Neo4j 3.2 GA release: Enterprise scale, native performance & more

Chief Technology Officer, Neo4j
21 min read

We are proud to announce the general availability release of Neo4j 3.2. This release marks an expansion in global scale, enterprise refinement and all-around performance. It signals that the next generation of graph-powered Internet applications will span the globe.
To this end, the themes behind Neo4j 3.2 are Internet-scale for global applications, enterprise governance and security, and performance up and down the native graph stack.
Let’s take a closer look!

Neo4j Enterprise Scale for Global Internet Applications
To get to this point and beyond, we have needed to lay an incremental foundation of capabilities delivered in previous releases.
In Neo4j 3.1, we implemented a modern, Raft-based Causal Clustering architecture that offered customers a new dimension of scaling flexibility while also providing improved redundancy guarantees.
Causal Clustering lets Neo4j separate read/write database activity across different roles within the cluster – core servers and read replicas – enabling massive throughput, read-time choice of consistency level including read-your-own-writes (RYOW), and high availability. The official drivers introduced in Neo4j 3.0 work with the binary Bolt protocol and the cluster to route queries across the cluster eliminating the need for an external load balancer.
From this foundation, we are pleased to announce that version 3.2 of Neo4j adds multi-data center support for Enterprise Edition customers looking to take their applications to the far edges of the Internet.
Multi-data center support
One of the most significant new capabilities added in this release is that Neo4j is now multi-data center aware. This allows you to more run your Internet-scale applications more conveniently across continental data centers, which is increasingly becoming a requirement for many business applications.

