
Neo4j and Cloud Foundry

Platform Architect, Pivotal
17 min read

Editor’s Note: This presentation was given by Jenny McLaughlin at GraphConnect New York City in September 2018.
Presentation Summary
Jenny McLaughlin is a senior platform architect at Pivotal. In this chat she discusses how developers are best able to deploy and operate their applications and services quickly with the help of Pivotal Cloud Foundry and Neo4j.
Developers love software. They want to get feedback quickly, improve it and send out an updated version as quickly as possible. Unfortunately for all parties involved, a href=”#Deploying”>deploying apps is very slow. Often the deployment process alone can take months and this timeline is very standard.
This is why Pivotal switched to Cloud native. Cloud native is really about deploying your applications or services in a more timely manner and being able to push continued delivery from functional testing environments to user acceptance testing environments. Once users are satisfied, the code will automatically be pushed to performance testing.
DevOps brings devs and ops together, and is responsible for the application. They take ownership of the application and aim to do what is best for it. The DevOps team will integrate microservice architecture into the platform to improve speed to the market, scalability and resilience. Next, you will need a cloud native platform to glue all of the components together. Pivotal Cloud Foundry is that structured cloud native platform and is infrastructure agnostic.
McLaughlin shares a handful of demonstrations with the Spring Boot application called Movie Graph. She pushes the demo to Pivotal Web Services public cloud and uses a user-provided service to connect Neo4j Enterprise to Google Cloud.
After the demonstration, McLaughlin highlights some of the features mentioned. These features include 12-factor applications for writing microservices in a cloud environment, codebase, dependencies, configurations, backing services, logs and legacy applications.
In order to deploy and operate applications and services quickly, Pivotal Cloud Foundry has been incredibly useful. However, in order to store and retrieve connected data quickly, McLaughlin recommends Neo4j.
Full Presentation
My name is Jenny McLaughlin. I’m the Senior Platform Architect at Pivotal. Today we will be talking about Neo4j and the Cloud Foundry – from speedy app development to a speedy graph database.
Developers Love Software
Let’s talk about what we really want to talk about, which is what developers love. We love our softwares.

We love it so much, and we want to send it to the world. We want to get quick feedback, make changes and give it back to the world.

Ideally, we want to be able to deploy new features daily to production. Maybe you want to deploy new features hourly or maybe you want to be like Amazon. They deliver their new features to production every 11 seconds.

