Neo4j container orchestration with Kubernetes, Docker Swarm & Mesos

PhD Candidate, University of Cincinnati
14 min read

Presentation summary
Container orchestration for multiple containers across a fleet of machines has the potential to solve issues across the range of scaling, replication, fault tolerance and container communication.
In this GraphConnect presentation, Dippy Aggarwal walks you through the basics of Docker containerization and why Docker alone isn’t enough to handle today’s challenges of scale and multi-cluster deployments.
The three most popular container orchestration tools she examines include Docker Swarm, Kubernetes and Apache Mesos.
Aggarwal first demonstrates the advantages and tradeoffs of Docker Swarm, including the familiarity of the Docker API. She also dives into the three main deployment strategies: spread, binpack and random. Aggarwal concludes with a demo of Docker Swarm.
Next, Aggarwal presents on the strengths of Kubernetes, most notably the greater number of concepts, a higher level of abstraction, better stability and more maturity. As before, Aggarwal includes a hands-on demo of deploying to Kubernetes.
Finally, Aggarwal shares the advantages of using Apache Mesos for container orchestration. She points out how Mesos can be used to manage both Docker and non-Docker jobs, providing you with a framework to launch both of these heterogeneous workloads onto the same cluster. Again, she ends with an Apache Mesos demo.
Neo4j container orchestration with Kubernetes, Docker Swarm & Mesos
What we’re going to be talking about today are three different container orchestration tools: Kubernetes, Docker Swarm, and Apache Mesos:
My dissertation is largely about the use of graph databases and provenance to study the impact assessment of schema evolution the context of data warehouses. The following presentation was inspired by an internship I did at the Cincinnati Children’s Hospital.