Earlier versions of Neo4j could be run across data centers. We have dozens of customers doing this today. However the flat cluster topology that was the worldview of Neo4j and earlier versions gets to be limiting when seeking to optimize across a broad range of real-world geographical installation scenarios.
From Neo4j 3.2 onwards, each instance in a Causal Cluster can be made aware of the topology of the network(s) onto which it is deployed. All of the drivers also share this awareness.
This enables locality-affined load balancing and the ability for cluster synchronization to minimize the expense of time-consuming updates across the WAN. Hierarchies of local subclusters speed the delivery of updates from the cluster core all the way to its most distant replica by maximizing the opportunity for local core-to-replica and replica-to-replica updates.
Multi-data center awareness is enabled with a single switch in neo4j.conf.
In Neo4j 3.2, it is now possible to subdivide clusters such that write workload is directed only to the desired data center(s). This is done by assigning core servers to Cluster Core groups, and limiting the role to Raft Follower.
This is useful for applications that need to use one or more data centers for write activity, and another one or more data centers to support read workload. This hub-satellite topology (primary + secondary) is typical of many customer’s use of Causal Clustering, and has also been back-ported to Neo4j 3.1.
Multi-data center configuration for Bolt drivers
Cluster management rules are specified in the Bolt drivers (see below), eliminating the need for application developers to write cluster routing rules within the application itself. Once multi-DC support has been enabled, you can explicitly specify that an instance can belong to zero or more server groups which typically map to physical locations.
For example a server might belong to the groups Boston, US_East, and North_America.
Note that server group membership is explicit. The server will not infer that because it is in the Boston server group that it is also somehow part of the US_East group, for example.
To explicitly declare data center-based routing behavior, we use server group configuration data, to parameterize client (application) interactions with the cluster. Multiple policies can be established for specified server groups.
Policies are the way that server groups are tied together to instruct load balancing preferences and failure rerouting. For example a policy might cause a client to read from the closest servers if there are a sufficient number available, otherwise the rule will dictate fallback to a larger or alternate set of servers.
For example, we could specify a policy called BostonClients as:
groups(Boston) -> min(3); groups(US_East, North_America) -> min(2);
This says that a client should route to one of the Boston group servers provided there are at least three available, else it should route to any US_East or North_America servers provided there are at least two live instances. This setup provides benefits in terms of latency, workload partitioning and customization of failover for continuous workload handling.
In addition to this built-in load balancing/routing feature, it is possible for customers to inject their own routing plugin, which can introduce more sophisticated load-distribution strategies. The Bolt driver interacts with the built-in server group load-balancer and with user routing plugins using an extended bolt+routing URI.
Configurable routing support in Neo4j drivers v1.3
Version 1.3 of the official language drivers for Java, JavaScript, Python, and .NET is shipping at the same time as Neo4j 3.2. The primary design goal of this driver release is to make the clustering advances from both Neo4j 3.1 and Neo4j 3.2 usable in the most convenient way possible, isolating the application from as many low-level clustering Neo4j concerns as possible.
To support server-side load-balancing, a bolt+routing URI can now accept query arguments which specify client-supplied key-value pairs, which are put into the routing/load-balancing procedure that gives back a routing table for the driver’s use.
An example URI for the built-in server groups load-balancer looks like this: bolt+routing://neo-cluster/?policy=BostonClients
From version 1.3, the Neo4j drivers are aware of server groups and will use that configuration to load balance to preferred (e.g., geographically local) servers.
In the Java code snippet below, we can see this extended URI scheme in use. Other language drivers follow the same pattern.
URI uri = URI.create(
"bolt+routing://neo-cluster/?policy=BostonClients" );
try ( Driver driver = GraphDatabase.driver( uri, config );
Session session = driver.session() )
{ // user code }
For detailed information on how to configure client-side multi-DC load balancing, please see the Neo4j documentation.
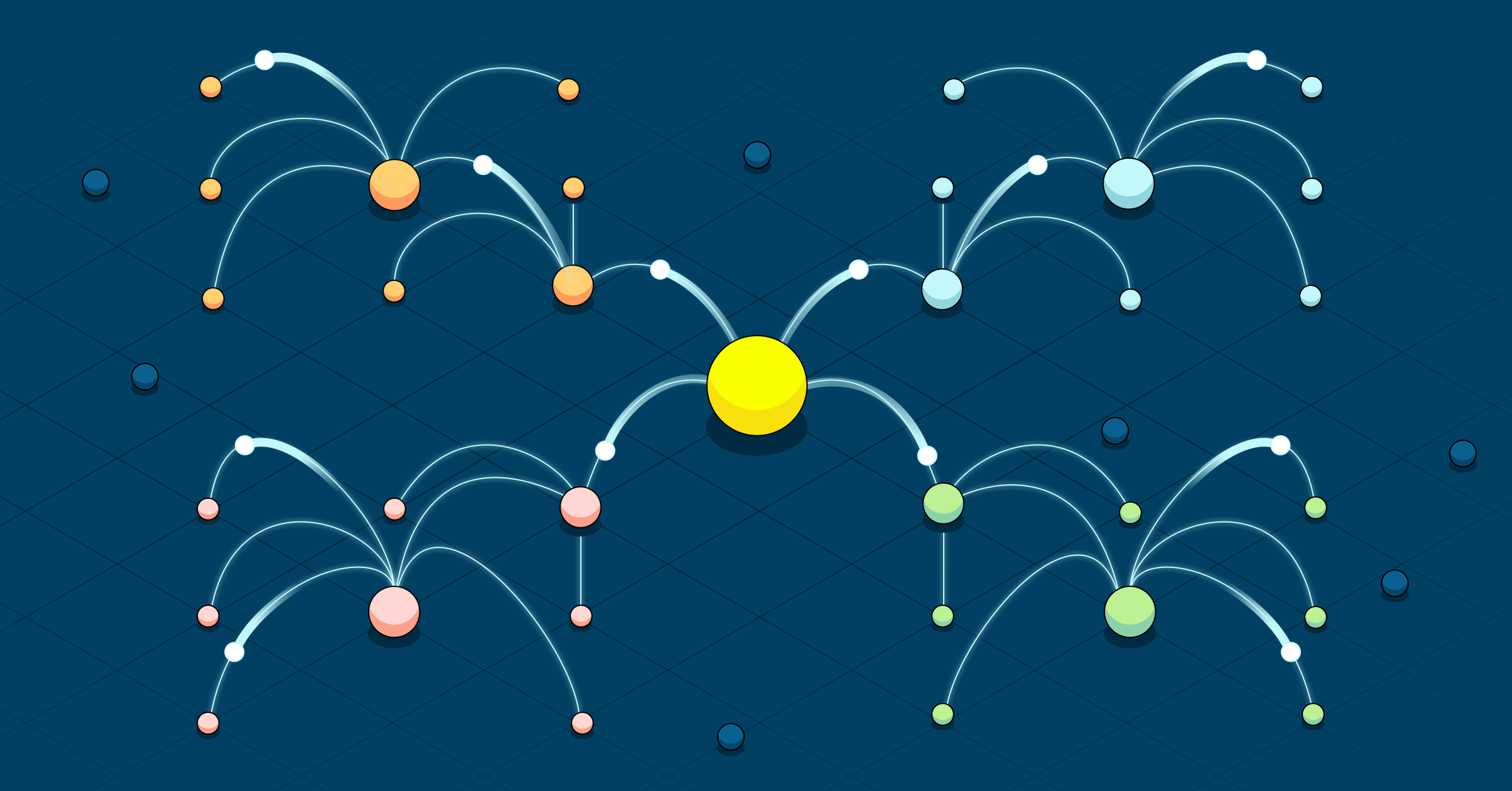
Tiered replica synchronization in data center cluster groups
Inside the cluster group itself, individual Read Replicas can be configured to catch up from any of their peers rather than just from core servers (as was the case prior to 3.2). By using server groups, you can set preferences for synchronization so that, for example, most replicas prefer to catch up from servers within their local environment and avoid using the WAN.