For the sake of our example, let’s say daily. Think about what that would let us do in terms of how our business delivers value. It’s all about that faster feedback loop. Also, we want everybody to focus on outcome instead of individual activities. Instead of saying “Let’s build a web page or adding schemas to our database,” let’s just say “I want all the passer-bys at Time Square tonight to sign up for that weekend special program.” I want my teams to be really aligned with the business outcome, kind of like DevOps. I want my softwares to be loosely coupled so I can make components out of my applications. I update them independently so I am able to go quicker.
Data is everywhere: user-generated data, machine-generated data, the velocity, variety and volume of the data, it all comes to organizations at a phenomenal speed. It doubles in size every two years. We want to be able to store and retrieve the data efficiently, and we want to be able to have some database to ingest the data in different kinds of forms without compromising performance.
I want to have my middleware and hardware to be self-serviced and automated. If I have to go through the manual process to spin up VM, web sphere and things like that, I’m not going to be able to do my daily deployment anymore. I want to be able to scale things out and back in quickly – and hopefully for free. I want to be able to upgrade my software with absolutely no down time. Facebook and Netflix never have down time, neither should we. We have global customers.
Plus, it’s really dangerous to have that change during a window in the middle of the night. Folks are tired and grouchy, we tend to abort our effort if something goes wrong. Instead, let’s do an upgrade in the middle of the day, where everybody is happy and we’re at our peak performance. Then, if we have to go back, that’s okay. We do everything in a no-down-time way. I want my applications to be highly available, resilient and any failing components are able to be automatically resurrected.
Deploying Apps Is Slow
In reality, things aren’t that easy. Sometimes deploying applications is very slow. Think about a typical application development team in an organization. We usually support many applications.
Let’s say our marketing team has this new idea and they want us to work on it until it’s done. Of course our software is never done, it’s just a release. Until it starts to get in front of the customer we’re either making money or we’re losing money.
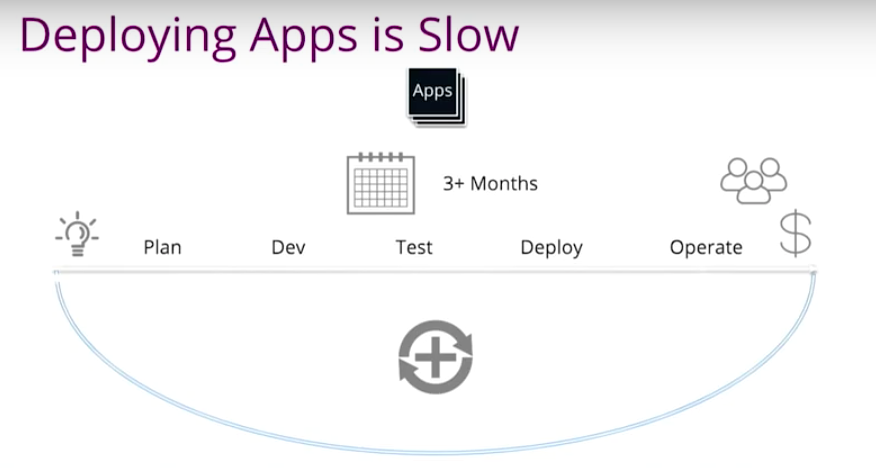
Between the idea to production, we have to go through planning, development and testing, deploying and monitoring the application production. That could take months.
On the development side, we decided to do agile. We do some continuous integration, SCRUM daily stand ups and we do unit testing. Developers are checking the code and kickoff the build. If it passed, great. If it fails, we will get a notification saying, “Hey, you broke the encode – go fix it.”
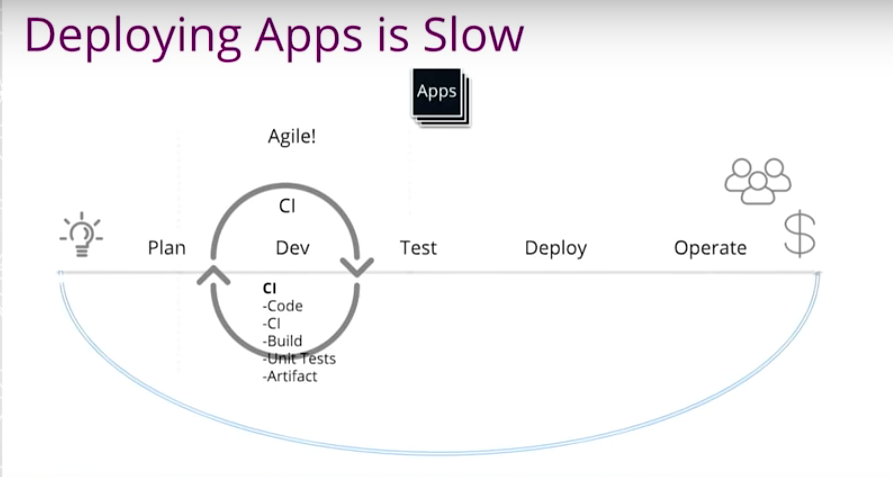
That’s pretty standard. However, the problem is too narrow. We still have a separate QA team that’s going to do testing in an integration testing environment, functioning testing environment, user acceptance testing environment and performance testing before we go to production.
For each testing environment, we have to spin up the VM, install OS and Websphere Tomcat. If you’re in the Windows world, that would be an IF server, Network F5. DNS certificates hook up to the back-end database. Plus, we have to do some configuration, deploy the code and do the testing. We have to do this for every environment.
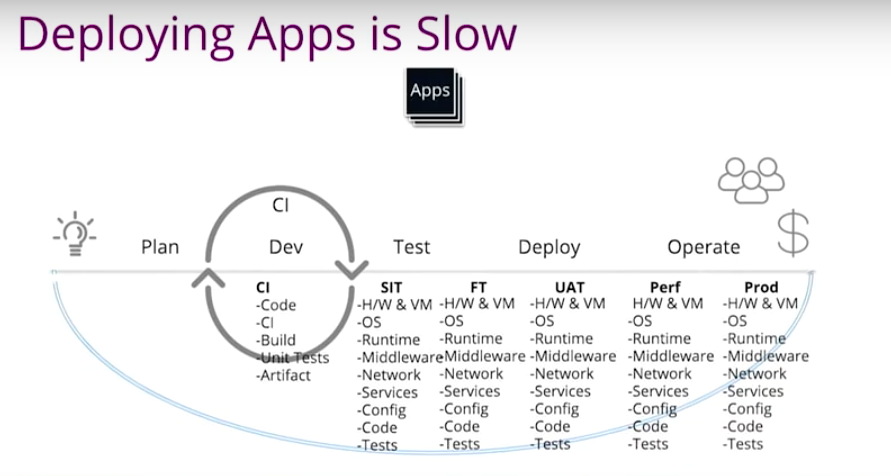
The funny thing is, if somebody is doing a security patch for upgrade, or if I am unable to do testing anymore – or if somebody accidentally changed my artifact, my JAR file or configuration or security policy on Windows server – the environment is useless.
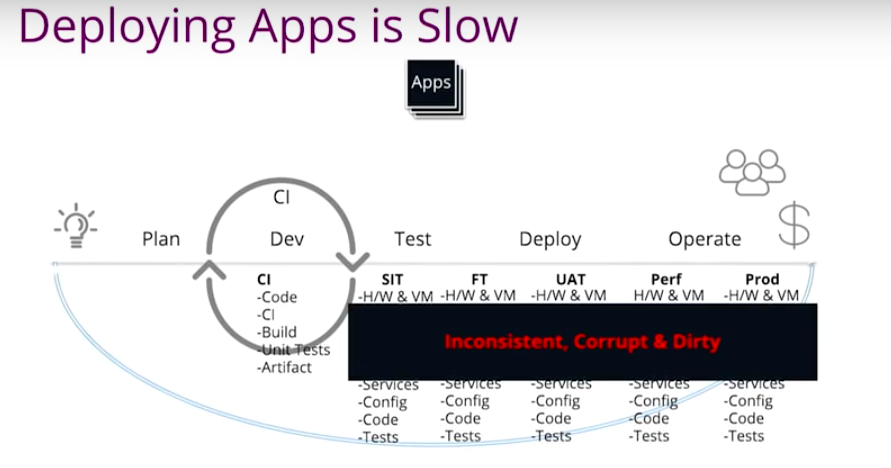
The environment becomes inconsistent, corrupt, dirty and just useless. What’s the point of testing?
Even though we have SCRUM on the development side, the whole process is a waterfall. Now we have water SCRUM fall, which still takes months from development to deployment. That’s pretty frustrating.
From the operator’s perspective, things are not necessarily better either. It still could be slow.

For patching and upgrading, someone has to write the scripts, and somebody has to apply the scripts in different environments. Most likely that’s going to involve outage.
An operator has to consider, if there’s no single point of failure. We have to set up clustering. We have to figure out how to scale and make it highly available and consider security, those kinds of things.
The problem is that all these things don’t add much business value. If you think about it, it’s just below the value line.
At the end of the year, your CIO is not going to pat your shoulder and say, “Oh, great job patching that server.” With all of the frustrations, there’s got to be a better way. We want to be better at this.
Cloud Native
We want to iterate fast and, of course, everybody knows cloud native.
Cloud native is a buzzword going around for several years. It’s not about running your workloads on someone else’s data center. It’s really about deploying your applications or services in a totally different manner, by significantly reducing that development-to-deployment cycle time.
Cloud native has three components: continuous delivery, DevOps and microservices.

