
Native vs. Non-Native Graph Database

Graph Database Product Specialist, Neo4j
8 min read

It’s a familiar figure of speech: “Jack of all trades, master of none.”
If you’re trying to be good at everything, you end up being mediocre at most things and not exceptional at anything in particular. Software, technology, and – you guessed it – databases are no exception.
Databases satisfy all different kinds of functions: analytics and transactional workloads, memory access and disk access, SQL and JSON access, and graph and document data storage and processing.
When building a database management system (DBMS), development teams must decide early on what use cases to optimize for, which will dictate how well the DBMS will handle the tasks it is dealt with (i.e., what the DBMS will be amazing at, what it will be ok at and what it may not do so well).
As a result, the graph database world is populated with technologies designed to be “graph first,” known as native graph technology, and other databases where graphs are a bolted-on afterthought, classified as non-native graph technology.
There’s a considerable difference in the native graph database architecture of both graph storage and processing. Unsurprisingly, native technologies tend to perform queries faster, scale bigger (retaining their hallmark query speed as the dataset grows in size because most graph queries exhibit specific traversal patterns), and run more efficiently, calling for much lower hardware requirements. Non-native graph databases forgo these key benefits as they are sitting on top of a non-graph-optimized data model.
Understanding the differences is critical – especially if you’re evaluating databases for your next project. In this blog post, we’ll discuss the key characteristics that distinguish native graph database technology – and why they matter for database performance.
What Are Graph Databases All About Anyway?
Data fuels today’s businesses; we all have seen the headlines about the exabytes of data generated daily. Companies are all trying to use that data to improve their bottom line – becoming more efficient, understanding and serving their customers better, reducing risk, etc. One of the key ways they can do this is by better understanding and utilizing the connections between different pieces of data.
These connections inherent in the data are critical; they tell us about the relationships among the parties of a complex fraud ring, the relationships between the parts of our global supply chain, the tendency of a customer to buy a specific product based upon others’ purchases, etc. Machine learning use cases, in particular, rely on context in the data to make better predictions and recommendations.
Graph databases are designed to represent those connections in the data and allow their users to navigate those relationships efficiently. Modern applications increasingly rely on these relationships just as much as on the data itself. This is a primary reason why graph databases have been the fastest-growing category over the past decade.
You can read more about the workings and value of graph databases by downloading the free e-book, Graph Databases for Dummies.
What “Graph First” Means in Native Graph Technology
There are two main elements that distinguish native graph technology: processing and storage. Native graph databases are designed to both store and process data as a graph, taking care of representing graph elements as such in the storage and accessing them efficiently during processing – meaning that the “graphy” operations of navigating deep and long chains of relationships can be done quickly and efficiently.
Non-native graph databases use some other paradigm for storage and processing. Often they are legacy databases attempting to add a layer or API of graph on top of a model that wasn’t designed with these needs in mind, which means that these multi-model databases don’t have the same capabilities of a native graph database.
What’s Special About Native Graph Storage and Processing
Native graph processing refers to how a native graph database processes database operations, including both storage and queries. A key capability of a native graph database is the ability to navigate through the connections in the data quickly – without the overhead of index lookups or other join strategies. This capability to traverse the related data without the overhead of an index lookup for each move across a relationship is something we call index-free adjacency.
Non-native graph processing often needs to use index lookups to get to the next element in a chain for completing a read or write transaction; this may be okay with just one or two relationships, but in today’s use cases with hundreds or thousands, it won’t work. The complexity of an index lookup is often O(log(n)) versus the O(1) for following a direct pointer of the relationship to a target node.
Graph storage refers to the underlying structure of the database that contains graph data. When built specifically for storing graph-like data, it is known as native graph storage. Graph databases with native graph storage are optimized for graphs in every aspect, ensuring that data is stored efficiently by using storage layouts that co-locate nodes and relationships close to each other.
Graph storage is classified as non-native when the storage comes from an outside source, such as a relational, wide-column, document, or other NoSQL databases. These databases store data about nodes and relationships as unrelated entities, which may end up far apart and disconnected in actual storage. Just as with processing, non-native graph storage doesn’t meet the performance and scale needs of modern applications.
Let’s look closer at why native graph storage and native graph processing are so critical.
Native Graph Storage: Optimized For Connected Data
What makes graph storage distinctively native is the architecture of the graph database from the ground up. Graph databases with native graph storage have underlying storage designed specifically for the storage and management of graphs. They are designed to maximize the speed of traversals during arbitrary graph algorithms.
For example, let’s take a look at the way Neo4j – a native graph database – is structured for native graph storage. Every layer of this architecture – from the Cypher query language runtime to managing the store files on disk – is optimized for storing and querying graph data, and not a single part is sitting on top of other non-graph technologies.