In the example above, two local Read Replicas catch up from the local Core Servers in Boston. They subsequently feed four other local Read Replicas in a fan out arrangement (the left box).
The Core Servers also feed two Read Replicas in Chicago which fan out to 6 more Chicago Read Replicas (the middle box). And the “root” Read Replicas in Chicago themselves feed two more Read Replicas in San Diego that feed six further local Read Replicas in a fan out (the right side box).
With this arrangement, from three Core Servers we easily feed more than 20 other database instances.
Note that several other multi-data center deployment patterns are presented in the Neo4j documentation.
Setting up the user_defined strategy uses the same configuration language as the load balancing setup we saw earlier. For example, in the San Diego data center, a Read Replica at the bottom of the hierarchy could be configured like this:
groups(SD1); groups(SD0); groups(North_America);
Which is to say it prefers to synchronize with its “parent” replica, but failing that will synchronize with its local “root” in the hierarchy, and failing that it will synchronize from any servers in the North_America group (which is all servers in this case).
Finally, while many topologies can be expressed via configuration in this way, sometimes you need a full programming language to express upstream database preferences. In those cases, there is an API for developing your own rules, typically in Java. Such pluggable rules can go beyond static topologies and mix in aspects like current load or ping statistics for example.
Operability and Infrastructure-as-a-Service improvements
To make it easier to operate Neo4j across a variety of environments, we’ve brought back RPM packages with Neo4j 3.2, and we’ve expanded the ability to deploy Neo4j in Amazon Web Services (AWS) and Microsoft Azure clouds.
Neo4j is now available in the Azure Marketplace, and a new white paper is now available that was developed in collaboration with Amazon to assist with AWS EC2 deployment.
Advanced cluster operations API
In Neo4j 3.1, the Raft algorithm that powers replication of Core Servers was kept as a black box for end users. Most of the time that’s the right choice. However some production users, especially those in a multi-data center scenario, have asked for more fine-grained control over Raft behavior.
To that end, Core Servers can now be declared as follower only which means they will never present themselves as a candidate for leadership election in Raft. The practical use of this is to confine the Raft leader to a particular preferred data center (or data centers).
Note that in enabling follower only, the Raft algorithm’s choices under pathological failures are more limited. This may impact availability.
There is also a configuration option to switch off security for HTTP endpoints in the rare event that HTTPS is unwanted. This may be required, for example, by some cloud load balancers.
Improved causal cluster-aware drivers API functions carried over from v1.2
In March, we released version 1.2 of the official Neo4j-supported drivers for Java, Javascript, Python and .NET which improves support for clients interacting with a Neo4j Causal Cluster. These features continue in the 1.3 version of the drivers, including:
- A simplified API manages transaction demarcation, database connection allocation to the appropriate cluster members for read and write transactions, and retries of transactional units of work to seamlessly hide cluster topology changes and server failures.
- DNS round-robin support allows clients to use a logical address to connect to the cluster, reducing the need for manual configuration of cluster server machines.
- Driver sessions now automatically default to linking transactions into a causal consistency chain or stream, allowing serverless or headless applications to easily obtain the improved consistency guarantees offered by Causal Cluster.
- The driver API also streamlines the ability to use existing bookmarks to extend the causal chain across several sessions in separate application servers, supporting typical web application or n-tier application topologies, giving the ultimate user agent a causally consistent view of their reads and writes.
- Both application patterns use causal consistency to overcome a key problem with the eventual consistency model, where users may not see the effects of their own prior writes or reads from one transaction to another (e.g., creating an account, but then not being able to immediately use the new account to create an order).
- Additional capabilities of the Neo4j-supported drivers are included below
CAPI flash support
Owing to the intricacies of software, CAPI Flash support was available for the High Availability (HA) architecture in Neo4j 3.1 but not for Causal Clusters. As of Neo4j 3.2, customers using IBM POWER8 with CAPI Flash now have the option of using Causal Clustering in addition to HA.