They are necessary components, but they require a cloud-native platform to glue them together.
Continuous Delivery
Going back to our story where we push this idea to production, continuous delivery is that extension of continuous integration. It’s all about having that consistent automated platform where each and every environment is as close to identical as possible. Instead of having that corrupt environment, now we have a platform where everything is automated.
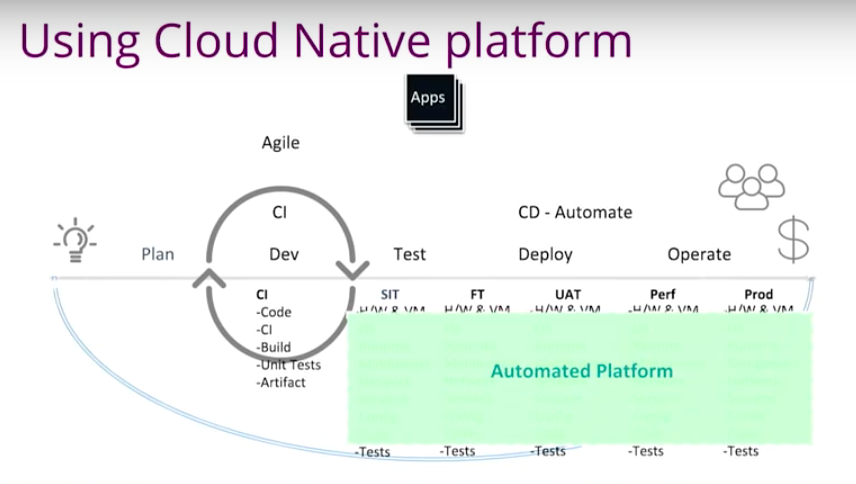
The VM should automatically spin up and OS should be automatically installed.
When developers check in the code, it’s going to kick things into overdrive. An artifact will be created. It will be automatically promoted to the integration testing environment. You’ve still got to write your test scripts, but that could be automated. You run your test scripts and pass. Everything is automated. The code gets promoted to a functional testing environment, then to the user acceptance testing environment. There will be pause here because we need human interaction at this point, but at least your environment is ready.
Your users come, test it and hit that green button. It’s going to automatically promote the code to the performance testing environment. You could either automatically promote to production. Or you could let your product owner decide at that point another pause. Everybody will have a high degree of confidence before a new release goes to production because it has gone through all these steps.
DevOps
DevOps is that extension of the agile team, bringing Devs and Ops together. We’re responsible for the application. It takes the team’s overall ownership. Therefore, they are going to do what’s the best for the application and ultimately what’s best for the business.
This automated, cloud-native platform enables DevOps more than anything else. It helps remove the friction.
Microservices Architecture
Microservices are loosely coupled services with bonded context.
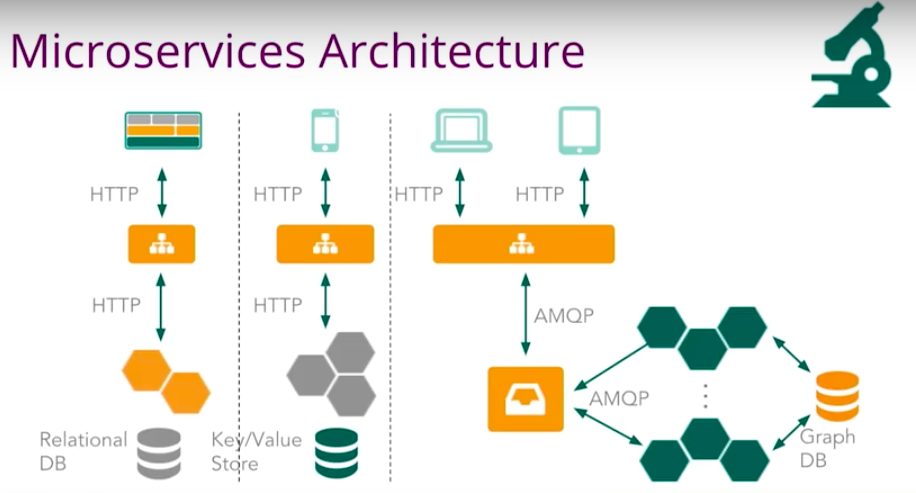
This platform helps improve speed-to-market, scalability and resilience. Each microservice interacts with each other through certain types of APIs, usually language agnostic.
Each microservice has its web tier, theta tier, service tier, data tier and back-end database. If they have to make a change, everything is within the same team’s control. The team really meets their own business needs and controls their own destiny.
Pivotal Cloud Foundry
Like we mentioned earlier, we need a cloud-native platform to glue all these components together. Pivotal Cloud Foundry is that structured cloud-native platform, and it is infrastructure agnostic.
As you see, Cloud Foundry runs consistently across different IAAS. Whether it’s Vsphere, Open Stack, AWS, Google Cloud, or Azure and there’s this layer called BOSH.

BOSH is an open source tool. It’s all about deploying and managing distributed systems. BOSH interacts with different clouds through cloud CPI. It takes care of a lot of operational challenges, like provisioning, monitoring, updating and patching. If there’s any failing processes and components, it’s going to resurrect back up automatically and restore it to the correct state.
That is powerful because you continuously deliver all of these distributed systems from version one to version two to version ten without any downtime.
Also, you are able to patch things on the fly. Everything just goes smoothly. That’s the operational control – it’s very powerful.
Now we have the ability to deploy and manage distributed systems. The first distributed system is right here, Pivotal Application Service.
This is pretty much Cloud Foundry, where developers do the app push and push their code to Cloud Foundry.
Another aspect is PKS. Pivotal Container Service, the K refers to an enterprise scale of Kubernetes. It makes cluster provisioning a matter of minutes operation and also seamless patching and upgrading. If you have pre-packaged applications, third-party vendor software, or some backing services, PKS is able to manage those things for you. Pivotal Function Service brings function to the Cloud Foundry context. It really allows you to do functions and events behind your firewall, in enterprise, not in public cloud.
You could start tapping those network and database events. Instead of using random shell scripts, now you are able to turn them into functions and support multiple languages or run in different clouds.
The last pillar is Pivotal Services Marketplace.
This is where you connect your applications with different backing services. Speaking of backing services, in Cloud Foundry we are talking about data stores, messaging queues and caches.