Cincinnati Children’s is a premier research organization that is ranked third in the country. As an infrastructure team, we set up and manage clusters and provision of resources to all the teams and groups across the Children’s Hospital.
Over the last several months we have seen a joint interest across teams in launching applications as document containers, which is great because of benefits of containerization that include multiple infrastructure and applications. But containerization also requires overcoming issues like scaling, replication and monitoring that come with containerization.
The following post will provide a conceptual hands-on introduction for deploying Neo4j containers across a cluster using the three most popular container orchestration tools: Docker Swarm, Kubernetes and Mesos.
I’ll start by giving an introduction to orchestration, an overview of these three orchestration tools, and demos of automated cluster deployment of Neo4j with the three orchestration approaches.
What is Docker containerization all about?
Containers allow you to avoid “runs on my machine” issues and allows you to package your machine as a standardized unit. You package your application with all its dependencies, application codes and run-time environments and ship it as a container — which offers the benefits of portability and isolation. And while the idea of containerization is not new, Docker really deserves credit for making it popular.
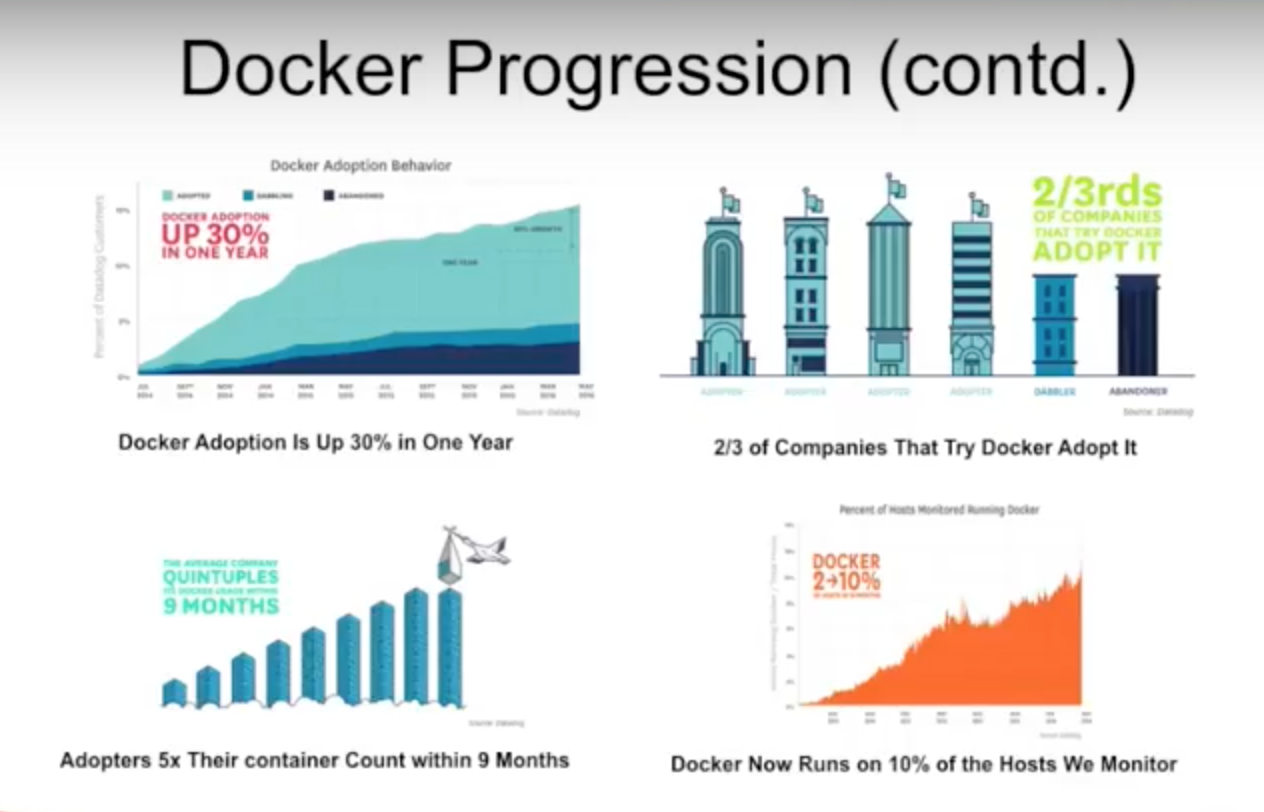
Datadog compiled a report that shows the interest trends in Docker. As you can see below, interest in the software increased by 30% in one year, and the number of containers launched increased fivefold:
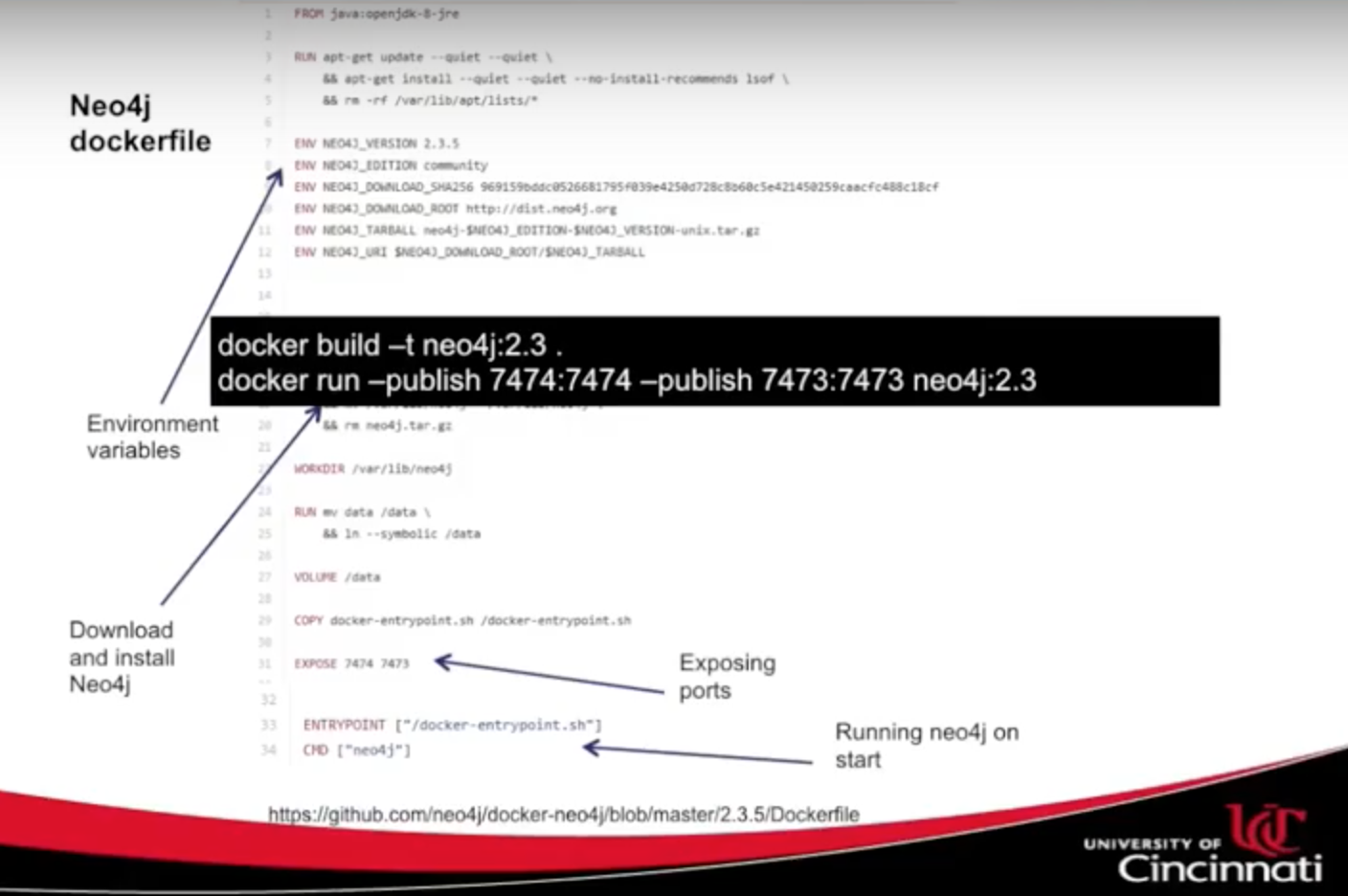
Below is an example Neo4j Dockerfile, a simple text file with commands you would typically run on shell, but here we have environmental variables, commands for downloading and installing Neo4j ports, and how to run the command:
To build and run one container, we run a command to build an image and another to launch a container based on that image. But we quickly encounter a challenge — Docker by itself just isn’t good enough. When you start talking about large numbers of containers, which can scale up into the millions, you encounter challenges that come with distributed systems such as scaling, replication, fault tolerance and container communication.
This where orchestration comes in: the idea of going from launching a container on one machine to multi-containers across a fleet of machines.
Given that containerization has become very popular, the orchestration space has become extremely crowded. A report released by the New Stack shows that Kubernetes, Docker Swarm and Apache Mesos are amongst the most popular. Cincinatti Children’s Hospital is leaning towards Kubernetes.
At GraphConnect San Francisco in 2015, Patrick Chanezon and David Makogon gave the talk Containerized Neo4j: Automating Deployments with Docker on Azure, which focuses on launching an image on Microsoft Azure and is a helpful supplement to this post.
What is Docker Swarm?
The main idea behind Docker Swarm is that you want to put a Docker API in front of a cluster. If you’re talking about one container running on a host, you have a Docker command-line interface.
When you have multiple containers and start scaling, an option is to have a Docker API talking to each of your containers — but that won’t scale when you have thousands of machines. What you need is a single-facing, unified interface that can talk to all of these Docker engines. And that’s exactly what Docker Swarm does:
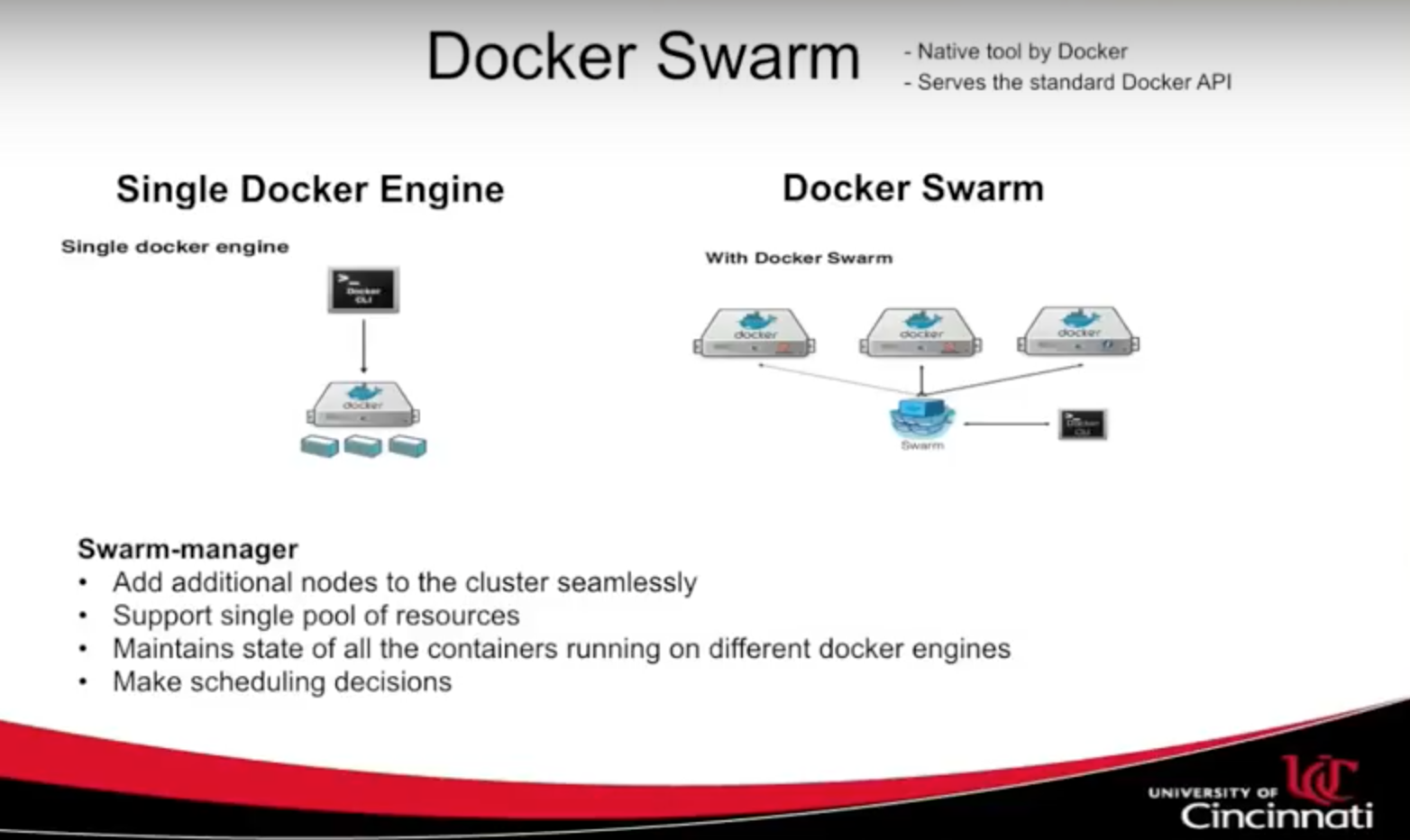
On the right is a single unknown, which is the Swarm manager that can talk to each of the Docker engines deployed on Swarm agents. In addition to providing a unified interface, Swarm provides device scheduling decisions and serves as a single pool of resources — which means that it maintains information such as the state of each agent and which containers are deployed on them.
Below is a more elaborate picture of the Docker Swarm architecture:
This shows that we have three agents running the Docker engine along with a manager that is communicating with each of them. The big rectangles show the containers, so each agent is running three containers.
The important thing to note is that our manager is composed of two components; a scheduler and discovery service. A discovery service allows the master to identify when new nodes join the cluster or if nodes leave the cluster.
There are different ways you can provide this discovery mechanism. You can do a token-based system, which I’ll use in the following demo, or you can use a distributed store like Zookeeper, but in the demo I’ll use Token Service.
What does a scheduler do? Well, when a manager receives a request to launch a container, how does it decide which agent to launch the container on? Or if I want to launch this container and make sure it has certain memory requirements, how does it filter nodes? A scheduler takes care of all these decisions.
In Docker Swarm, there are three different types of scheduling strategies:

The first is the spread strategy, which is the default strategy that says whenever you launch a container, it will deploy the container with the fewest number of nodes running.
The binpack strategy optimizes the node which is most packed, so instead of spreading the containers across nodes, it will try to fill one node first before moving on to the next. While this avoids fragmentation, you will lose a lot of information if that node fails where you have deployed containers.
And the third strategy is random which — as the name suggests — selects containers randomly.
Swarm filters allows the manager to eliminate some of the nodes when it has to launch a container. The example under “Swarm Filters” in the slide above shows that we want to run two containers on the same host on nodes that meet certain constraints: health checks and storage.
In this example here, I’m showing this filter for affinity, which says, “I will launch my container logger and make sure that it runs along with the front end container,” so the manager will take that into account by launching the container.
