Accelerating Neo4j with CAPI SNAP from IBM Power Systems

IBM Distinguished Engineer, CAPI Enablement Lead
6 min read
The longtime promise of dramatically accelerated computing has arrived on IBM Power Systems servers and the great news is that Neo4j benefits tremendously!
I’m sure many people have heard of using GPUs as selected application accelerators. The “what’s new” is now with CAPI and OpenCAPI. IBM Power Systems has brought to market the best FPGA accelerator technology available in the industry.
We also deliver other critical capabilities with CAPI: server security, address translation and virtualization, on top of the highest bandwidth and lowest latency with PCI-E Gen4 and then the 25GB/s OpenCAPI link.
The challenge is turning this technology leadership into client value. For that, we need to enable the ecosystem to create complete accelerated solutions. Remember, in the data center, our clients buy servers to run specific applications and databases (like Neo4j graph algorithms), and then they look for the server with the best price/performance, scaling and qualities of service for those applications.
To address that challenge, the OpenPOWER consortium created the CAPI SNAP toolset specifically for application developers. CAPI SNAP allows programmers to port their code to the CAPI platform and quickly get acceleration results. We are catering to their skill set to ease the “jump” to FPGAs.
Neo4j embraces acceleration
Even before the CAPI SNAP toolkit, Neo4j embraced acceleration with CAPI Flash (a.k.a., IBM Data Engine for NoSQL) on POWER8. CAPI Flash adapters remove the complexity of the I/O subsystem, so that an accelerator can operate as part of an application. It results in a code path reduction, because applications can interact with the Flash accelerator directly without using the operating system kernel.
As stated in the Neo4j on IBM POWER8 datasheet, “The combination of Neo4j’s native graph processing and storage and POWER8’s in-memory vertical scalability is a natural convergence. Neo4j on IBM POWER8 makes it possible to store and process massive-scale graphs in real time – a problem that was simply unsolvable only yesterday.”
With this kind of partnership already in place, the clear next step is to take Neo4j + POWER acceleration to a new level using CAPI SNAP.
With the strong POWER acceleration roadmap well documented for all to see, we’ve spent quite a bit of time analyzing the use cases for CAPI, CAPI 2.0 and OpenCAPI for databases as a whole, and Neo4j, in particular.
Our pipelines to large data stores are getting much wider, while our latency is decreasing, placing the FPGA square in the path of the data and the processor. But merely transporting data doesn’t leverage the CAPI attached FPGA to its full potential, so we’re looking to step-up our acceleration and add functionality to the pipeline.
That functionality comes in two forms: adding data filtering, and performing faster memory access through understanding of the data structures.
Accelerating data filtering
For data filtering, the FPGA is a perfect platform to perform Neo4j graph algorithms. With CAPI Flash already enabled, Neo4j’s large graph databases reside behind the FPGA in low-latency flash storage. As Neo4j pulls new data into the server, the CAPI SNAP enabled FPGA will be able to perform some of these algorithms on the data. This provides three major benefits compared to legacy methods:
- The FPGA will perform data filtering an order of magnitude faster than doing it in software.
- Rather than sending the entire data set across the link to the host processor, we send less data which gives us even lower latency.
- Because we are not filling memory with unfiltered data, we make much better use of the expensive main server memory.
You can view an example of this filtering, using an intersection of two arrays, in this short video:
With CAPI SNAP, it’s far easier to port these algorithms to the FPGA than ever before. The SNAP infrastructure contains all the logic to manage job requests from multiple queries, and move the requested data from source to destination.
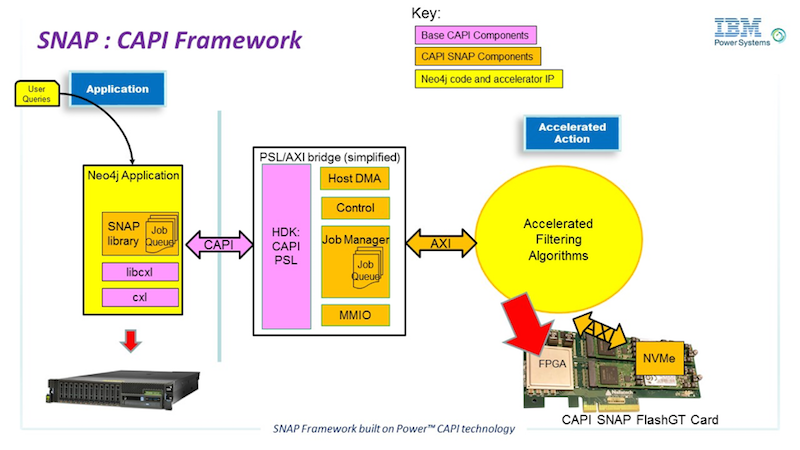
That infrastructure logic is shown in orange in Figure 1 (below): SNAP Infrastructure for Neo4j acceleration, with job management components on both the host application side as well in the FPGA along with the accelerated action. The industry standard AXI bridges move data to/from the NVMe and the host. The Neo4j algorithm (or multiple algorithms) gets compiled as actions, and the host application can then treat the actions as basic function calls.
Figure 1: SNAP Infrastructure for Neo4j acceleration
Accelerating memory access
The base CAPI Flash adapter, available today on POWER8, is certainly considered an accelerator for memory access. It provides fast access to flash storage of anywhere from 2TB to 56TB of data, i.e., enterprise-level database sizes. But with CAPI SNAP, we’re looking to improve even further on memory access.
By understanding the read data patterns inherent in Neo4j database storage structures, we are experimenting with new SNAP action code to perform speculative pre-fetching of data from CAPI Flash. Our experiments show that we can cut the observed latency of a block read by 70% on requests that we have pre-fetched.
Pre-fetched data gets temporarily placed in the on-card DRAM until the Neo4j query asks for that block. The DRAM access time is far less than the flash, so if we’ve pre-fetched the data block, we can return it much faster.
Therefore, the brains of the operation are in the pre-fetching algorithm and correctly predicting which blocks the Neo4j query will request in the near future. With our deep partnership, Neo4j and IBM engineers have created a base algorithm for pre-fetch prediction, and are continually working to make it smarter.
Next steps
Look for exciting new accelerated database products around IBM’s upcoming POWER9 launch. The cost vs. performance benefits are tangible as the solutions continue to grow the realm of “possible” in the cognitive space. Neo4j’s graph databases are at the forefront of both intelligent computing and use of acceleration technology, so expect more and more capability from the Neo4j solutions running on IBM Power Systems.
In the meantime, you can learn more about CAPI SNAP and start your own acceleration journey here.
Look for new content as we put more example code on our CAPI SNAP open source repository here.
And finally, check back often, as we have hands-on tutorials in the works for CAPI SNAP developers.
IBM is a Gold sponsor of GraphConnect New York. Use discount code IBMCD50 to get 50% off your ticket.
Get your ticket to GraphConnect New York and we’ll see you on October 24th at Pier 36 in Manhattan!
Share Article



Explore
Related Articles

1 of 3: The difference between a graph, a knowledge graph, and a context graph

2 of 3: Why graphs, knowledge graphs, and context graphs matter to customers

3 of 3: The graph ecosystem: Bringing connected context to enterprise AI

Digital twins that learn: connected asset intelligence with Neo4j and Databricks

Building retail assistants customers can trust with Databricks and Neo4j