There are two types of services: one service is BOSH-managed and the other one is externally managed.
Remember, BOSH is all about deploying and managing distributed systems. BOSH is able to manage your back-end service. If you don’t have that service to be BOSH managed, something else manages the life cycle. We do this by using this important and pretty simple API called Open Service Broker API.
The service broker is going to reserve all the resources for you and give you connection information. From the developer perspective, it’s just an end point.
Now we have to look at some database services and data stores. Most developers are familiar with asset transactions from working with a relational database.
Traditional databases require us to create a logical model and force the structure into a tabular physical model. Foreign keys and JOIN tables reflect those relationships.
Joints aren’t that bad if you just have two or three hops. However, if you have lots of hops, that could jeopardize your performance and sometimes the results may never get fully calculated.
If you look at the below tables, we want to know what products Alice purchased.
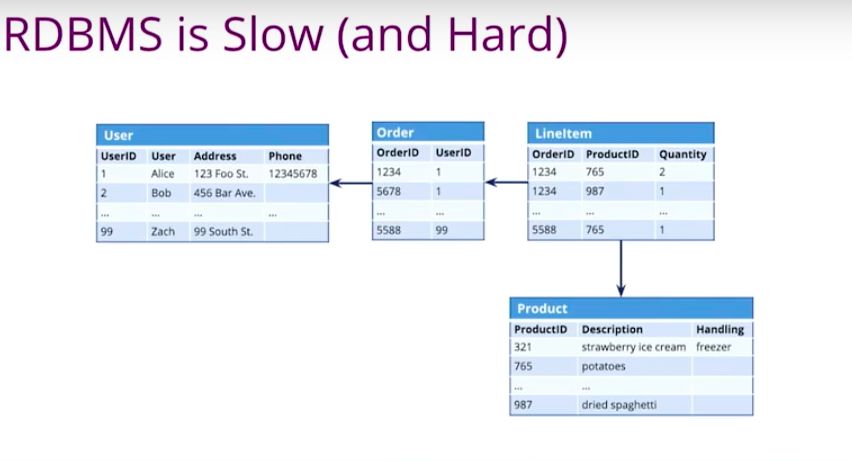
This would probably take a couple hops, JOINS, and we get the results. However, if we want to ask the question “Which customers bought strawberry ice cream?” that could be an expensive query.
Another aspect of a relational database is that it’s not meant to be able to keep up with the click-business change requirements because it’s richer and more complex than data modeling.
If you need to have a huge amount of data and your business requirements constantly change, a graph database is a better choice because it puts the data relationship in the center. If you want to add a new node or new relationship to an existing graph, it’s not going to impact the performance.
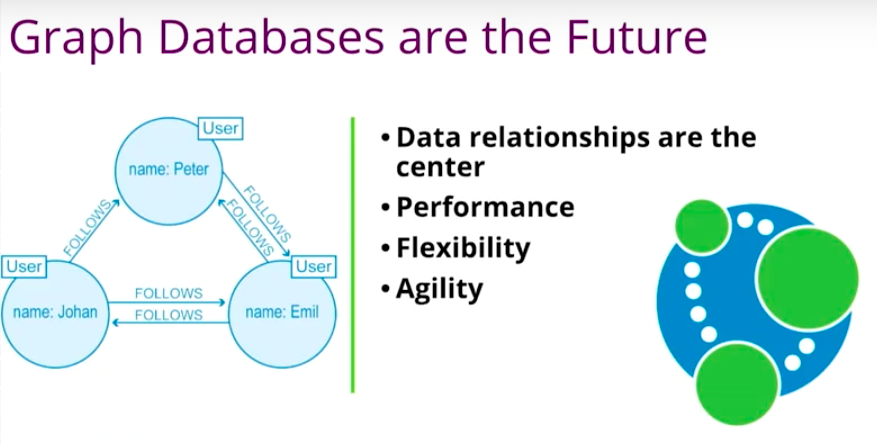
Queries are very efficient, even though some queries are deep and complex. Neo4j definitely leads the effort in this space in terms of graph processing and graph storage.
If you want to run a graph database in production, Neo4j Enterprise Edition is the way to go. Not only does it provide developers design and developing tooling, it gives operators benefits in terms of availability, performance, security, monitoring, et cetera.
Demonstrations
Let’s do a demo.
What we’re going to do here is we are going to have the spring boot application called Movie Graph. By the way, spring boot is a Java framework. It’s a very opinionated way of building microservices, in case you’re not familiar.
We’re going to push it to Pivotal Web Services. This is Pivotal’s public cloud. It actually hosts more than 60,000 applications. We are going to use a user-provided service to connect Neo4j Enterprise to spin up on Google Cloud.
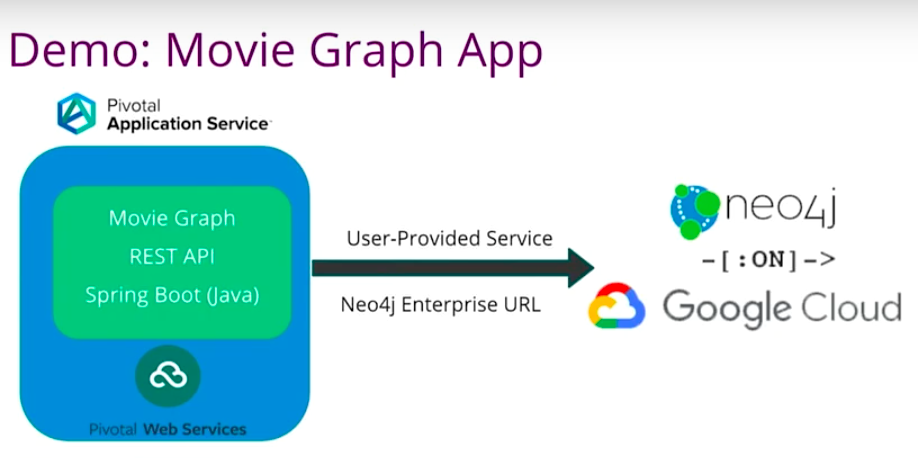
Let’s look at our application.
I have this movie, Java Spring Data Neo4j application. I want to make sure it runs on my local environment first. I’m just going to say spring boot run.