Production Governance Features
In Neo4j 3.2, we have also made the database more “enterprise-obedient” by adding an option for Kerberos authentication, as well as an important new feature for schema enforcement with the addition of Node Keys.
We’ve also expanded upon the administrative capabilities of Neo4j, giving administrators deeper insight into queries being run on the system.
New schema constraint: node key
Node Keys allow you to specify a set of properties that are mandatory and unique for a given label. Their purpose is to assure the integrity of your graph by rejecting duplicates.
This is especially useful when importing or exchanging data from multiple sources, or in larger projects, where the best practice is normally to push schema enforcement and consistency and quality rules down into the database layer.
Unlike primary keys in relational databases, there is no restriction to the number of Node Keys that can be created for a given label. Besides enforcing existence and uniqueness for a set of properties, Node Keys are underpinned by a composite index for speedy exact lookups.
Node Keys are exclusive to Neo4j Enterprise Edition.
Kerberos-based security module add-on
 In Neo4j 3.2, we introduce support for Kerberos as an optional first-class component via a new Neo4j Kerberos Add-On.
In Neo4j 3.2, we introduce support for Kerberos as an optional first-class component via a new Neo4j Kerberos Add-On.
Kerberos is a network authentication protocol that allows the network node to prove its identity over the network. It does so by using a Key Distribution Center (KDC) to ensure that the client identity is correct. The Neo4j Kerberos Add-On provides authentication and should be used in conjunction with another service, such as Active Directory or LDAP, for authorization.
Deploying and enabling Kerberos is simple:
- Place
kerberos-addon.jarin thepluginsdirectory. - Edit
neo4j.confto enable the Kerberos add-on as authentication provider. - Create a service user for the Neo4j server in the KDC and generate a
keytabfor the Neo4j service user and place it in the Neo4jconfdirectory. - Place
krb5.conffile that contains information on how to reach the KDC in the Neo4jconfdirectory - Finally, create
kerberos.confand place it the Neo4jconfdirectory
![]()

In addition to authentication security, Kerberos also supports single sign-on. This allows for granting users access to the database after signing in to the computer, simplifying credentials for the user. Look for additional blog post on ways in which to configure Neo4j with Kerberos and other applications.
Query monitoring and administration
Active queries and list active locks per query
In Neo4j 3.1, we introduced the administrative ability to view all queries that are currently executing within the instance, and for non-administrative users to view all of their own currently-executing queries on a given instance.
The following example shows that the user alwood is currently running dbms.listQueries() yielding specific variables, namely queryId, username, query, elapsedTimeMillis, requestUri and status.

