where that artist is somehow also connected to that tag by a series of Recordings, Releases or Works. It’s sort of a shortcut, to make these relationships easier and quicker to work with.
MATCH (a)-[:HAS_TAG|HAS_RECORDING|HAS_RELEASE|HAS_RELEASE_GROUP|HAS_WORK*]->(t:Tag) WHERE a:EmilFave or a:JoeFave MERGE (a)-[:LINKED_TO_TAG]->(t)
This created 349 new relationships – not a lot, and fewer than I was expecting. However, it was important to be specific about the relationship types and directions to follow in my query. Being too generic, or using open-ended relationship matches, could have linked Artists to Tags they aren’t really associated with.
For example, this query, follows the HAS_WORK relationship in both directions:
MATCH path = (a)-[:HAS_RECORDING]->(:Recording)-[:HAS_WORK]->(:Work)<-[:HAS_WORK]-(:Recording)-[:HAS_TAG]->(t:Tag) WHERE a:EmilFave or a:JoeFave MERGE (a)-[:LINKED_TO_TAG]->(t)
This query creates 1004 relationships, but links Nina Simone to the Heavy Metal tag because she covered the same song as Marilyn Manson! Data. Quality. Fail.
I then wrote a query to compare the tags for both Emil’s and my list of artists, to see what the overlap was:
MATCH (startNode:EmilFave), (endNode:JoeFave) MATCH (startNode)-[:LINKED_TO_TAG]->(t:Tag)<-[:LINKED_TO_TAG]-(endNode) WITH startNode, endNode, count(distinct(t)) AS Shared_Tag_Count RETURN startNode.name as Emil_Artist, endNode.name as Joe_Artist, Shared_Tag_Count ORDER BY Shared_Tag_Count DESC LIMIT 10

Not a bad list, necessarily, but not as good as I was hoping for either.
Is Kate Bush really so similar to Pink Floyd and James Brown? Where are ESG, LCD Soundsystem, Hercules & Love Affair and the rest of my favourite artists?
Looking at the database, I can unfortunately see some gaps. There are some artists that aren’t linked with Tags in the way I was expecting, which has skewed my results. Some more data import and clean up work will be required to turn this huge, complex, crowd-sourced dataset into a complete graph-driven music recommendations engine!
Still, I think I have enough data now to make sure that if I’m ever stuck in a lift with Emil and need topics for conversation, I can make plenty of small talk about music! That’s one more recommendations use case chalked up to the power of the graph.
Now, what’s next?
[My boss Emil is a super cool guy, who clearly has awesome taste in music and totally won’t mind that I stalked him on social media. I hope. This has been a fun exercise in personalising recommendations, though.
It’s an example of some of the types of data analysis you might use when doing collaborative filtering – where you make recommendations to one person based on a comparison of their data to the behaviour, preferences, purchases, etc. from the data of other users. With more data loaded into the graph I could have done some really fun stuff – used some graph algorithms, looked at events and really fine-tuned the artist recommendation engine.
I found some good new music while writing this blog. Every time I listen to Loney Dear, I’ll remember that it was Emil who recommended this artist to me during an imaginary conversation in a lift we never rode together!]
Learn why a recommender system built on graph technology is more powerful and efficient with this white paper, Powering Recommendations with Graph Databases – get your copy today.
Share Article



Explore
Related Articles




Integrating Neo4j With Symfony: Profiling Queries and Centralized Logging