It’s up running on port 8080. If I go to localhost 8080, I see my Movie Graph here.
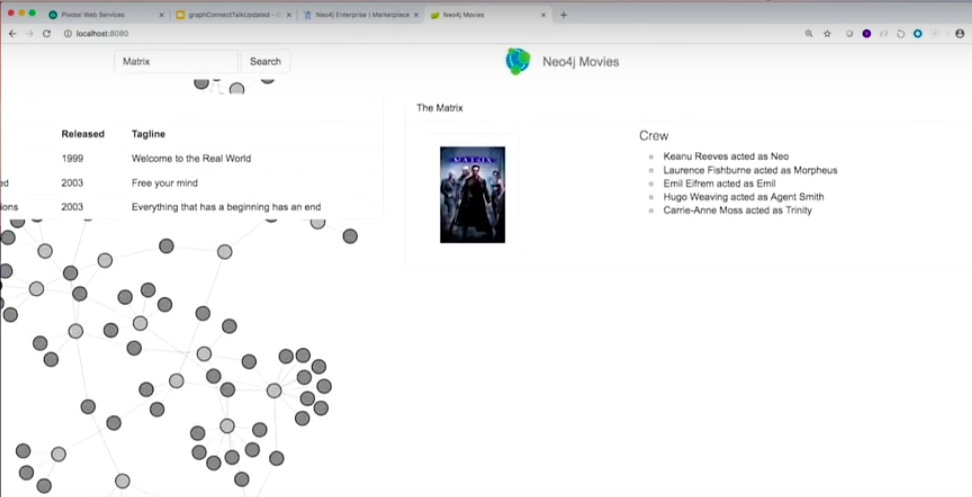
Now, I’m getting ready to push our application to Cloud Foundry. But remember we have to have Neo4j running in the cloud somewhere. We wanted to run it on Google Cloud. I’m going to spin up a Neo4j Enterprise on Google Cloud.
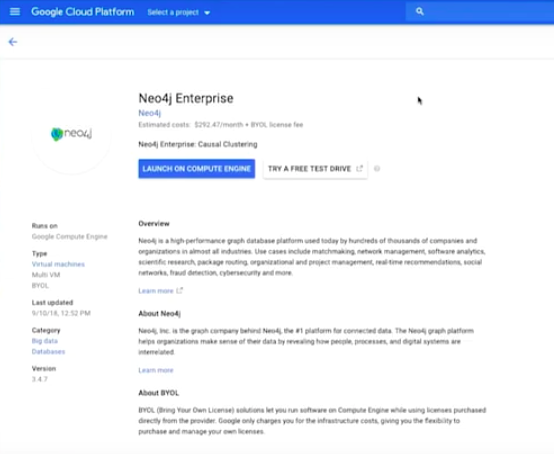
I’m going to launch on this program on a computer engine. I select the project, and now I am going to enter a few parameters.
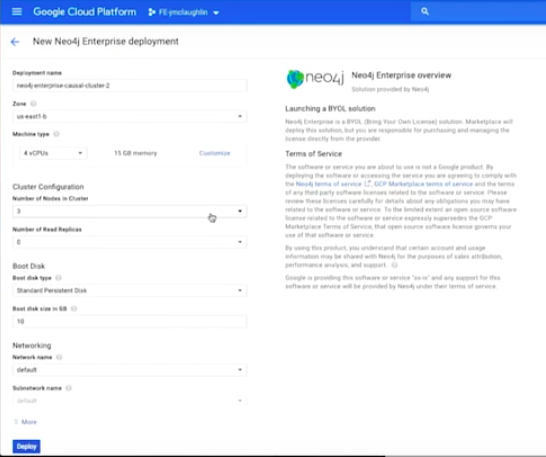
If I hit deploy, in a few minutes a Neo4j Enterprise console cluster is going to be deployed.
I’ll show the results here.
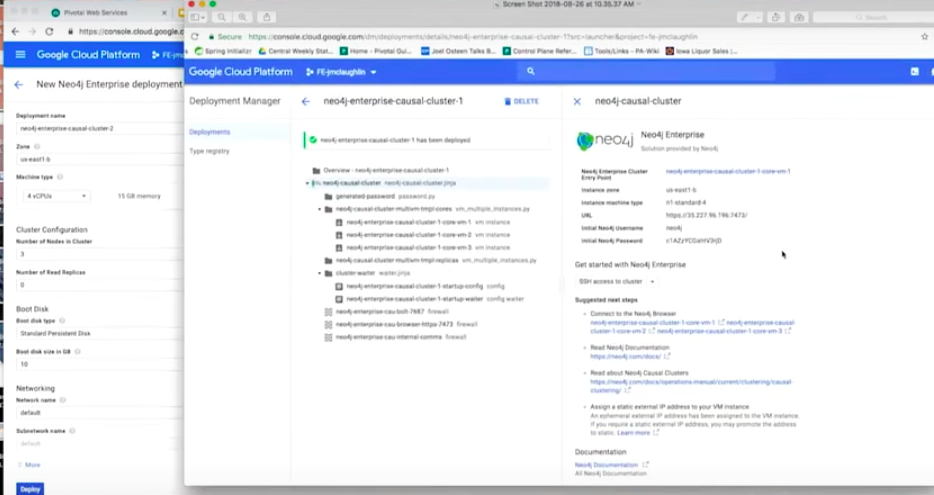
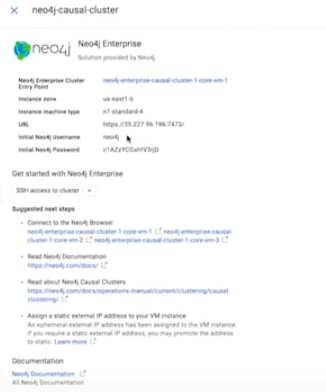
Basically, it gives me the connection string. Below is my Neo4j Enterprise cluster engine point with the URL information and user name and password.
Next, I am able to find out where I’m going to push my application. Since we’re going to use Pivotal Web Services here, and it tells me how to point the target to this Pivotal Web Services, I’ll do a cf login.
Now, it’s asking me which org. I also see the org information here.