In Neo4j 3.2, the information returned is being expanded to include a number of useful data points requested by both our users and our support team. An administrator is able to view all active locks held by the transaction executing the query for a given queryId.
The following example shows the active locks at the moment for all currently executing queries by yielding the queryId from dbms.listQueries procedure.

Additional questions about queries that can be answered are:
- What indexes are in use?
- How much memory is allocated to the query?
- What planner or runtime was used?
- What was query execution time and time spent waiting for locks?
Derived metric: Cache-hit ratio
A handy metric that can be calculated using Neo4j 3.2 is the cache-hit ratio. As data is returned from physical storage (flash or disk), it is cached by Neo4j in the page cache, which works to keep the most relevant data in memory.
Graph queries often involve lots of random hops. Therefore you’ll see the best results when your queries run in memory, because RAM is two to three orders-of-magnitude faster than flash.
The cache-hit ratio lets you see how much of the graph can be kept “warm” (in memory) and becomes an important guidepost for determining whether your system and page cache have been allocated enough RAM for your particular mix of graph – queries – query frequencies.
CALL dbms.listQueries() YIELD queryId, query, pageHits, pageFaults RETURN queryId, query, (pageHits * 100.0) / (pageHits + pageFults) AS pageHitRatioPercent
RPM support
We have improved the installation experience by bringing back RPM packages for both Enterprise and Community Editions, and we made cloud packages of Neo4j for Microsoft Azure and Amazon Web Services (AWS).
You can install Neo4j on any distribution, such as Red Hat, CentOS, Fedora, and Amazon Linux with simple command (as a root):
yum install neo4j-enterprise-3.2.0

Native Graph Performance
Neo4j is fortunate to own the entire native graph database stack which allows us to continuously innovate to improve performance across all areas of the database.
In the 3.2 release, we are setting a path of continuous performance improvement. Below is a summary of specific enhancements, followed by their details:
- A newly written native label index replaces the older indexing scheme to improve insertion, update and delete speeds.
- Composite exact indexes allow indexes on multiple node properties.
- Compiled Cypher runtime results in impressive query speed for basic queries. This is currently an experiment in Neo4j Enterprise Edition intended to garner feedback.
- The cost-based query optimizer fully replaces the rules-based solution, because it is always faster.
- The depth query within the Cypher
DISTINCTfunction has been dramatically optimized for deep traversals, resulting in exceptional speed improvements.