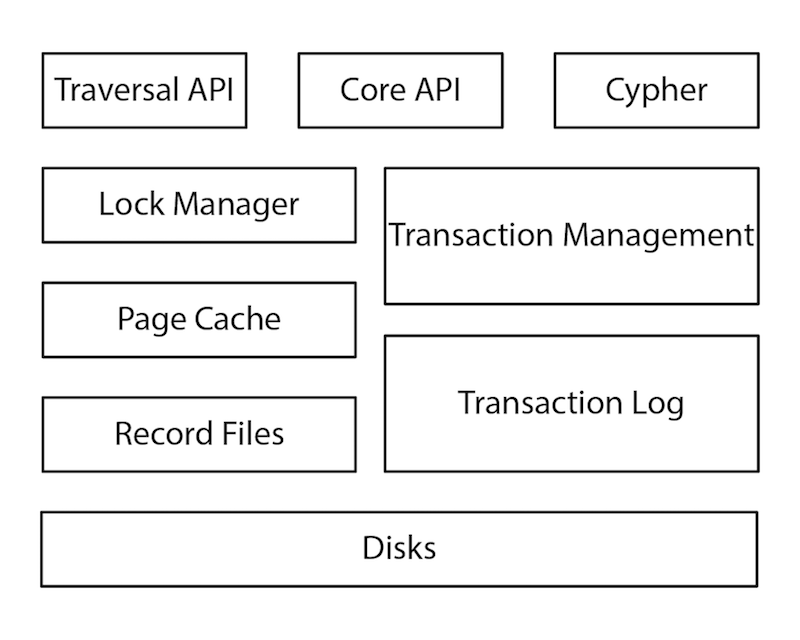
In a native graph database, a node record’s main purpose is to simply point to structured lists of relationships, labels, and properties, making it a lightweight record.
So, what makes non-native graph storage different from storage in a native graph database?
Non-native graph storage uses a relational database, a columnar database, or some other general-purpose data store rather than being specifically engineered for the requirements of graphs. They would store nodes and relationships in their native data paradigm (e.g. as tables or documents).
While the typical operations team might be more familiar with a non-graph backend (like MySQL or Cassandra), the disconnect between graph data with non-graph storage results in a number of performance and scalability concerns.
Non-native graph databases are not optimized for storing graphs, so the algorithms utilized for managing data need to update or read nodes and relationships all over the place. This then also causes performance problems at the time of retrieval because all these nodes and relationships have to be reassembled for every single query. In a 24×7 production scenario, that could be thousands of queries per second.
On the other hand, native graph storage is built to handle highly interconnected datasets from the ground up and is therefore the most efficient when it comes to the storage and retrieval of graph data.
Native Graph Processing: Index-Free Adjacency
A graph database has native processing capabilities using index-free adjacency. This means that each node directly references its adjacent (neighboring) nodes, meaning that accessing relationships and related data is simply a memory pointer lookup. This makes native graph processing time proportional to the amount of data processed, not increasing exponentially with the number of relationships traversed and hops navigated.
Without index-free adjacency, a large graph dataset will be crushed under its own weight because queries take longer and longer as the dataset grows. On the flip side, native graph queries perform at a constant rate based on the amount of data they touch, no matter the total size of your data.
Since graph databases store relationship data as first-class entities, relationships are easier to traverse in any direction. With processing specifically built for graph datasets, relationships – rather than over-reliance on indexes for joins – are used to maximize the efficiency of traversals.
See the image below of a basic social network where queries are performed on the natively stored relationship data (who is connected to whom?) without further index lookups.
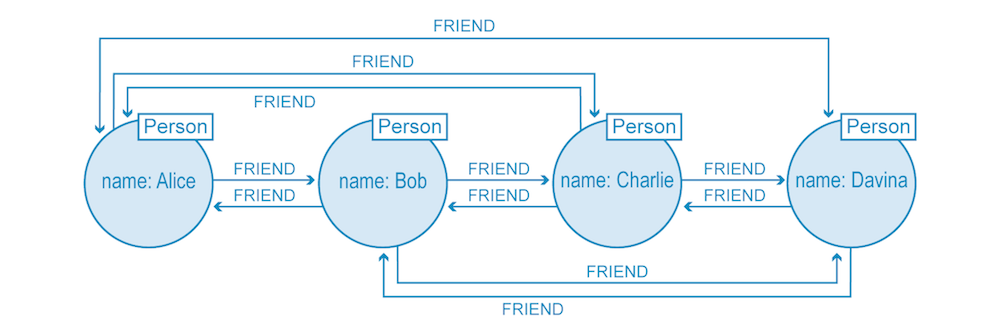
On the other hand, non-native graph databases use many types of indexes to compute the joins to link entities together. This method is more costly, as the indexes add another layer to each read and write, which slows processing considerably.
Queries with many more than one level of connection (i.e., the very type of query you’d want or need from a graph database) further reduce traversal performance with non-native graph processing.
The image below illustrates an example of a non-native graph query looking up just one level of connection (in a many-to-many relationship), each connection computing two index lookups – imagine how much the processing complexity grows as you query across more hops.