Org is just a logical division of this Pivotal Web Services. Think about it as hosting 60,000 applications with role-based access control. I only see what I have access to, which are these organizations.
I select number two.
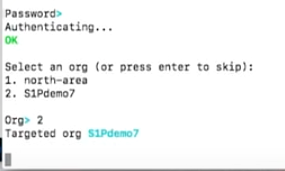
Next, it asks me which space. I’m going to use the test space. Space is a subological division of each organization. I have my end point.
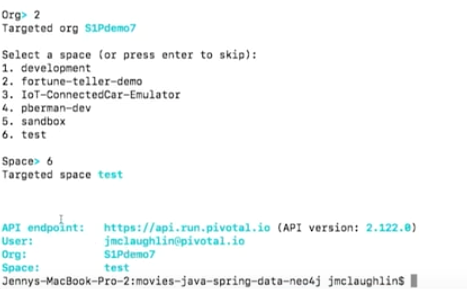
I am going to go ahead and do a cf push.
Because my application is going to be connected to Neo4j, I want to specify that service. I could do it from the command line or I could put it in a manifest file.

The manifest file shows that the name of the application is Movie Graph.
I’m going to use the jar file and my service is my Neo4j Enterprise, which I created by using the Neo4j Console Cluster on Google with the ID, username and password.
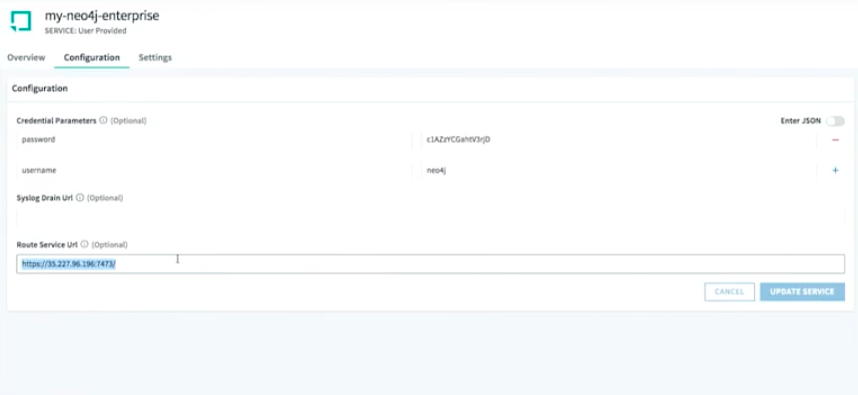
I am getting ready to do the cf push. When I do the cf push, the application is uploading that jar file first to the blob store. Once it finishes uploading it’s going to compile that jar file with this concept called buildpack. Buildpack has all the frameworks, libraries and runtime you need to run your application.
It downloads all the buildpacks, and then detects that your application is a Java application and knows to use a Java buildpack here.
Now, we have a droplet put in the blob store. Then auction is going to happen and we’re going to decide which VM is the one that’s going to run this application. Whoever wins that auction is going to go to the blob store, grab that droplet, spin up the container, put that droplet in a container and run the startup scripts.
Because we defined the service here, this is where the service broker is going to create a resource for the application and build that connection between the application and Neo4j Enterprise.
In a minute to 90 seconds, the application is up running.
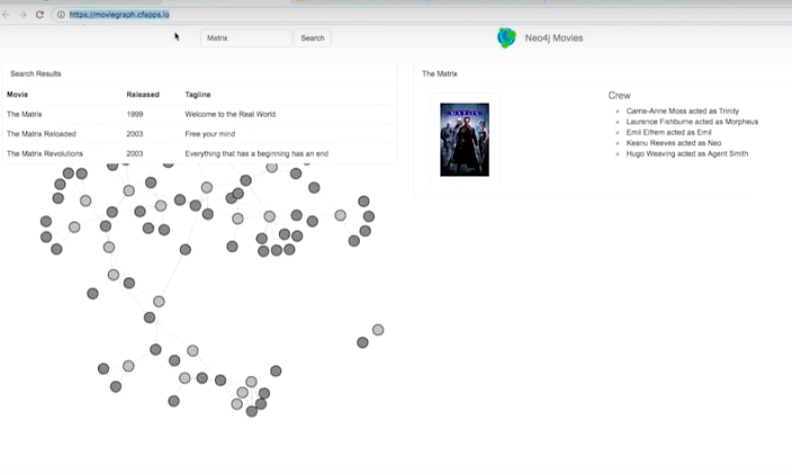
I have my Spring Boot Movie Graph application in the cloud, connecting to Neo4j.
What if I want to scale things up? I just say, “Instead of one instance, I want three instances.”
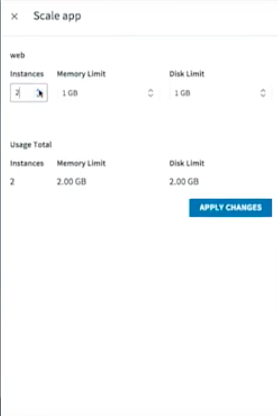
