

Reposted with permission by Brian Underwood
In my last post – Making Master Data Management Fun with Neo4j – Part 1 I said I would “bring in another data source, show how I linked the data together, and demonstrate the sort of bigger picture that one can get from this approach”. There’s a lot to talk about, so I’m going to break these each into different posts so that I can give them the proper attention.
Adding GitHub
In doing an analysis of a software development community, GitHub is the peanut butter to StackOverflow’s jelly. With thousands of projects on GitHub matching the search term neo4j, there’s also a big chunk of data to chew on.
The model
The GitHub model that I imported is a bit more complex than the one for StackOveflow.
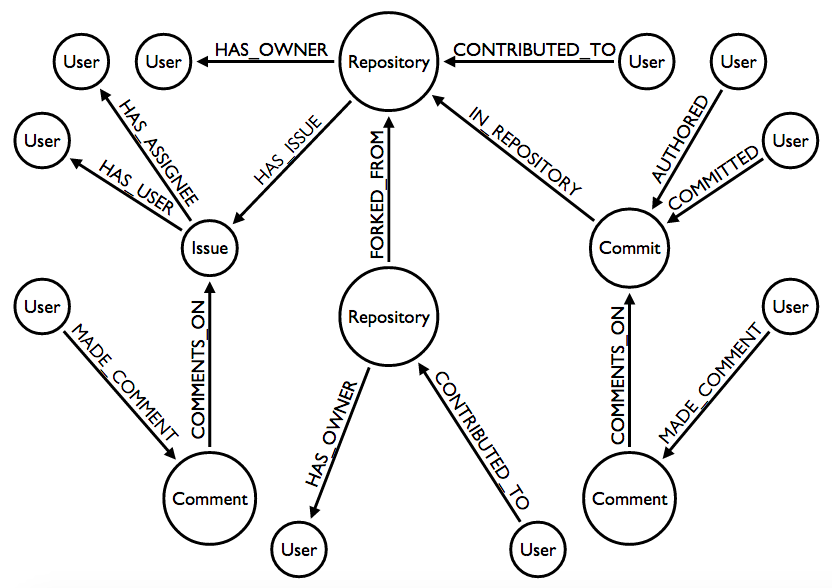
One of my goals was to examine relationships between contributors, so it made sense to import all of the places where GitHub users could interact. From the graph model you can see that this is on:
- Repositories via ownership, contribution, or forking
- Issues via creation, assignment, or commenting
- Commits via authoring, committing, or commenting
To give you a taste, I have a cypher query which UNIONs together all the different places where users can collaborate in the model:
MATCH (u1:User:GitHub)--(:Repository)--(u2:User:GitHub) WHERE u1 <> u2
RETURN u1.login, u2.login
UNION
MATCH (u1:User:GitHub)--(:Repository)-[:FORKED_FROM]-(:Repository)--(u2:User:GitHub)
WHERE u1 <> u2
RETURN u1.login, u2.login
UNION
MATCH (u1:User:GitHub)-[:HAS_ASSIGNEE|:HAS_USER|:COMMENTS_ON|:MADE_COMMENT*1..2]-(:Issue)-
[:HAS_ASSIGNEE|:HAS_USER|:COMMENTS_ON|:MADE_COMMENT*1..2]-(u2:User:GitHub)
WHERE u1 <> u2
RETURN u1.login, u2.login
UNION
MATCH (u1:User:GitHub)-[:AUTHORED|:COMMITTED|:COMMENTS_ON|:MADE_COMMENT*1..2]-(:Commit)-
[:AUTHORED|:COMMITTED|:COMMENTS_ON|:MADE_COMMENT*1..2]-(u2:User:GitHub) WHERE u1 <> u2
RETURN u1.login, u2.login
After a bit of post-processing we get the following top 20 results:
| login | count | login | count | |
|---|---|---|---|---|
| jexp | 2060 | wfreeman | 1087 | |
| peterneubauer | 1937 | rickardoberg | 1076 | |
| nawroth | 1345 | jakewins | 1064 | |
| systay | 1253 | tbaum | 1025 | |
| akollegger | 1248 | mneedham | 955 | |
| lassewesth | 1209 | jimwebber | 940 | |
| jotomo | 1188 | karabijavad | 939 | |
| dmontag | 1177 | nigelsmall | 924 | |
| maxdemarzi | 1155 | jadell | 913 | |
| simpsonjulian | 1115 | cleishm | 893 |
Neo4apis-github
Some time ago as part of creating the neo4apis gem I had created a gem to import data from GitHub. With this project I had the opportunity to more fully use neo4apis-github and to flesh it out a bit more. There were two changes which I introduced:
- In addition to supporting Repository, User, and Issue entities, it now supports Comment and Commit entities
- Instead of adding a common prefix to all labels, it now adds a second, common label. So
Usernodes will also now have aGitHublabel instead of having only aGitHubUserlabel.
github-neo4j-community
For this project I’ve made and released (on GitHub of course) the script which I used to import the data.
The script imports repositories found from searching for neo4j on the GitHub API search endpoint. Those repositories are passed into neo4apis-github, and then for each repository it imports:
- Contributors
- Forked repositories (recursively)
- Issues
- Comments for issues
- Comments on commits
The neo4apis-github gem takes care of importing the immediately associated users for all of the above (such as the owner of a repository or the owner and assignee of an issue)