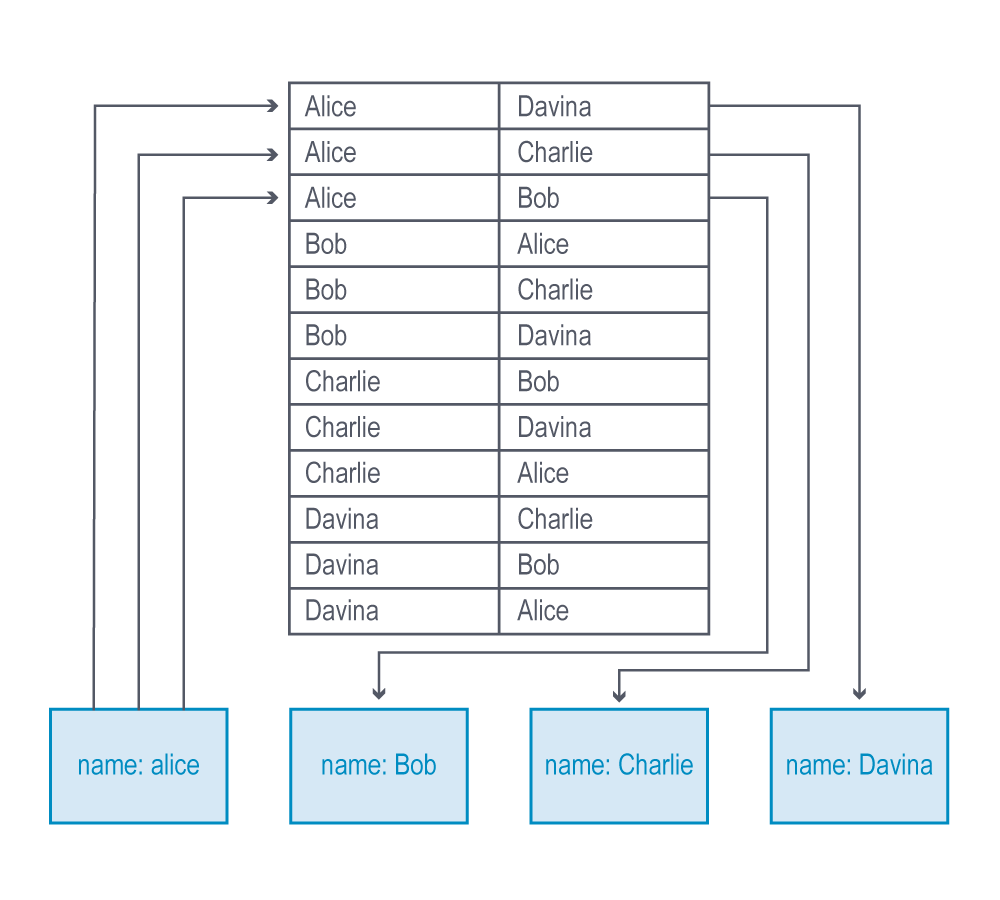
In addition, reversing the direction of a traversal is extremely difficult with non-native graph processing.
To reverse a query’s direction, you must either create a costly reverse-lookup index for each traversal or perform a brute-force forward search through the original index. Both of these workarounds will get you the result you’re looking for – eventually – but they defeat the purpose of using a graph database to begin with: to efficiently query relationships in your data.
The Bottom Line: Why Native vs. Non-Native Matters
When deciding between native and non-native graph databases, it is crucial to understand the tradeoffs of working with each.
Non-native graph technology usually has a persistence layer that your development team is already familiar with (such as Cassandra, MySQL, or another relational database), and when your dataset is small or less connected, choosing non-native graph technology isn’t likely to significantly affect the performance of your application.
However, our world is becoming increasingly connected, and data is a representation of our world. Your data is quite likely to become more connected over time. Even if your dataset is small to begin with, it’s important to plan for the future. In this case, a native graph database serves you better over the long term since the performance of non-native graph processing crumbles with larger, more connected datasets.
Not all applications require low latency or processing efficiency, and in those use cases, a non-native graph database might just do the job. (Really though, would you really use a graph database in these cases?)
But if your application requires storing, querying, and traversing large interconnected datasets in real time for a 24×7, always-on, mission-critical application (such as fraud detection, real-time recommendations, supply chain management, etc.), then you need a database architecture specifically designed for handling graph data at scale.
The bottom line: The importance of native vs. non-native graph technology depends on the particular needs of your application, but for enterprises wanting to leverage their connected data, native graph database technology is critical for success.
Catch up with the rest of the Graph Databases for Beginners series:
- Why Graph Technology Is the Future
- Why Connected Data Matters
- The Basics of Data Modeling
- Data Modeling Pitfalls to Avoid
- Why a Database Query Language Matters (More Than You Think)
- Imperative vs. Declarative Query Languages: What’s the Difference?
- Graph Theory & Predictive Modeling
- Graph Search Algorithm Basics
- Why We Need NoSQL Databases
- ACID vs. BASE Explained
- A (Brief) Tour of Aggregate Stores
- Other Graph Technologies.
Share Article



Explore
Related Articles


Text2Cypher Across Languages: Evaluating Foundational Models Beyond English