Within seconds, the same thing is going to happen. All these VMs are going to participate in this auction, and whoever wins is going to go grab the droplet, spin up the container, put the droplet in the container and run the startup scripts.
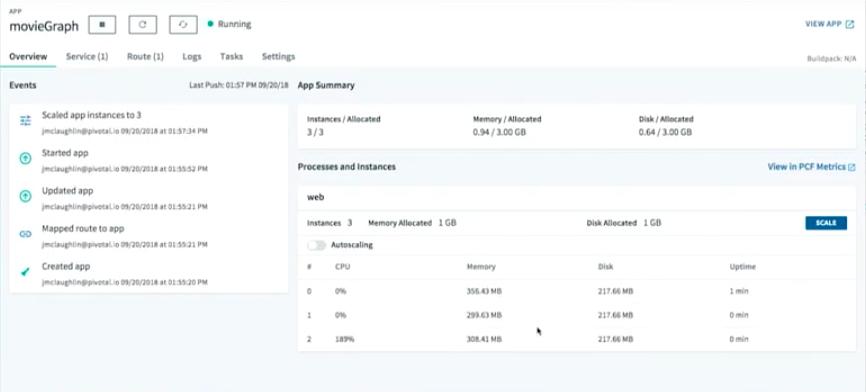
That happens in about five seconds because in production, you can’t afford minutes to spin up another instance. If it took minutes, hundreds and thousands of requests would be denied.
I can also do autoscaling, because why do it manually when we could do it automatically?
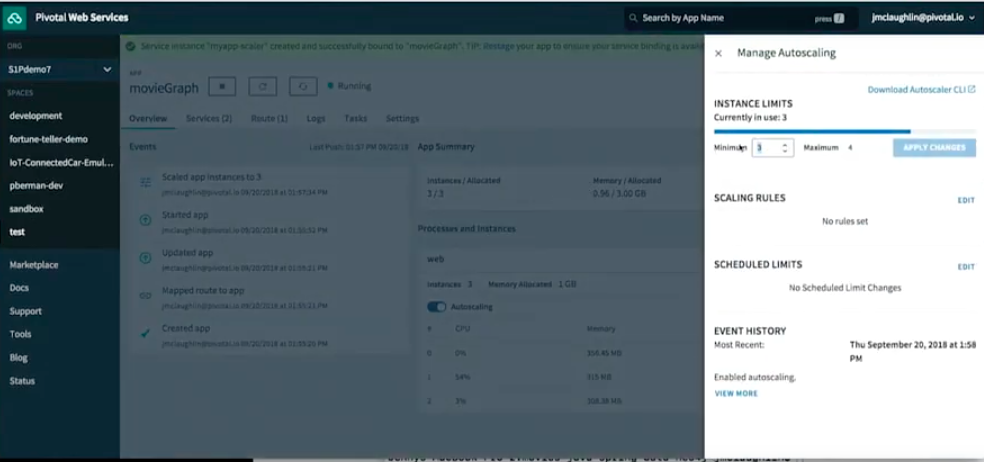
If I manage autoscaling, I’ll say the minimum is one. Maximum is four. Scaling rule: http throughput. I’ll scale down if there are less than 20 hits per second. I’ll scale up if there are more than 100.
There were three instances and now there are two. In a minute, there is going to be just one. Because I’m not hitting the application, there’s less than 20 hits within a second.
We demonstrated we are able to write a Spring Boot application quickly and push it to Cloud Foundry and connect to Neo4j.
12-Factor Applications
There is a concept called 12-factor design principles. It’s all about how to write microservices in a cloud environment. This ensures that your application run and scale predictably, in a very scalable way in a cloud environment.
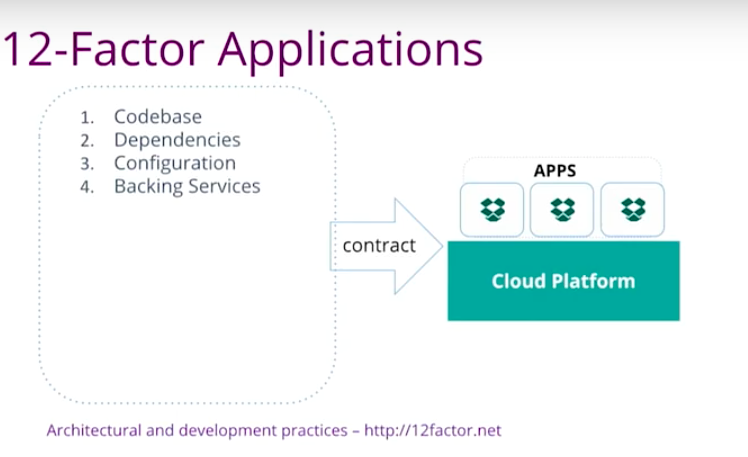
Codebase
Codebase is saying one codebase, one repository, one CICD pipeline. That’s kind of a no-brainer. However, if you think about it, if you’re putting multiple applications into one repository, you are coupling them.
Dependencies
Dependencies are saying you want to have your dependencies in your application. Don’t rely on mommy server, web sphere, or containers to give you those dependencies. Because Vms come and go, containers come and go, your dependencies may not be there, or there may not be the right version. They may be different between QA and production.
Configuration
We all know we shouldn’t hard code our connection strings but let’s take it a step further. Don’t put in a properties file either. Let the environment inject it into your application.
When we were running Movie Graph in the cloud, I used a screen cloud connector behind the scenes.