Docker Swarm demo
Below is the environment I’m using for the Docker Swarm demo. I have a virtual box running along with one master and two slave nodes:

Since I mentioned discovery surveys and the different strategies, I also want to show how you can change the strategies. By default, Docker Swarm follows the spread strategy so it will just launch your container on the node which has the least number of containers.
But if you want to change that, you can change launch containers based on binpack. This also shows how to use the discovery surveys using tokens.

Now let’s dive into the demo:
In a nutshell, I think the biggest advantage of Docker Swam is its simplicity. If somebody is familiar with Docker, the commands we use with Swarm are the same except for a few simple constructs you need in order to set up the cluster. Other than that, if you’re familiar with Docker, the learning curve isn’t steep.
And with Docker 1.12, there are several features such as auto-scaling that are now much simpler. As an example, if you want to scale your application, you can just say Docker Service Create, the name of the application, and the new workload.
Docker Swarm 1.12 also leverages some of the same concepts as Kubernetes, such as the levels of abstraction. The concept of services is somewhat inspired by Kubernetes, but with limitations related to the Docker API functionality.
But if you really want to stick with Docker and that serves your purpose, I think Docker Swarm is a good option to choose, especially with the new features like 1.12.
Kubernetes
What does Kubernetes provide above and beyond Docker Swarm?
If you are a Google fan, Kubernetes is definitely the way to go. There are also many more concepts, a higher level of abstraction, it’s very stable and it is more mature. Kubernetes is a container cluster manager, so while Docker takes care of the lifecycle management, you have the Google Container Engine — which is essentially a bolstered version provided by Google that runs Kubernetes.
The next demo will show how to run containers on the Google Container Engine and will include two ways to run these orchestration tools. One is how to set up a cluster running Kubernetes or Mesos, and the second is once you have a cluster, how do you deploy containers on it?
Just setting up the cluster could be a talk in and of itself, so in the demo I’ve already set up the up the cluster, and I’m using Google Container Engine which already comes with the hosted version of Kubernetes.
Let’s again discuss some core concepts in two different categories:

The first is — how do you use a cluster? The terms Pod, Service, Replication Controller, and Deployment pertain to someone deploying containers on a Kubernetes cluster. The terms Etcd, API server, Scheduler, Kubelet Daemon, and kube-proxy are for someone who wants to set up a cluster. You need to be familiar and clear about these terms.
A pod is a basic unit of scheduling used by Kubernetes, designed for the purpose of having one container per pod — but there is nothing stopping you from having multiple containers in a single pod. But all the containers in a single pod will live and die together. That’s the idea here.
The concepts – pod, service, replication controller and deployments – are all declarative and template-based, which we’ll go over in the demo. You use a file-based template, describe all your container requirements and then run that file.
The idea behind service is the concept that customers don’t want to worry beyond a single access location; they just want one endpoint they can access. And services provide an interface to a group of containers that provides customers with that single access point. Also, when you have multiple pods running across multiple containers, services serve as ambassadors between these containers.
While replication controller and deployment are similar concepts, deployment is a relatively newer term. The big idea is that when you want to scale your pods horizontally across several machines, instead of defining a pod and launching a container from that pod, you need to wrap that pod definition within an application controller.
Using replication controller, you can tell the Kubernetes master that you want five instances of this board running. If three come down, it will have to relaunch them. Apart from the basic container information, replication controller also contains information about the number of replicas you want to launch.