Label index improves write, update and delete speeds
When labels were introduced in 2013, we created a new kind of index to speed label lookups. While this index has served its purpose — impressive read performance — it came at a cost: dull write performance.
In Neo4j 3.2, we created our first ground-up, native index implementation for the label index, replacing the previous Lucene-based implementation. Reads are still fast, and writes are much, much faster. For graphs having lots of labels, you should notice the difference.
This sets the path to expanding the use of native indexes, especially for data types where it makes the most sense, to further improve write performance.
This marks the fourth consecutive release of Neo4j (since Neo4j 2.2) that includes improvements in write performance. Getting data into the graph is important, and this will remain a key area of engineering focus in releases to come.
Composite exact indexes
Available in both Community and Enterprise Editions, exact indexes can now be made to incorporate more than just a single property.
Composite indexes can improve read and write performance by replacing multiple single-property indexes used to support an exact match. The new Node Key schema constraint introduced in Neo4j 3.2 Enterprise Edition leverages composite exact indexes combined with a unique composite key and property existence constraints.
Compiled runtime for Cypher
Cypher performance continues to be an important theme in every release of Neo4j. In Neo4j 3.2, we are pleased to introduce a new compiled runtime for Cypher, which in this first iteration will cover simple queries, and is being made available as an Enterprise Edition exclusive.
Unlike the interpreted runtime, the compiled runtime generates bytecode for each query before it runs, speeding covered queries by an average of 300%. This initial version of the compiled runtime does not cover all queries.
From a syntactical perspective, it is able to handle most of the queries that you would see in your first hour of Cypher training, which – while a small subset of all possible queries – is nonetheless an important set. We expect that most users will have queries that will benefit from the new runtime.
Work on the runtime is continuing into the next release. Expect to see much more from these efforts in future releases as they continue.
Depth queries in Cypher
A common pattern when querying graphs is to return all connected nodes (optionally filtered by relationship type) for a specified range of depths.
Such queries typically look something like this:
MATCH (a)-[:KNOWS*1..5]->(b) RETURN DISTINCT b
Neo4j 3.2 significantly speeds up these “reachability” queries using an improved optimization technique that avoids re-evaluating nodes that have already been counted. Performance of such queries will improve in proportion to the size and density of the graph, and to the depth of the query.
Our experience shows that for medium-sized graphs, a 300% improvement was fairly typical at depth three, and that at depth four and five, performance can improve by as much as 10x.
Drivers
The 1.2 and 1.3 series driver API has applications beyond its uses with Causal Clustering.
We have added support for reusable units of work, which are exposed as transaction lambdas in the drivers. With the new retry logic (which isn’t limited to Causal Clustering), these can be “played” over a connection and replayed elsewhere if a connection fails.
In Python, they can also be parameterized. For example:
from neo4j.v1 import GraphDatabase
driver = GraphDatabase.driver("bolt+routing://localhost:7687", auth=("neo4j", "password"))
def add_friends(tx, name, friend_name):
tx.run("MERGE (a:Person {name: $name}) "
"MERGE (a)-[:KNOWS]->(friend:Person {name: $friend_name}})",
name=name, friend_name=friend_name)
def print_friends(tx, name):
for record in tx.run("MATCH (a:Person)-[:KNOWS]->(friend) WHERE a.name = $name} "
"RETURN friend.name ORDER BY friend.name", name=name):
print(record["friend.name"])
with driver.session() as session:
session.write_transaction(add_friends, "Arthur", "Guinevere")
session.write_transaction(add_friends, "Arthur", "Lancelot")
session.write_transaction(add_friends, "Arthur", "Merlin")
session.read_transaction(print_friends, "Arthur")
Here, add_friends is a unit of work that requires write access. It is called three times in the example above, each time potentially being automatically replayed should a connection fail or (in the case of Causal Clustering) the leader switch.
Units of work are a good way to organize application code as they:
- can be named meaningfully
- encourage parameterized Cypher usage
- automatically manage transaction objects (start point, commits or aborts) in the event that an exception is thrown
- can be replayed as required
Neo4j browser
We have rewritten the Neo4j Browser, as it was starting to show its age and architectural limitations. Of note is that we have replace the AngularJS framework with one similar to React.
In this overhaul, you may find anomalies, and we will work quickly to fix them and then chart a course to bigger and better capabilities of the Neo4j Browser. From the get-go, you should find the new Neo4j Browser snappier and more memory efficient.
Please send us your feedback and we’ll keep working to make the Neo4j Browser the best developer tool for graphs that you’ve ever used.
Syntax highlighting and auto-completion in the Cypher editor in Neo4j Browser
If you have gotten this far in the blog, then you will be very excited to see that as a result of the framework replacement, we can create new capabilities much more rapidly.
For example, we have also improved the Cypher editor in the Neo4j Browser to provide a more visually appealing and productive development experience by introducing syntax highlighting and auto-completion.

This makes Cypher code both easier to write and inspect, while auto-completion for labels, types and properties as well as automatic bracketing for nodes and relationships reduces keystroke errors.
Conclusion
As you can see, we’ve made Neo4j not only faster, but more globally capable and enterprise ready. Customers and community members will all see significant boosts in speed and functionality, as well as convenience.
We encourage everyone in the Neo4j graph innovation network to upgrade to 3.2 to enjoy the burst of speed and scaling improvements, and remember help is always available from our stellar community.
Download Neo4j 3.2 and take it for a spin to discover what makes it the world’s leading graph database.
Share Article



Explore
Related Articles

New research finds enterprises earn 230% ROI with Neo4j Graph Intelligence Platform
A knowledge layer for your agentic systems on Google Cloud


