Mapping ontologies in graphs for personalization

Data Scientist, Gousto
17 min read

Editor’s Note: This presentation was given by Irene Iriarte-Carretero at GraphConnect San Francisco in October 2016.
Presentation summary
Gousto is a UK-based recipe box service that uses Neo4j to map recipe ontologies so it can provide more personalized recommendations to customers. It all starts with the customer data journey, and all the places along the way that data collection and analysis can help improve efficiencies in the areas of marketing, forecasting, warehouse distributing, and product allocation.
Customer personalization plays an extremely important role in the company’s business model for a simple reason: providing relevant recipes to customers results in happier customers, which means they are more likely to continue using the subscription service.
To create these effective personalized recommendations, Gousto relies on a hybrid recommendation engine that combines the best attributes of collaborative and content-based models through LightFM, a concept developed by Maciej Kula of Lyst.
Developing an ontology in Neo4j is allowing Gousto to develop and refine a highly-functioning personalization engine that assigns similarity values between dishes based on ingredient, cuisine type, preference, customer type, and more — all to keep customers as happy as possible so they keep coming back for more.
Full presentation: Mapping ontologies in graphs for personalization
This blog explores how we are using the Neo4j graph database to develop an ontology to develop recipe personalizations for our customers:
I’m Irene, a Data Scientist for Gousto, an online recipe box service based in the UK. There are several similar concepts in the U.S. with companies such as Blue Apron and Hello Fresh.
A customer comes to our website, chooses four recipes from a weekly menu, selects how many people they’re cooking for and what day they want their food delivered. On their chosen day, a box arrives at their door with all the proportioned ingredients and simple-to-follow step-by-step recipe cards. This takes away the need for buying groceries and meal planning.
Importantly to us as a company, it also gets rid of a lot of food waste. People no longer have to buy a big bag of carrots when they only need a few, or an expensive bottle of an obscure ingredient when they really only need a tablespoon.
The proposition of Gousto is based around choice. We offer 22 different recipes on our weekly menu, which include options that are gluten-free, dairy-free and vegetarian – which allows you to tailor your menu to whatever your specific needs are. We also deliver our boxes seven days a week during the morning, afternoon and evening hours.
The data science team at Gousto is in charge of our longer-term projects, such as building algorithms that support our business needs, running analytics to optimize a conversion funnel or seeing how customers are reacting to different discounts. We are striving to be a data-driven company, and everyone is encouraged to learn SQL so they don’t have to rely on the data science team to access important company data.
The Gousto data journey
Our company is five years old, and we started our data journey quite early on with external data sources, such as Google Analytics. There were a lot of ad hoc Excel requests that came when the CEO asked for reporting, but we really couldn’t track our customer journeys to understand how they were interacting with us.
However, we recognized that data really was ultimately going to differentiate us from our competitors, so we really invested in it and created a rich data ecosystem that could support us.
This is what our data journey looks like at the moment:
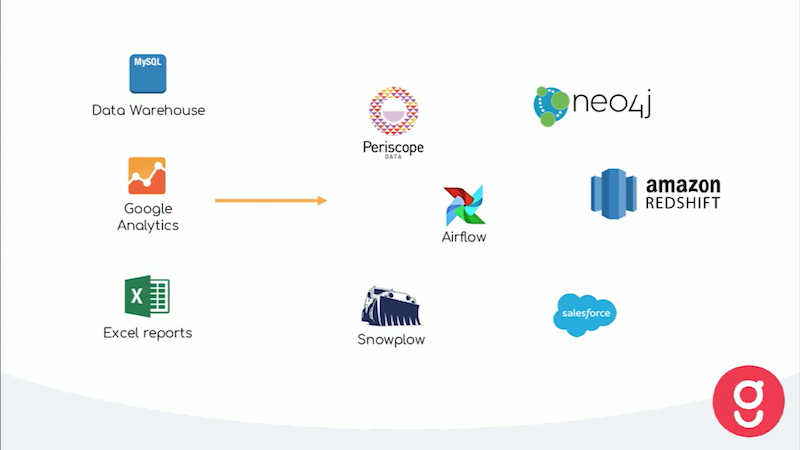