This figure below talks about the concepts that were listed on the right in the slide above:
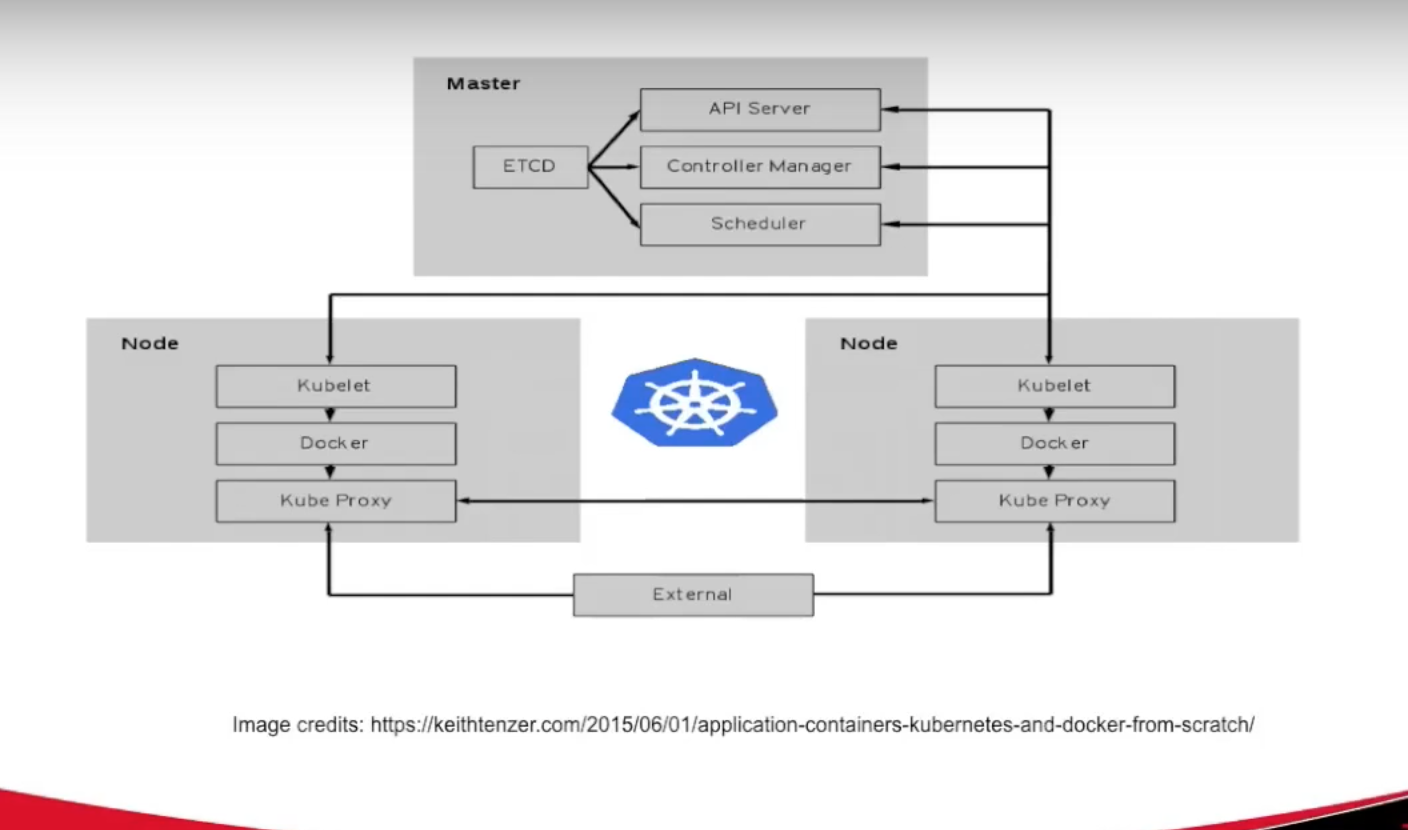
If you want to set up a custom Kubernetes cluster instead of using Google’s hosted version, what are some of the key terms that you would work with?
On a master, we have a set of services running such as Etcd, API server and Scheduler. Each of the Kubernetes nodes, which are called Minions, run a different set of services like Kubelet and Docker.
Kube Proxy is essentially a simple network proxy that allows the agents to communicate with both the master and external networks. Kubelet is responsible for communicating with the master and making sure that the containers within that node are functioning properly.
Coming to some of the terms in the master node, Etcd is like distributor key-value store. The master needs to keep track of all the agents, and if agent one is running five containers and agent two is running two, it tracks that information along with the state of that container.
API Server is the main interface provided by the master, so it is a rest API and is how you communicate with the master. Scheduler is the way the master decides which agents to deploy the containers on.
Kubernetes demo
Now let’s dive into the Kubernetes demo:
Kubernetes provides more concepts, a high-level of abstraction and allows you to deal with applications instead of machines. Docker 1.12 is also leveraging this idea of abstraction – using pods and services – from Kubernetes.
