Neo4j + AWS Lambda & API Gateway to create a recommendation engine

Senior DBA, SAVO Group
9 min read
The challenge of findability and why graphs?
Here at the SAVO Group, we are in the business of sales enablement via Software as a Service (SaaS). One of the tools that we provide our customers is the ability to prescribe content proactively for their sales people or sellers. We are moving past that concept and into ways that we can have content “find” sellers much quicker.
Ever since listening to Emil Eifrem on the O’Reilly Data Show talk about Neo4j, I have been super intrigued by graph technology and working to create an opportunity to use it at SAVO. As a Microsoft SQL Server DBA, the idea of connected data and the Cypher query language feel very natural to me.
At SAVO, we track all activity on the content we manage for our customers. The light bulb for me was to leverage this activity and its connected “DNA” to recommend new content to sellers based on what other sellers have used. Knowing the real-time recommendation engine use case, Neo4j felt like a natural fit for this.
Data model and Cypher query
Below is the data model.

We serve hundreds of customers (i.e., tenants), so tenant_id is important in a single Neo4j database. The basic pattern is:
(user)-[:ACTION]->(action)-[:DOWNLOADED|EMAILED|SEARCH_VIEW]->(document)
Userbeing the person acting on content, with metadata such asidandtenantActionbeing the metadata about the action record in our database such asidanddateDocumentbeing the content acted on, with metadata such asidandtenant
The key here is the additional (:action) node which gives us the flexibility for date filtering and the ability to leverage indexing. With this pattern, we can extend to other users that have consumed this document and return what else they have consumed.
Cypher query for recommendations:
MATCH (u1:user {user_id: toInt({user})}),
(d:document{document_id:toInt({document})})<--(a2:action)
<--(u2:user)-->(a3:action)-[r]->(d2:document)
WHERE u1 <> u2 AND d <> d2
AND NOT (u1)-[*2]->(d2)
AND a3.action_date >= a2.action_date
RETURN d2.document_id AS document_id,
sum(case when type(r) = 'DOWNLOADED' then 1 else 0 end) as downloads,
sum(case when type(r) = 'EMAILED' then 1 else 0 end) as emailed,
sum(case when type(r) = 'SEARCH_VIEW' then 1 else 0 end) as search_views,
count(r) as score
ORDER BY score desc
LIMIT 25
We also filter to make sure we are not showing documents to a user that they have already seen since the idea is to bring unseen content to the user.
Enter AWS Managed Services and EC2
SAVO is currently in process of moving new and existing applications and infrastructure to Amazon Web Services (AWS). This presented the optimal opportunity to display the awesomeness of graphs and how a recommendation engine could be created very quickly with AWS, specifically using managed services like Lambda and API Gateway instead of spinning up new VMs or adding to existing applications. (I also get to progress with learning AWS and Neo4j all at once – win-win!)
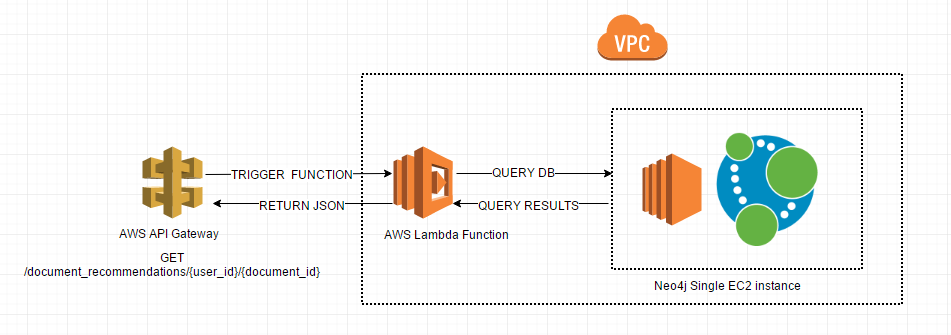
The architecture for the proof of concept looks like this:
The EC2 instance is a very simple m3.medium built from the Ubuntu 14.04 AMI inside of a default VPC we have set up in SAVO’s scratch account, which we use for POC work and various types of exploration. I set up the EC2 instance with a security group that limits Neo4j Bolt driver port access at 7687 to another security group that I will use later on. Also I added a 30GB EBS drive and then installed Neo4j per the Ubuntu installation documentation.
Here is how Amazon describes Lambda and API Gateway:
AWS Lambda lets you run code without provisioning or managing servers. You pay only for the compute time you consume – there is no charge when your code is not running. With Lambda, you can run code for virtually any type of application or backend service – all with zero administration. Just upload your code and Lambda takes care of everything required to run and scale your code with high availability. You can set up your code to automatically trigger from other AWS services or call it directly from any web or mobile app.
Amazon API Gateway is a fully managed service that makes it easy for developers to create, publish, maintain, monitor and secure APIs at any scale. With a few clicks in the AWS Management Console, you can create an API that acts as a “front door” for applications to access data, business logic or functionality from your backend services, such as workloads running on Amazon Elastic Compute Cloud (Amazon EC2), code running on AWS Lambda or any web application. Amazon API Gateway handles all the tasks involved in accepting and processing up to hundreds of thousands of concurrent API calls, including traffic management, authorization and access control, monitoring and API version management. Amazon API Gateway has no minimum fees or startup costs. You pay only for the API calls you receive and the amount of data transferred out.
Using Lambda, which supports Python 2.7, along with the Neo4j Bolt driver and API Gateway, I am able to turn my Cypher query into a fully functional microservice. Leveraging Amazon’s awesome documentation makes it quite easy to set this up.
I set up the Lambda function to work within the same default VPC stated above and added the security group that is allowed access to the Bolt driver port in order to keep the communication between our database and the Lambda function private and isolated. I upped the default timeout to 30 seconds, just to be safe.
With Lambda you can upload any dependent Python packages along with your code as a ZIP file. For this project, the .py file and the Neo4j Python Bolt driver are manually packaged into a ZIP file and uploaded to Lambda via the AWS Console.
Example files and ZIP package:

Lambda console for uploading ZIP package:
The Python code in the package:
from __future__ import print_function
from neo4j.v1 import GraphDatabase, basic_auth
def get_recommendation(event,context):
results = []
user = event['user_id']
document = event['document_id']
driver = GraphDatabase.driver("bolt://", auth=basic_auth("neo4j", "neo4j"), encrypted=False)
session = driver.session()
cypher_query = '''
MATCH (u1:user {user_id: toInt({user})}),
(d:document{document_id:toInt({document})})<--(a2:action)<--(u2:user)
-->(a3:action)-[r]->(d2:document)
WHERE u1 <> u2 AND d <> d2
AND NOT (u1)-[*2]->(d2)
AND a3.action_date >= a2.action_date
RETURN d2.document_id AS document_id,
sum(case when type(r) = 'DOWNLOADED' then 1 else 0 end) as downloads,
sum(case when type(r) = 'EMAILED' then 1 else 0 end) as emailed,
sum(case when type(r) = 'SEARCH_VIEW' then 1 else 0 end) as search_views,
count(r) as score
ORDER BY score desc
LIMIT 25
'''
result = session.run(cypher_query,{'user':user,'document':document})
session.close()
for record in result:
item = {'document_id':record['document_id'],
'downloads':record['downloads'], 'emailed':record['emailed'],
'search_views':record['search_views'], 'score':record['score']}
results.append(item)
return results
The actual EC2 instance DNS name is omitted in the above example. Both that and the Neo4j username and password are hard-coded in. A better way to this in the future would be to pass these values in at runtime. This could be accomplished by calling an S3 bucket or RDS instance, both encrypted at rest, and pulling the appropriate values into the Lambda function when triggered.
You will notice that I had to use encrypted=False in order to authenticate into Neo4j. Using encrypted=True would not work because we do not have ability to leverage a known_hosts file or signed certificate using Lambda. At this point we will rely on the protection of the AWS VPC. The signed certificate option may work with Node.js driver, but that is out of scope for this example.
Once this is working, we set up the API Gateway to integrate with the Lambda function via a GET request that will send user_id and document_id and return recommendations.
In API Gateway, we add a document-recommendations resource and a {user} and {document} GET method. The brackets allow us to send the ids as a part of the request.
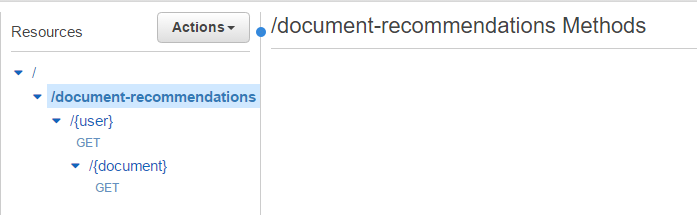
On the {document} method, we integrate with our Lambda function to send user_id and document_id and receive recommendations.