Our main data warehouse is Amazon Redshift. We use Periscope as our VI visualisation tool and Salesforce as our integrated CRM system, which allows us to see the actions our customers take. We have Airflow to support our ETL processes like daily scheduled emails, as well as Snowplough, which collects information about the actions customers take on our website. This includes tracking a customer to see where they clicked, for how long and from where.
Last but not least, we use Neo4j to calculate the similarity between our different recipes, which we’ve done by putting our ontology into Neo4j. I’m going to walk you through the background to explain the problem we were trying to solve and how we came to Neo4j as our solution.
Data and the Gousto customer journey
So how does data actually affect our product? What are the end results? Below is a simple customer journey I built to help answer this question:
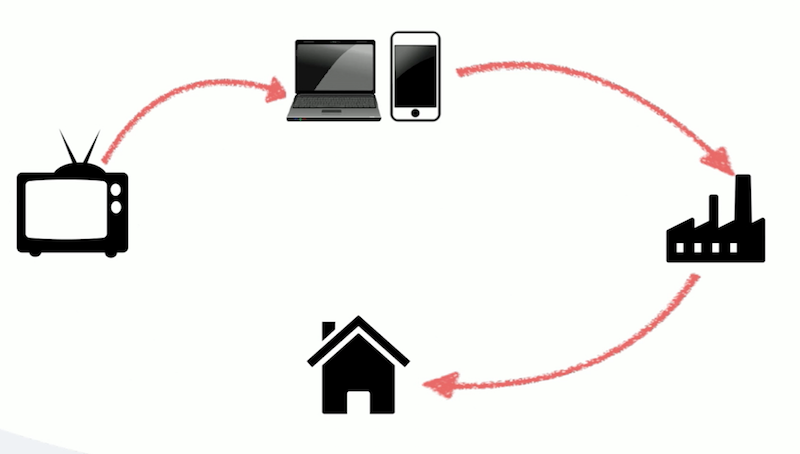
Let’s say a customer saw us in a TV ad, and decided to come to our website or our app. They’ll place an order that is fulfilled in our fulfillment centre in Lincolnshire, and once that box is ready, it’s shipped to their door.
Below are a few key points where data science plays a role in the end product:
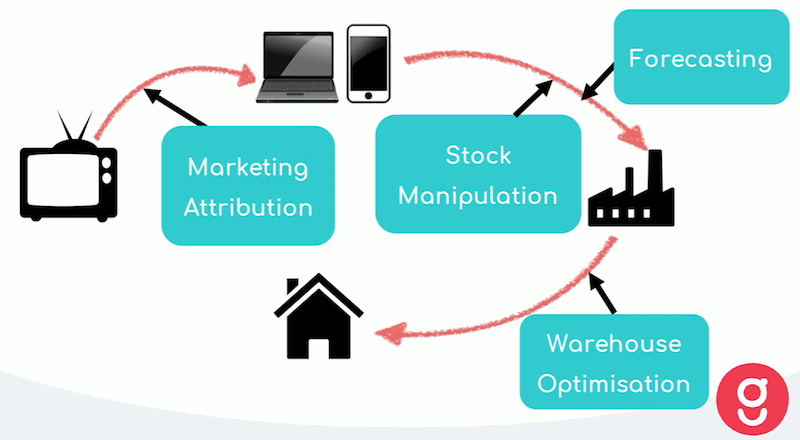
Marketing attribution
As I mentioned in the initial example, we’ve just launched a TV ad, which is what is driving the customer to our website. We have a number of additional marketing methods, such as Facebook or handing out flyers, because customers need to be reached more than once to be convinced to try any given product.
For that reason, we’ve built a marketing attribution model that looks at the different uptakes from those different channels, and how they are affecting one another. This helps inform how we should allocate our marketing spend to make sure we’re using our resources as effectively as possible.
Stock manipulation and forecasting
Once someone comes to the website, they’ll look at the long list of recipes available, select their recipes, and then receive their box three days later. Because there is such a short lead time between when an order is placed and when it’s delivered, we can’t buy to order. Instead, we need to place our orders before the customer orders are placed.
This is why we’ve built a forecasting model, which takes into account different inputs to help determine our acquisition for any given week. This includes factors like the weather, holidays, a cohort analysis of our customers, probabilistic theories and live customer trends from that week – all of which affect orders.
This gives us a total number of boxes that we then convert into the amount of each good we need to order. Out of our 22 recipes, some are more popular than others.
We know that a salad normally performs less well than chicken noodles, so we need to order more noodles. Because we’re trying to build a sustainable business, we want to ensure we’re not creating food waste while at the same time giving our customers as much variety as possible. We’re constantly tuning and adapting this model to reach this balance.
We also have a stock manipulation system for our different subscription membership types, such as gluten-free or vegetarian. Stock manipulation is an algorithm that constantly runs in the background, ensuring that we’re fulfilling those constraints.
Warehouse optimization system
Once a customer places their order, the requested recipes go into the fulfillment center, where we have a warehouse optimization system. This uses genetic algorithms to ensure that we’re picking the boxes as efficiently and as quickly as possible.
On average, we have around 50 unique SKUs per box, all of which come with certain constraints. For example, you don’t want to put a tomato at the bottom of a box and then put a tin of beans on top, because that’s probably going to squish the tomato. The warehouse optimization algorithm takes all of these types of things into account to ensure we’re picking and packing items as efficiently as we can.
What we’re really focusing on is how to close the customer journey loop:

This is to ensure that what a customer is having at home, the recipes that they’re picking, and the ratings that’re giving these recipes are actually affecting the experience that you’re getting of us as a whole.
Tightening and closing this circle really allows us to focus on providing our customers with a service that is as personalized as possible.
Personalization
Below is what personalization for our customers looks like:

At the top, we have collections like Family Friendly and Quick & Easy. Our customers want to land on a page that is specifically tailored to them so they can see what we think they will enjoy. Some people love scrolling through pictures of food – but not everyone. And because a lot of our users are so busy, it’s important for us to provide a condensed list of recipes that customers can choose from so they can efficiently make meaningful choices.
Personalization is important not only on the website, but in every communication touchpoint. This includes the CRM, so that we can send recipes and information to people that are actually going to be useful.
We also have default customers, which are people who have a subscription but haven’t yet chosen their recipes. These customers automatically get allocated recipes, which doesn’t work well for everyone. And when customers are happy with their allocated choice, they show better retention. This makes providing personalized recipes a win-win: Our customers can save time and get the recipes they want, and we can retain our customers and grow our business.
Personalization… it’s involved in the merchandising, it’s involved in how we sell you our service, but obviously, recommending recipes is a huge part of it.
Recommendation engines
We have two kinds of recommendation engines: collaborative filtering and content-based filtering.
Collaborative filtering
Let’s start with collaborative filtering, which is based on providing product recommendations based on what similar users like. Consider the below example:
We have Mark, our graph superhero, who ordered sea bass, Italian chicken and prawn linguine. We also have Emil, who has only ordered two dishes so far, the linguine and sea bass. Because these customers are fairly similar in their recipe preferences, we recommend to Emil the same third dish Mark has ordered: Italian chicken.
Collaborative filtering has several pros. For each recommendation, there are several data points. While our above example was based on similarities between two users, normally you have clusters of users that provide data points that are helpful for providing recommendations.
However, there are also several cons. The first is the concept of a “cold start,” which refers to the struggle recommendation engines face when they are dealing with a new user because there is no information available about them. Sparsity is another issue, because while we have a huge collection of recipes, a user can’t pick them all – so each user will have only interacted with a few of those recipes.
Content-based filtering
The following example is for content-based filtering, which is based on the similarity between items. In this case, we are comparing similarities between recipes:

Here we have Emil, who has previously ordered the prawn linguine. There’s another recipe on the menu this week that’s pasta-based; since the two recipes are relatively similar, we’re going to recommend the new pasta dish to him as well.
The big advantage in this type of filtering is that we avoid the “cold start” problem. We don’t need to rely on information about the user because we’re relying on recipe attributes to make the recommendation. Whereas in collaborative filtering, if that recipe has never been ordered, we don’t yet have enough information to recommend it.
On the con side, we’re not really sharing much information across users, which means there may be more subtle user behavior we’re missing.
We’re also missing out on serendipity. For example, if customers who order pasta almost always order curries as well, you don’t have enough information to know that you should recommend both dishes to these similar users.
LightFM
With the pros and cons of both collaborative filtering and content-based filtering, the perfect solution is to get the best of both worlds through a hybrid recommender system called LightFM, which was developed by Maciej Kula at Lyst. I’d recommend everyone read his paper, Metadata Embeddings for User and Item Cold-start
Recommendations, which explains how this recommender system works.
To overcome the cold start problem, we give new users 5-10 recipes to choose from when they first sign up. This provides us with some information about their preferences that we can compare to other similar users via collaborative filtering. We can also recommend recipes that are similar to the ones the customer selected during the signup process through content-based filtering. But to really take advantage of content-based filtering for similar recipes, we have to assign them with a similarity score.
Food is very subjective and evokes strong feelings, and capturing this type of information is quite challenging. Let’s consider the following example:

We have two dishes: the Brazilian black beans dish and the Cambodian Chicken dish. Other than both being rice-based, the two dishes really don’t have much in common. So which one do we recommend?
If we think about it from the perspective of someone who’s adventurous and using our service because they want to try some new dishes, we might put both items on their list because each is from a different world region and have very different flavor profiles. But if someone is using our service because they want to make sure their family is eating a varied and healthy diet, they may not want to provide their kids with dishes that are both based on chicken and rice.
Again, it really depends on why someone is using our service.
Now let’s take a look at two different recipes:

Both dishes are quite similar because they’re both hearty tacos. But if you’re trying to feed a family with children, the corn and sweet potato fries are likely more accessible in terms of flavor and excitement, while the pickled red onions may not appeal to them. But if we’re working with a customer who is using the service for convenience, they likely aren’t going to want the sweet potato recipe because it requires more time in the kitchen.
These examples demonstrate that there’s really a lot that goes into food selection. So when it comes to providing similarity scores between dishes, we can look at a variety of factors. This could include ingredients, which probably isn’t good enough for our purposes. We want to be able to capture the slightly more subtle and subjective aspects of our recipes, like cuisine type, dish type, how the recipe is presented in our website and why the customer is using our service.
The solution: Neo4j graph ontology
Now that we’ve explained the problem, let’s start going over our solution – which is where Neo4j comes in.
We decided to introduce an ontology, which is a formal naming and definition of the types, properties and interrelationship of the entities that fundamentally exist for a particular domain.
What that means for us is putting all of our recipes and ingredients into Neo4j and joining them together by defining the types, the recipes, the ingredients and the interrelationships that describe the whole thing. Because we wanted more than just a taxonomy – more than just chicken breast is part of a chicken – we have much more interesting relationships.
Why did we choose Neo4j?
Recipe and ingredient attributes are highly interconnected because a recipe is made up of ingredients, which normally defines the cuisine type, which also defines the type of dish. Everything is incredibly connected, complicated and messy, just like in real life.
In order for us to be able to capture those different point of views, it’s extremely important for us to be able to approach all of the relationships from a number of angles, which Neo4j allowed us to do.
We found some additional practical elements that made Neo4j the right tool for us.
First, it allowed us to define an extremely flexible structure for our recipes and ingredients. We were able to easily give the ingredient “chili” the attribute “spicy” without having to worry about other ingredients in our system already having that attribute. We also have a number of fusion recipes, like the Chicken Katsu burger, a cuisine that is both Japanese and American. We can assign a food origin – down to percentages – to each dish as well. This provides us with more clever similarity scores, and gives us the ability to create inferences from the data. For example, now we can take any recipe with a spicy ingredient, like chili, and label it as non-kid friendly.
How do we go from having this ontology and structure to calculating similarities? When playing around with it, we came up with two methods: supervised and unsupervised.
Supervised methods involve using tagged data and attributes to determine how two recipes are connected by a variety of factors, such as cuisine type and shared ingredients. That tagged data can be used by our system to calculate weights of different attributes, tied to scores, to fit to training data. In the unsupervised approach, we use clustering on tagged data to validate the model.
Our goal is to use data base on what our customers are ordering, what they’re not ordering, and how they’re rating recipes so that we can train the model to learn even more – but we’re not quite there yet.
To benchmark our similarity scores, we set up a RecipeBot on Slack that asked Gousto employees to rate the similarity of certain recipes. We gathered thousands and thousands of answers, which we’re now starting to leverage.
This is where we are now as a company – and it’s all very much a work in progress – but I look forward to sharing more concrete results in the future.
Conclusion
This is really just the start of Gousto and Neo4j working together.
We walked away from GraphConnect London with a ton of ideas and questions. Could we take personalization one step further with Snowplow data? As I mentioned earlier, Snowplow allows us to gather granular user activity from the website. How can we use this data for personalization? Even before customers are placing their orders, can we use this information to recommend recipes? We also think ontology could help us when substituting problematic ingredients for dietary requirements, like gluten.
There are some additional areas where we’re thinking outside the box. For example, how can we take advantage of AI-based recipe development? Can we use the ontology to suggest ideas to our recipe developers? For example, if we only have two Scandinavian-inspired recipes but they are hugely popular, we may want to create more of that type of dish. Or a certain two ingredients together always seem to get a super high rating. How can we leverage this?
Everyone at Gousto is excited for all the possibilities, and this is really just the start of the journey. Hopefully, we’ll have more exciting things to share in the future.
Learn why a recommender system built on graph technology is more powerful and efficient with this white paper, Powering Recommendations with Graph Databases – get your copy today.
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher

Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report


Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.