The screen cloud connector is this VCAP SERVICES environment variable. I use that and parse this connection string user name and password and inject it into the application. I never need to worry about it.
I am able to move from environment to environment. In a QA environment, I have all the connection string I need at runtime. For QA, I go to production. I have all the configuration I need for production.
This way, there’s never a case where I’m like, “Whoops, I accidentally wrote production data into the QA environment, or vice versa.”
Backing Services
Treating your database and messaging queues as backing services. Write your application as stateless because if you have your session state in your memory, and let’s say you have a three-step sign up process, after the first step, your container crashes and you have that state in your memory, that state is going to be lost.
That’s why you want to externalize and store it somewhere else. Store that session state externally either in cache or external database.
Logs
Logs are another interesting one. Treat logs as an event string. Write it in a console, don’t write it in a local disk. Because if you write logs to a local disk, that’s just in a container. Containers come and go, you may never see it again. We want to write to the console and let the platform train it to go somewhere else.
In our example, there are several ways of seeing logs. One is I could see logs here.
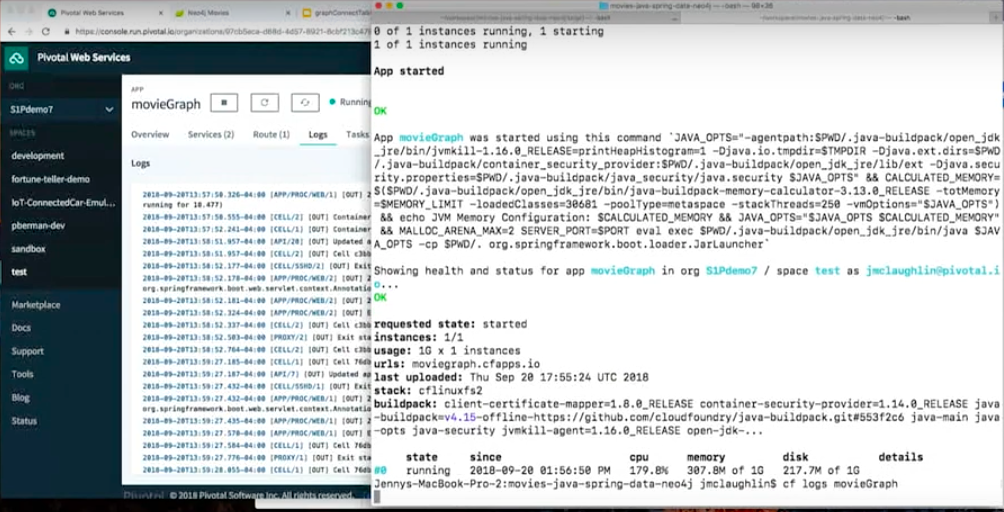
You could tell it, or from the command line. I have to hit generate to see a little bit of traffic and I see the logs here.
However, if you let the platform drain the logs to third-party logging management systems such as Splunk, you are able to see all the logs there as well.
Admin Processes
Admin processes are saying run your one-off process such as database migration just in a platform as if you were running a long running process in your applications.
This is our tested, golden rule for you to run, write green field microservices and make sure they run really well in the cloud environment.
Legacy Applications
- What about your legacy applications?
- We all have to support those things?
- Do we want to modernize them?
For your legacy applications, if you look at this picture, where are they?
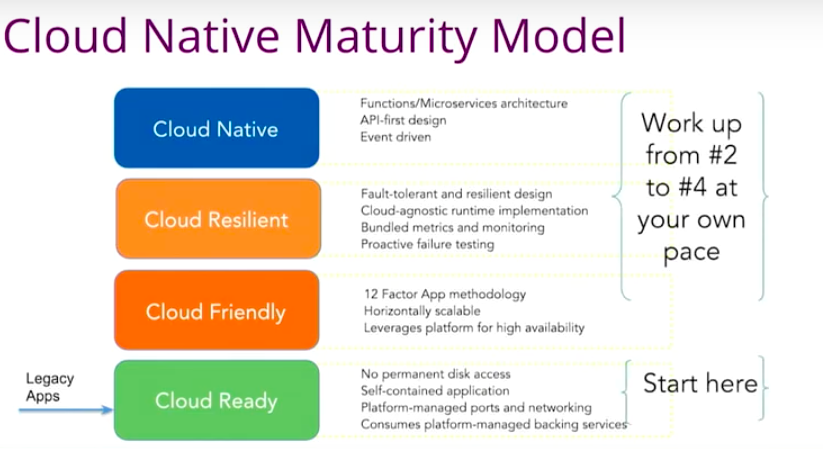
- Are they on-premise today?
- Or are they running on Vms on IAAS somewhere?
You want to move your legacy applications to the cloud-native platform Cloud Foundry to enjoy all the cloud capabilities like scalability. We saw how easy it is to scale things up and down and then if you are happy there, that’s fine. If we don’t touch this legacy application after, that’s fine too. If you really want to modernize those applications, you take one step at a time to move up this cloud-native maturity model.
The idea is for you to do as little as possible to get your legacy apps to Cloud Foundry first. Then at your own pace, you start looking at 12-factor design principles, you look at resilience, microservices architecture and API first design. If you want to do functions, that’s fine.
The transformation is not going to be overnight. It’s a very gradual process. You are moving toward a better way of building and operating your software. We are here to help you become the thought leaders on your cloud native journey.

To sum it all up, if you want to deploy and operate your applications and services quickly, use Pivotal Cloud Foundry. If you want to store and retrieve connected data quickly, use Neo4j Graph Database Platform because at the end of the day, it’s all about what developers love.

Show off your graph database skills to the community and employers with the official Neo4j Certification. Click below to get started and you could be done in less than an hour.
Share Article



Explore
Related Articles




15 Best Graph Visualization Tools for Your Neo4j Graph Database

Win a $250 Gift Card: Build Conway’s Game of Life With GraphQL for AuraDB Beta