Once we have this set up and tested, we deploy to a stage and get our very own API endpoint.
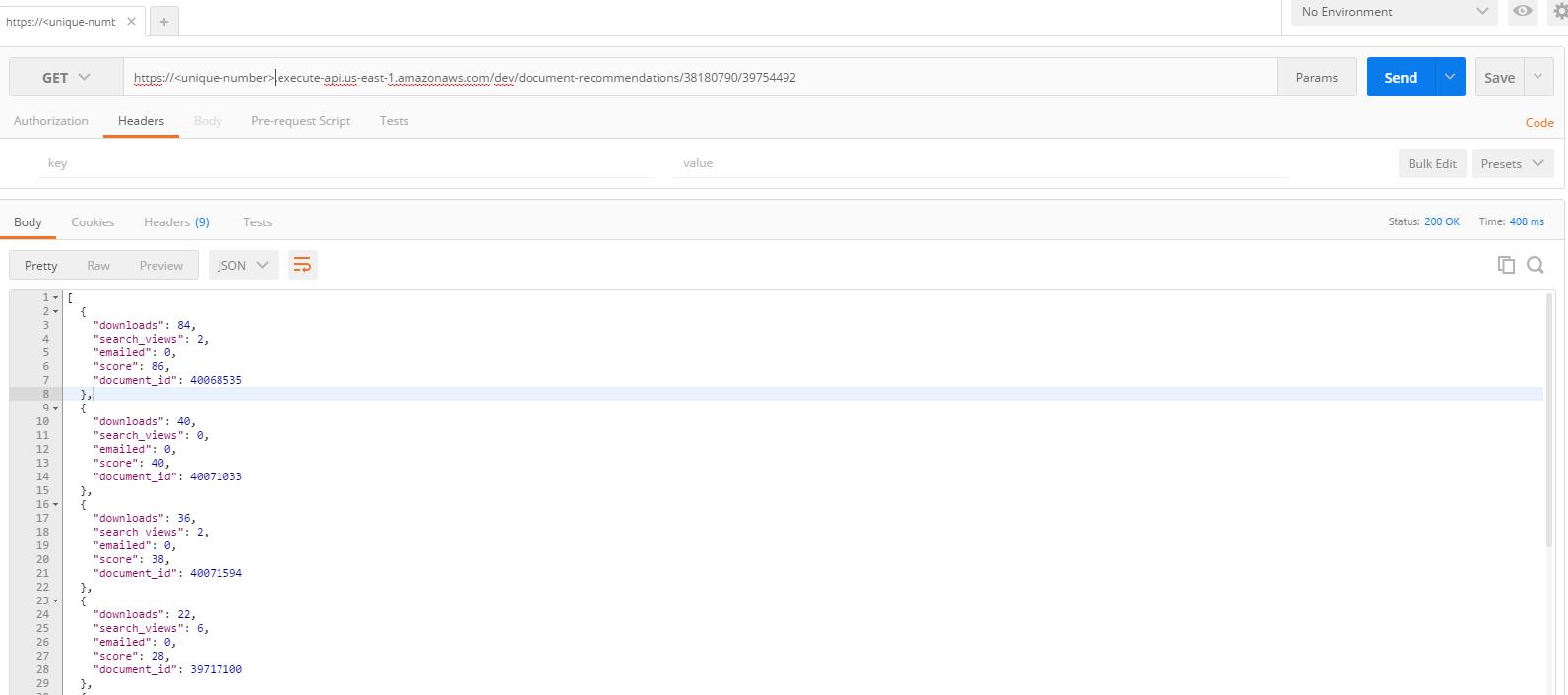
To test things, I opened up Postman, executed my HTTPS API endpoint with user and document values, and through the magic of AWS and Neo4j, we have recommendations in less than 500 milliseconds!
Next steps
I am really passionate about Neo4j and love working with graphs. My hope is that this POC can grow into a fully-fledged content recommendation engine with many endpoints for various flavors of recommendations.
Currently, there is a lot of manual setup involved. I envision that the production version would be an HA cluster with automated deployment of AWS components and code via some mix of Cloudformation and Jenkins.
We are also using the default Neo4j password in this example, as well as the default settings for API Gateway. In future, I would potentially leverage password encryption in AWS to get a password at runtime. API Gateway also gives us the ability to use an “Authorizer” to control access, which is something we will explore.
In conclusion, this was such a cool example to get up and running and really only took a few hours, since I already had some sample Cypher and a zipped-up copy of my local database. I think this is a credit to how accessible Neo4j and AWS are. I look forward to building more graph-based solutions in the future.
The world of graph databases truly is wonderful and they are indeed everywhere…even on AWS 🙂
Take the Neo4j Certification exam and validate your graph database skills to current and future employers and customers. Click below and get certified in less than an hour.
Share Article



Explore
Related Articles


Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.



Unlocking high-conversion recommendations with graph analytics in Snowflake