Apache Mesos
Mesos has a different philosophy than Docker Swarm and Kubernetes, which are both container management tools with a cluster-to-cluster relationship. Mesos is more of a resource allocation manager that allows you to manage both Docker and non-Docker jobs. Mesos provides a framework that allows you to launch both of these heterogeneous workloads onto the same cluster:
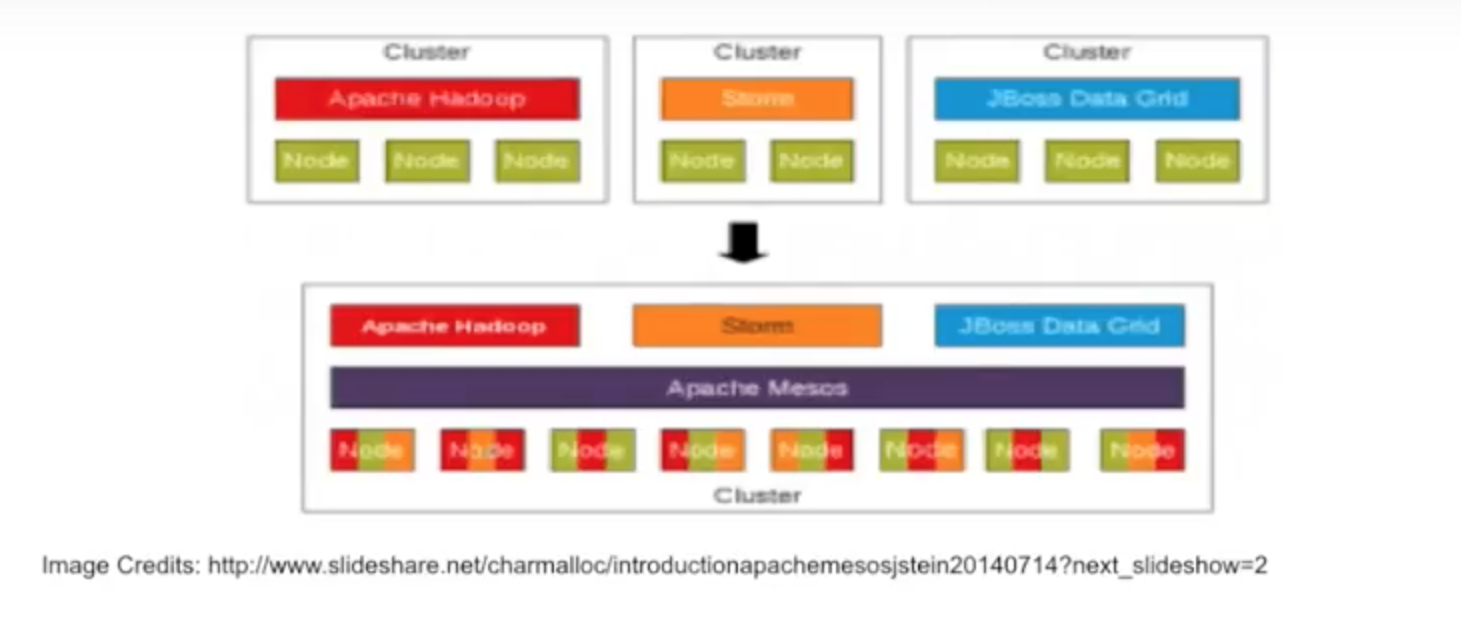
Instead of having something like on the top with three different clusters, you place them all in one cluster so that you can use it most efficiently. Why would you keep two nodes waiting or unused? Mesos provides the framework at the bottom that allows you to use the same cluster and use all these services on top of it.
Below is an image of a scheduling framework, Marathon, that shows both Docker and non-Docker based jobs. There are several other schedulers available as well, such as Kronos.
The following shows how you can have multiple workloads under the same framework:

We can use Kubernetes for managing some of your Docker jobs and Marathon for managing others. You can also use Docker Swarm instead of Kubernetes.
Below is an overview of the core components of Mesos:

Along the same lines as the other two orchestration tools, there are three core components of Mesos: master, slave and frameworks. Since it’s a resource allocation manager, if you want to launch a container you make a request for a master, which checks with the frameworks to see if it has resources available. Slaves are the nodes that actually perform the work and launch the containers.
Apache Mesos demo
Below is a demo that shows how to launch containers using Mesos:
Which one to choose?
Given these three orchestration tools, the natural question is: Which one to choose?
Well, it really depends on your requirement. If you want to use the mixed workloads, then Mesos stands out. If you want to stick with the Docker API, choose Docker Swarm. I think Kubernetes provides a very mature set of concepts and has been around for a long time; but it comes down to the choices and requirements you have within your organization.
Share Article



Explore
Related Articles


Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher



