How Neo4j co-exists with Oracle RDBMS: An introduction to graphs


4 min read

 Let’s be honest. No one can argue about the value of the Oracle RDBMS database. Oracle
Let’s be honest. No one can argue about the value of the Oracle RDBMS database. Oracle
is and continues to be the mainstay for enterprise applications. However, another – but not
contradictory – truth remains: IT organizations need capabilities beyond what Oracle and
other relational databases provide.
While organizations don’t want to rip and replace Oracle, they do want more: They want
more features in their applications, more data variety, more agility, more speed and, perhaps
most importantly, more ways to rapidly uncover and innovate based on the rich connections
inherent in their data.
Connected data enables advanced capabilities that put companies ahead of the competition, including reduced time to market in many development contexts. With connected data, companies can better unify data across many disparate systems with better master data management (MDM) approaches, and increase positive behaviors and possibly revenue with contextual and relevant real-time product recommendations across ever-growing and evolving datasets. They can also save millions of dollars by analyzing complex connections to fight financial fraud in real time.
Every business needs to leverage these data relationships and leverage them faster. A graph
database, like Neo4j, delivers those capabilities – at no risk to your Oracle investments.
In this Neo4j and Oracle blog series, we’ll explore how these two database technologies work together in tandem to deliver the best bottom-line results for both enterprise architects and business teams alike.
This week, we’ll start with definitions and introductions of both Oracle RDBMS and the Neo4j graph database.
A closer look at relational databases
In order to understand how a graph database works and the value it brings, it’s helpful to
understand how relational databases, like Oracle, work. Relational databases store highly structured data in tables with predetermined columns and many rows of the same type of information. Because developers must structure the data used in their applications in this tabular format, the fixed schema works best for problems that are well-defined at the outset.
Relational databases are the perfect tool for highly structured, predetermined schemas.
However, these databases don’t adapt well to change nor do they provide an efficient
approach for traversing relationships between data elements. It’s ironic, but relational
databases are not good at navigating multi-layered, complex relationships in real time.
You might be using a “relational database,” but the truth is it’s not really optimized for dealing with relationships. Sure, it’s possible to use JOINs to navigate relationships, but relational databases take a performance hit as queries get deeper and add more JOINs. In fact, the term “relational database” has nothing to do with describing relationships between data, but is a reference to the highly specific mathematical notion of a “relation” – a.k.a. a table – as part of E.F. Codd’s relational algebra.
What is Neo4j?
A graph database, like Neo4j, puts data relationships first. Neo4j is an ACID-compliant, transactional database management system with Create, Read, Update and Delete (CRUD) operations working on a graph data model. The graph data model is easy to understand, as it reflects how data naturally exists – as objects and the relationships between those objects.
You can think of a graph data model as composed of two elements: nodes and relationships.
Each node represents an entity, and each relationship represents how two nodes are
associated. By assembling the simple abstractions of nodes and relationships into
connected structures, Neo4j enables you to build sophisticated models that map closely to a
problem domain.
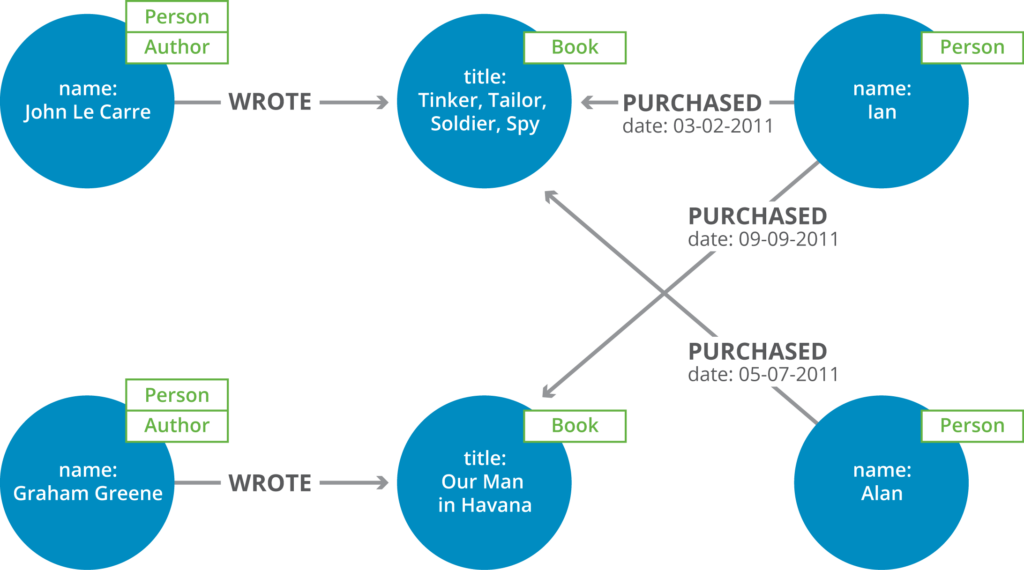
A simple graph data model: Books, authors and owners
Neo4j enables developers to be more agile and to deliver applications faster due to one
simple fact: It’s a schema-optional database. This means there’s no need to set up elaborate
data models based on what you think the business requirements are.
Instead, this flexibility abstracts your data model and validation to the application tier, but
still inherently provides you with the right level of control to define the data coming in. A data
model in Neo4j mirrors whiteboard drawings, closing the gap between business and IT, and
enabling you to make changes on the fly as business requirements change.
Because Neo4j uses an intuitive data model that anyone in the organization can understand,
querying the data is just as easy to grasp, even for team members without a database
background.
Conclusion
It’s time to get real about databases. Relational databases can’t do everything you need them
to do. But more importantly, you don’t have to sacrifice the capabilities of a graph database to
preserve your investment in Oracle RDBMS – or vice versa.
Next week, we’ll take a closer look at the specific advantages of using Neo4j alongside Oracle RDBMS and in the weeks to come, we’ll look at each deployment paradigm for using the two technologies together.
Share Article



Explore
Related Articles

Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report

POLE+O: The 5-Type Ontology That Solves the Hardest Part of Building a Knowledge Graph

1 of 3: The difference between a graph, a knowledge graph, and a context graph
