Storing hierarchical data can be a pain when using the wrong tools.
However, Neo4j is a good fit for these kind of problems, and this post will show you an example of how it can be used.
To top it off, today it’s time to have a look at the Neo4j Python language bindings as well.
Introduction
A little background info for newcomers: Neo4j stores data as nodes and relationships, with key-value style properties on both. Relationships connect two different nodes to each other, and are both typed and directed.
Relationships can be traversed in both directions (the direction can also be ignored when traversing if you like). You can create any relationship types; they are identified by their name.
For a quick introduction to the Neo4j Python bindings, have a look at the Neo4j.py component site. There’s also slides and video from a PyCon 2010 presentation by Tobias Ivarsson of the Neo4j team, who also contributed the Python code for this blog post.
If you take a look at a site like stackoverflow.com you will find many questions on how to store categories or, generally speaking, hierarchies in a database.
In this blog post, we’re going to look at how to implement something like what’s asked for here using Neo4j. However, using a graph database will allow us to bring the concept a bit further.
Data Model
It may come as a surprise to some readers, but even though we’re using a graph database here, we’ll use a common Entity-Relationship Diagram.
The entities we want to handle in this case are categories and products. The products holds attribute values, and we want to be able to define types and constraints on these attributes. The attributes that products can hold are defined on categories and inherited to all descendants. Products, categories and attribute types are modeled as entities, while the attributes have been modeled as relationships in this case. Categories may contain subcategories and products.
So this is the data model we end up with:

What can’t be expressed nicely in the ER-Diagram are the attribute values, as the actual names of those attributes are defined as data elsewhere in the model.
This mix of metadata and data may be a problem when using other underlying data models, but for a graph database, this is actually how it’s supposed to be used. When using an RDBMS with it’s underlying tabular model, the Entity-Attribute-Value model is a commonly suggested way of dealing with the data/metadata split. However, this solution comes with some downsides and hurts performance a lot.
That was it for the theoretical part, let’s get on to the practical stuff!
Node Space
What we want to do is to transfer the data model to the node space – that’s Neo4j lingo for a graph database instance, as it consists of nodes and relationship between nodes.
What we’ll do now is to simply convert some of the terminology from the Entity-Relationship model to the Neo4j API:
| ER-model | Neo4j |
|---|---|
| Entity | Node |
| Relationship | Relationship |
| Attribute | Property |
That wasn’t too hard, was it?! Let’s put some example data in the model and have a look at it (click for big image):

The image above gives an overview; the rest of the post will get into implementation details and good practices that can be useful.
Getting to the details
When a new Neo4j database is created, it already contains one single node, known as the reference node. This node can be used as a main entry point to the graph. Next, we’ll show a useful pattern for this.
In most real applications you’ll want multiple entry points to the graph, and this can be done by creating subreference nodes. A subreference node is a node that is connected to the reference node with a special relationship type, indicating it’s role. In this case, we’re interested in having a relationship to the category root and one to the attribute types. So this is how the subreference structure looks in the node space:

Now someone may ask: Hey, shouldn’t the products have a subreference node as well?! But, for two reasons, I don’t think so:
- It’s redundant as we can find them by traversing from the category root.
- If we want to find a single product, it’s more useful to index them on a property, like their name. We’ll save that one for another blog post, though.
Note that when using a graph database, the graph structure lends itself well to indexing.
As the subreference node pattern is such a nice thing, we added it to the utilities. The node is lazily created the first time it’s requested. Here’s what’s needed to create an ATTRIBUTE_ROOT typed subreference node:
import neo4j from neo4j.util import Subreference attribute_subref_node = Subreference.Node.ATTRIBUTE_ROOT(graphdb)
… where graphdb is the current Neo4j instance. Note that the subreference node itself doesn’t have a “node type”, but is implicitly given a type by the ATTRIBUTE_ROOT typed relationship leading to the node.
The next thing we need to take care of is connecting all attribute type nodes properly with the subreference node.
This is simply done like this:
attribute_subref_node.ATTRIBUTE_TYPE(new_attribute_type_node)
Always doing like this when adding a new attribute type makes the nodes easily discoverable from the ATTRIBUTE_ROOT subreference node:

Similarly, we want to have a subreference node for categories, and in this case we also want to add a property to the subreference node. Here’s how this looks in Python code:
category_subref_node = Subreference.Node.CATEGORY_ROOT(graphdb, Name="Products")
This is how it will look after we added the first actual category, namely the “Electronics” one:

Now let’s see how to add subcategories.
Basically, this is what’s needed to create a subcategory in the node space, using the SUBCATEGORY relationship type:
computers_node = graphdb.node(Name="Computers") electronics_node.SUBCATEGORY(computers_node)

To fetch all the direct subcategories under a category and print their names, all we have to do is to fetch the relationships of the corresponding type and use the node at the end of the relationship, just like this:
for rel in category_node.SUBCATEGORY.outgoing: print rel.end['Name']
There’s not much to say regarding products, the product nodes are simply connected to one category node using a PRODUCT relationship:

But how to get all products in a category, including all it’s subcategories? Here it’s time to use a traverser, defined by the following code:
class SubCategoryProducts(neo4j.Traversal):
types = [neo4j.Outgoing.SUBCATEGORY, neo4j.Outgoing.PRODUCT]
def isReturnable(self, pos):
if pos.is_start: return False
return pos.last_relationship.type == 'PRODUCT'
This traverser will follow outgoing relationships for both SUBCATEGORY and PRODUCT type relationships. It will filter out the starting node and only return nodes reached over a PRODUCT relationship.
This is then how to use it:
for prod in SubCategoryProducts(category_node): print prod['Name']
At the core of our example is the way it adds attribute definitions to the categories. Attributes are modeled as relationships between a category and an attribute type node. The attribute type node holds information on the type – in our case only a name and a unit – while the relationship holds the name, a “required” flag and, in some cases, a default value as well.
From the viewpoint of a single category, this is how it is connected to attribute types, thus defining the attributes that can be used by products down that path in the category tree:

Our last code sample will show how to fetch all attribute definitions which apply to a product. Here we’ll define a traverser named categories which will find all categories for a product. The traverser is used by the attributes function, which will yield all the ATTRIBUTE relationship.
A simple example of usage is also included in the code:
def attributes(product_node):
"""Usage:
for attr in attributes(product):
print attr['Name'], " of type ", attr.end['Name']
"""
for category in categories(product_node):
for attr in category.ATTRIBUTE:
yield attr
class categories(neo4j.Traversal):
types = [neo4j.Incoming.PRODUCT, neo4j.Incoming.SUBCATEGORY]
def isReturnable(self, pos):
return not pos.is_start
Let’s have a final look at the attribute types. Seen from the viewpoint of an attribute type node things look this way:

As the image above shows, it’s really simple to find out which attributes (or categories) are using a specific attribute type. This is typical when working with a graph database: connect the nodes according to your data model, and you’ll be fine.
Wrap-up
Hopefully you had some fun diving into a bit of graph database thinking! These should probably be your next steps forward:
- Neo4j main site
- Neo4j mailing list
- Neo4j getting started with Python wiki page
- Python example code
- Java example code
Share Article



Explore
Related Articles
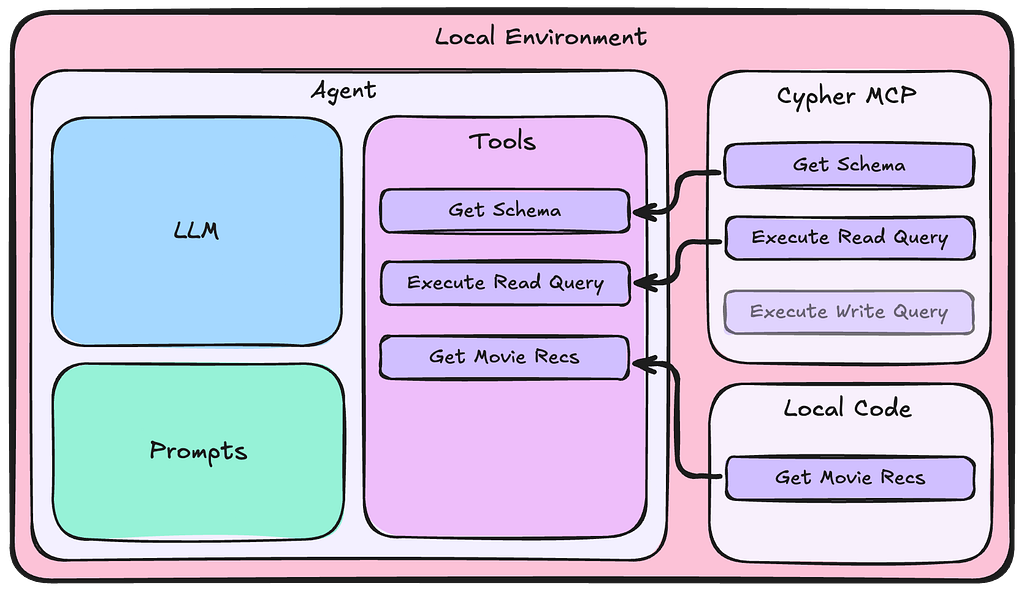
Rewire Your Integration Strategy: A Graph-First Approach With Neo4j and AI
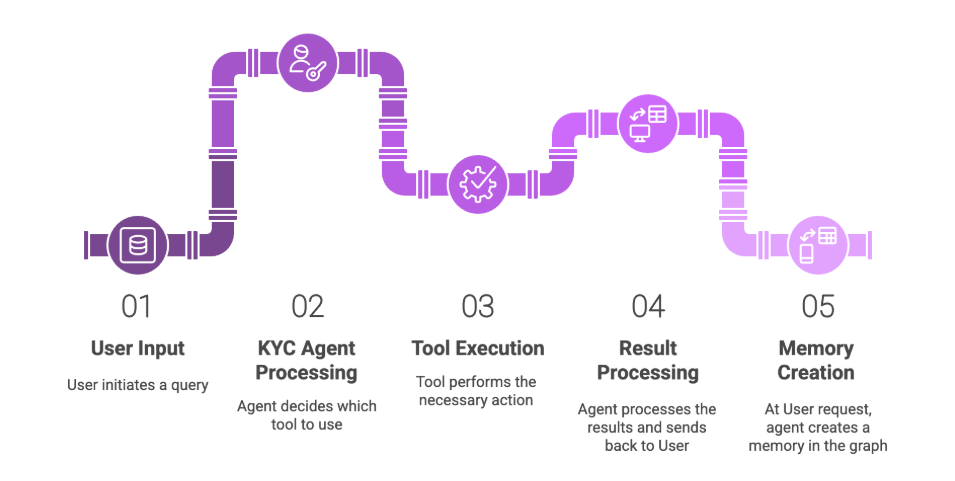
GraphRAG in Action: A Simple Agent for Know-Your-Customer Investigations

RAG Tutorial: How to Build a RAG System on a Knowledge Graph