Summary
All together I was able to import:
- 6,337 repositories
- 6,232 users
- 11,011 issues
- 474 commits
- 22,676 comments
In my next post I’ll show the process of how I linked the orignal StackOveflow data with the new GitHub data. Stay tuned for that, but in the meantime I’d also like to share the more technical details of what I did for those who are interested.
Implementing the request cache
The biggest challenge in writing the script was finding a way to cache the GitHub API endpoints. In developing the script it was useful to be able to build and run just one thing (e.g. just importing the repositories) and then build more on top of that. By creating a cache of the API results I don’t need to re-request the repository endpoints when I run a new version of the script to import issues, commits, and comments. Also, when my script failed half-way, as it did many times for many reasons, I can simply run it again and generally within 30 seconds it will have picked up where it left off.
The caching mechanism that I used was the ActiveSupport::Cache::FileStore class. Theactivesupport gem has a number of built-in caching stores with a common API so that they can be swapped out. MemoryStore and MemCacheStore are popular, but I went with FileStore for a persisted cache without needing to set up anything else.
My first attempt to use a FileStore could be considered somewhat clever, but in the end was too frustrating. Such is the life of a programmer…
I wanted to take the results of the github_api gem and store them in the cache, but the gem uses method chaining like this:
github_client.repos.list
# or
github_client.users.followers.list
So I created a class called GithubClientCache (source code gist) which takes a GithubClient object from the github_api gem at instantiation like so:
github_client_cache = GithubClientCache.new(github_client)
github_client_cache.repos.list # fetched from the API
github_client_cache.repos.list # cached
It seemed like a simple enough solution to the problem and a good excuse to use Ruby’s method_missing. Unfortunately due to what I think is a bug in the hashie gem which github_api used to store responses, the cached request couldn’t be processed correctly and would throw an error.
After some research I found out that the faraday_middleware gem supports just the sort of caching I wanted. Also, according to the github_api gem’s README, one can add custom middleware. Unfortunately that didn’t work! After debugging for a while I decided, in the interest of getting something working quickly, to dig into the source code and engadge in some good ‘ol fashioned monkey patching. You can see the resulthere. It’s a wholesale copy/paste of the method in question which means it is vulnerable to breaking if the gem changes, but I was fine with the tradeoff for now.
Update!
Making Master Data Management Fun with Neo4j – Part 1
Making Master Data Management Fun with Neo4j – Part 3
Want to learn more about graph databases? Click below to get your free copy of O’Reilly’s Graph Databases ebook and discover how to use graph technologies for your application today.
Share Article



Explore
Related Articles

Top 10 Graph Database Use Cases (With Real-World Case Studies)

Connecting Data Across the Enterprise: The 5-Minute Interview With Simone Novali


Neo4j as an Embedded Database: The Key Use Cases of Graph Databases

Neo4j as an Embedded Database: When Does Embedding a Graph DB Make Sense?
