Using GraphQL for Digital Identity & Access Management

Identity Solutions Architect, Nulli Secundus
14 min read

Editor’s Note: This presentation was given by Alex Babeanu at GraphConnect New York in September 2018.
Presentation Summary
Identity and access management (IAM) – one of the pillars of cybersecurity – is growing immensely. In a world where hackers and malicious agents target the insiders more and more often, proper access management policies and controls are able to keep your data safe.
Yet, our field is in turmoil: IAM professionals now need to cope with a tsunami of new digital identities as well as new attack vectors, while ensuring that new and more stringent privacy laws are enforced. At Nulli, we have been evangelizing graphs for identity for a while now, but the recent advent of GraphQL and GRANDStack promise to be a game-changer.
In this post, we share our experience building real-life identity and access management solutions using GRANDStack and show how graphs can also help in real-time access management decisions.
Full Presentation: Using GraphQL for Digital Identity & Access Management
I’m Alex Babeanu, and I’m an identity solutions architect and specialist at Nulli. We’re a consulting firm based in Canada, but we have lots of clients here in the states. We mainly focus on identity and access management (IAM) solutions.
You might wonder why I’m writing this post. And as it turns out, graphs have been quite helpful in solving some of our problems, and that’s what we’re gonna explore here.
As identity and access management professionals, one of the first things we need to define and make sure we all agree upon is what an identity actually is.
So, what is identity? At first, this seems like an easy question because we all have an identity that we’re aware of. Some of you might have several. It’s something we are born with and from an early age, we have a notion of it.
For example, when I was a kid of eight or nine years old, I was already a huge fan of science fiction. I had a lot of toys and I’d huge battles between all of them. But, I would eventually run out of toys, so what I’d do was I’d start integrating more mundane objects into my games.
The point of this is that even at an early age, I could easily interchange the identities of my objects and still be able to play. I had an understanding of it.
Here’s a tricky question for you. Can you actually provide a formal definition of what an identity is? This is what I’m going to discuss today.
First, we’re going to explore what an identity is. Then, I’m going to give you a very quick, high-level overview of identity and access management (IAM). We’ll then look at the problem we’re facing nowadays in the field and see how graphs provide a solution to those problems. Last but not least, we’ll look at GraphQL and GRANDStack and how they fit in our solutions.
About Identity
Jumping in, we’ll talk about how we define identity. We believe it applies to a lot of cases and helps us figure things out.
First of all, an identity is something that has a set of properties. This is true for a lot of things, but it’s especially true for identities.
Second, an identity is an entity that needs to be authenticated and authorized. What that means is that it’s an actor, it performs an action and that action needs to be authenticated. This is probably the most important feature of an identity.
Third, identities are always related to other entities. An isolated identity is not interesting in itself – we’d just discard it. The mere fact of an identity accessing a resource creates a relationship between them.
So, what fits into this definition? What examples do we have? Examples include users, of course, but also people and smart devices. Cloud services fit that description as well because they often communicate with each other. Last but not least, IoT devices, which have smart sensors, meters and lights, also fit into this category. All of these have identities.
What Is IAM?
Identity and access management basically includes the three pillars in the diagram below.

You have identity management per se, which deals with the identity life cycle and involves creating, updating and deactivating identities. It also includes role management as well as user account provisioning, like creating a mailbox, accounts on your apps or in-house resources.
The second pillar is password management, which involves anything that pertains to changing or updating your password, or in the case of devices or smart objects, storing secrets or certificates and how you manage those certificates.
The last pillar is access management. That is what happens at run time when an identity tries to access a resource; it’s where we require authentication and authorization. Examples include single sign-on, identity federation across different domains and end-factor authentication.
Particularly, we found that graphs really help us with access management, so we’ll focus on this, at least in this post.
Access Management
Access management is composed of two main pillars, authentication and authorization.
Authentication is like the front gate to your castle. It’s where you ask for the credentials of your identities – and if you’re happy with the credentials, you let them in. Once they’re in, they’re in. Typically, we store the identities not in a graph, but in a directory, which is fine.
Authorization, on the other hand, is what happens when the identity is in your domain. It’s already inside, so authorization drives what rooms, features and data points they have access to. This can be as granular as you need it to be – you can specify which particular notes they can access, and so forth. This is where graphs play a big role.
The Problem
Back in the 70s and 80s, the only things that had an identity were fictional characters. Now, we’re not even sure if the condensers in the fridges have an identity. We’re seeing a dramatic increase in the number of identities we have to deal with, and therein lies our problem.
Take a look at the diagrams below. They show an almost exponential rise in the number of IoT devices that we’ll see by the end of this year: 50 billion devices.

That’s a lot of devices, a lot of new identities. If you add the number of humans, cellphones, and services, you really realize that you have an explosion in the number of identities we have to deal with.
Besides that, we have an explosion in the number of relationships, because identities are never alone. Let’s take a look at the graph below. A smart sensor lives in a refinery and the refinery has workers that need to access it. Moreover, everybody lives in the region. The device itself can upload its data to a cloud service. And, of course, the service is managed by these very smart IT folks.
Now you can tell why graphs are important to us, since we can represent this all as a graph. And this is only a portion of the graph.

So as you can see, we have an explosion in the number of identities, which also leads to an explosion in the number of relationships that we have to deal with. This is all quite new, in our field at least.
The last problem is what I call the API explosion, and I’m sure you’re all familiar with that. Every organization nowadays has a bunch of APIs. Every one of the nodes, entities and labels in a graph requires a bunch of APIs in order to maintain them, as shown in the image below.
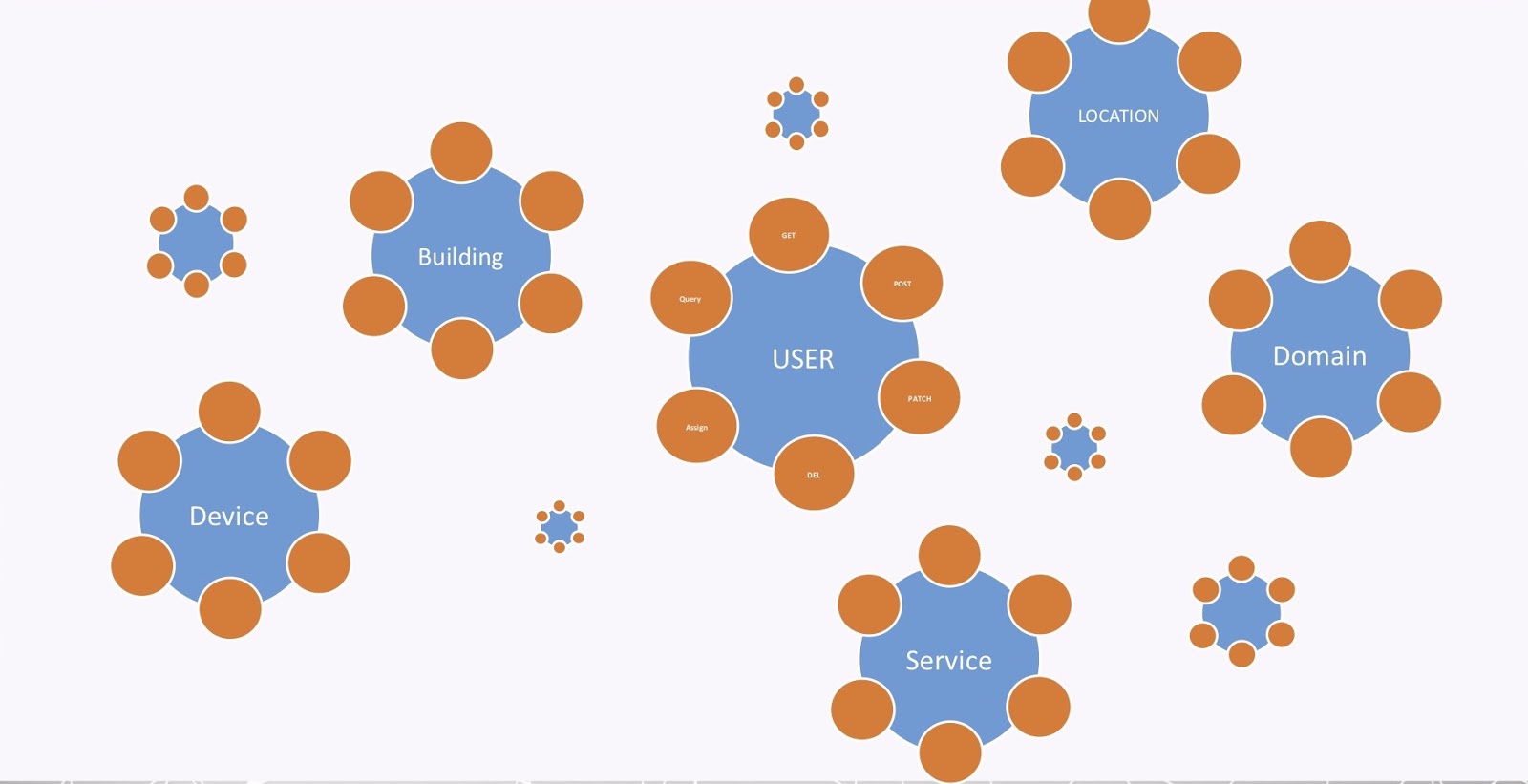
That’s also true for all the entities in our graph. But again, organizations now have maybe hundreds, maybe thousands, of APIs. So, it’s quite a big problem to be able to manage all of this.
The Solution
We propose that graphs provide an elegant solution to our identity and relationship explosion.
But, as for the API explosion, we propose that GraphQL will help. Together, these are tools that we can use in IAM to implement true identity relationship management. There’s been a bit of failure before this with identity relationship management (IRM), but we think using graphs will really provide a solution.
Graphs for Identity
Let’s take a look at how we use graphs for identity to bind everything together.
We use graphs to model complex data and derive real-time access control decisions, but future applications also involve analytics.
For authorization, we need to define access policies, which are rules that derive the control and access to a resource. It’s a simple way to model an access policy.

Specifically, an identity is related to a resource. We usually define this with a verb, such as owns, has_access or is_paired. This is simple – if there’s a relationship between those two nodes, then the identity can access the resource.
Let’s have a look at another example. Take a look at the image below; let’s imagine this is the knowledge we have of our world. We have Bob and Mike, who are friends. Jenny loves Bob. Jenny also owns a car, a Renault. Mike owns a car, a Porsche. They’re both red.

Now, here’s our policy: people only lend their car to their friends. And here’s our question: Can Bob borrow Jenny’s car? This is an example of a real access question.
We solve this by running some Cypher. So we need to match a person that owns a car, who also has a friend. This is Bob and Mike. So, we ask if Bob can borrow Mike’s car.
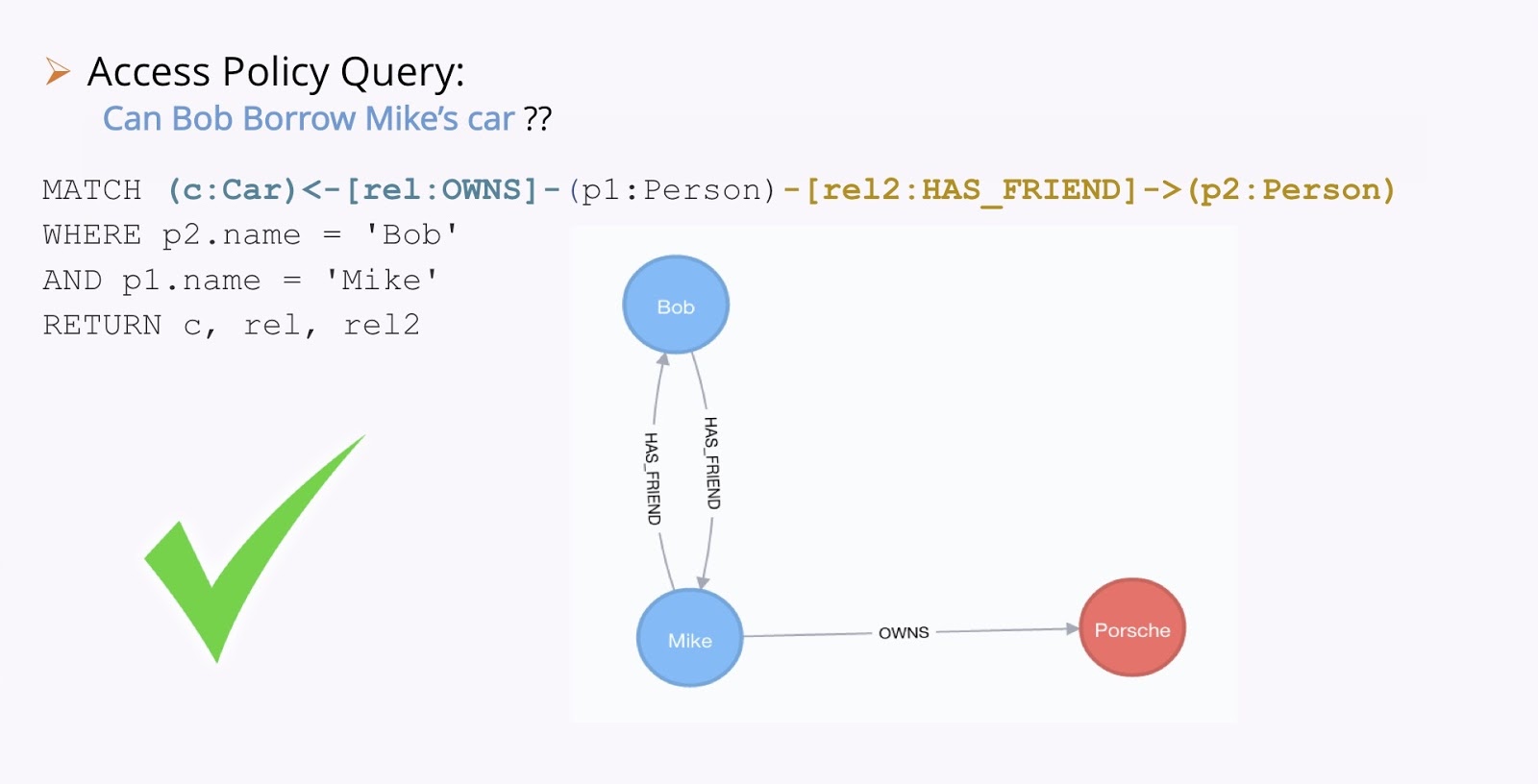
In the case above, we have relationships with the car and we actually find the relationships. So yes, Bob can borrow Mike’s car.
If we ask the same question with Jenny and Mike: Can Jenny borrow Mike’s car?

In this case, we don’t find a relationship, so there’s no access.
Real Example
Moving on, let’s look at a real example. This is from a customer we had a couple of years ago, who was an IoT manufacturer. The context is that they had a bunch of refineries worldwide with hundreds of devices. Of course, the refinery is a complex environment, with a bunch of things going on everywhere.
These are the types of devices that we are dealing with. They’re all smart devices in that they can be accessed remotely or can upload their data to a cloud service on their own.
So where was the problem? Well, first of all, we had a problem with volume. As I mentioned above, we had an identity explosion – 500 plus million identities spread out worldwide and as many resources to protect.
Because identities – especially IoT devices – also act as resources to be protected at times, at times they can be an identity and other times a resource, though it’s the same device. And so this manufacturer had very complex relationships between identities and resources, which were really hard to model traditionally. For example, they had directional relationships and friends of friends relationships which would lead to a table join “explosion” in SQL. In this way, they needed to resolve path queries.
They also wanted to implement a true IRM system. Of course, graphs were a perfect fit for all this.
Use Cases
Here are some of the use cases we implemented using graphs.
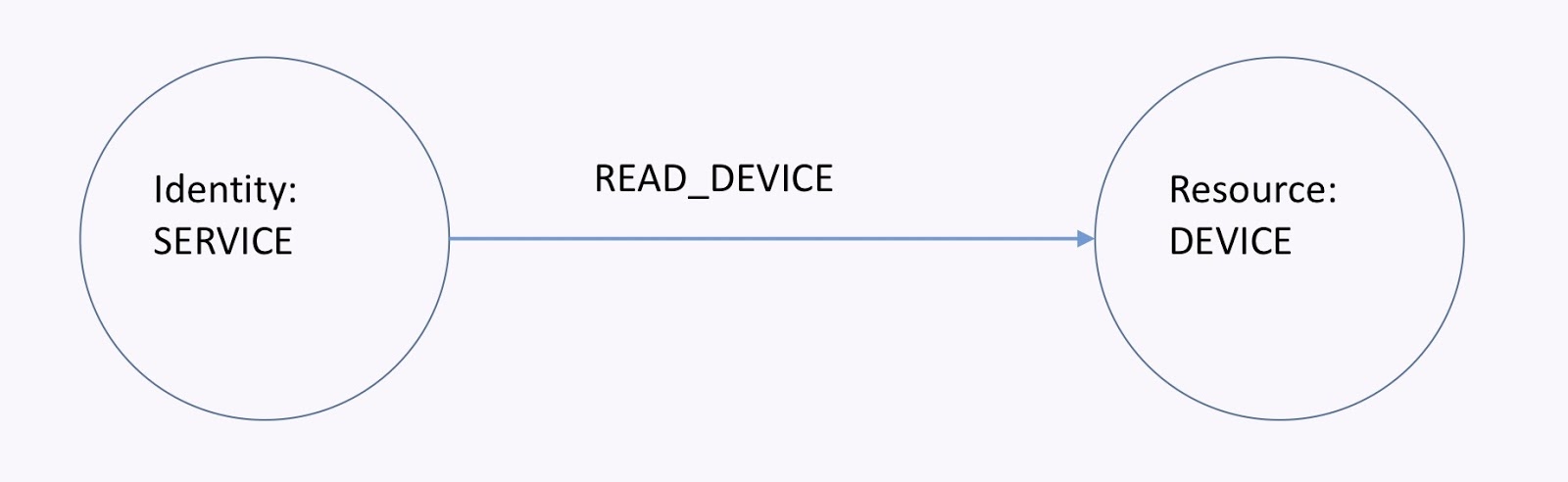
As a service or app, I need to be able to read data from a device, which is shown in the graph below. If I have the read-device relationship, then the service can read the device. To revoke that access, I can just remove that relationship. This all happens in real-time and it’s easy.
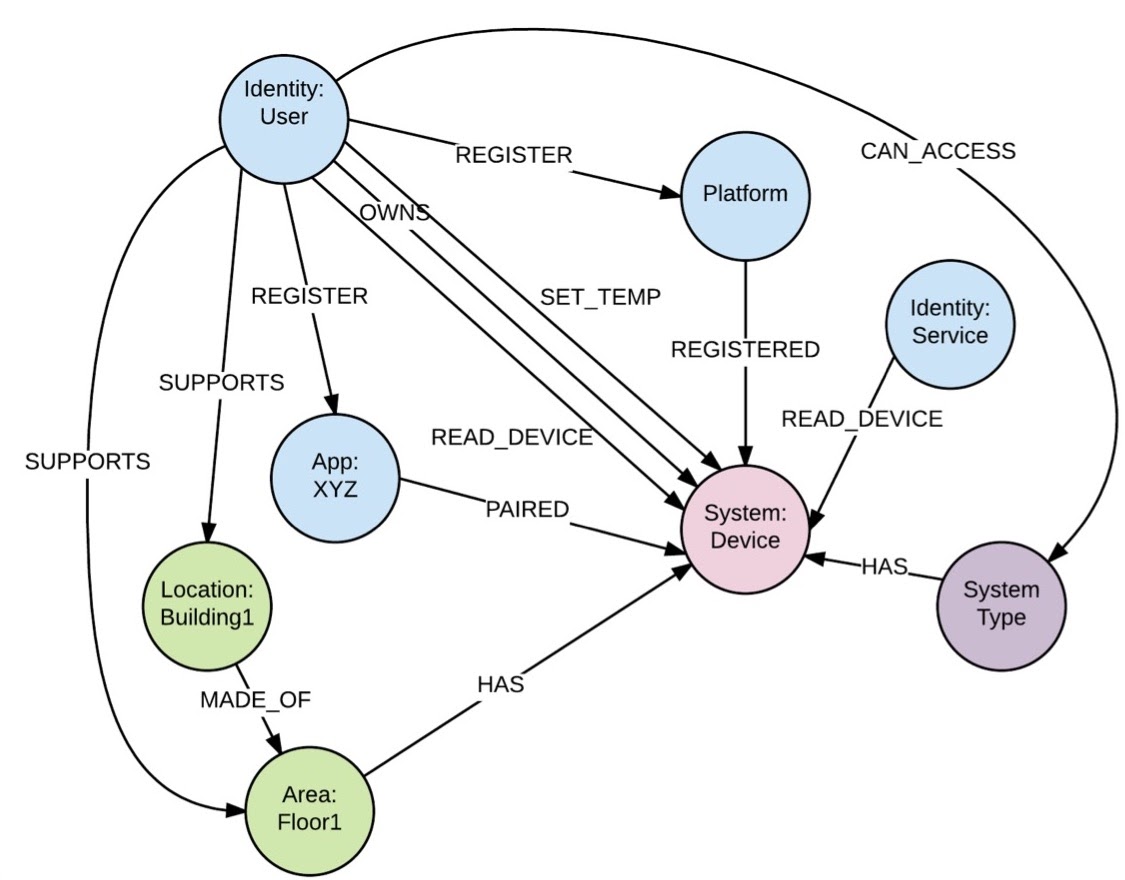
Here’s another one, shown in the graph below. As a factory worker, I need to register a device with the IAM platform using a given app. In this example, I already have a user who has registered with an app. There’s also a device out there, and I need to be able to pair it with the app and declare that the user owns it.

So this is basically what happens. If I have these relationships, I can easily deduce access policies from that. If I need to revoke those policies, I can just revoke or delete those relationships.
Let’s take another look at the graph below. As a building owner, I need to be able to grant certain users access to all or parts of my building to, for example, technicians. I have a building that’s made of several floors. Each floor has a set of devices. Then, I have the owner of the building. User Tsmith here tries to access that floor in order to service those devices.
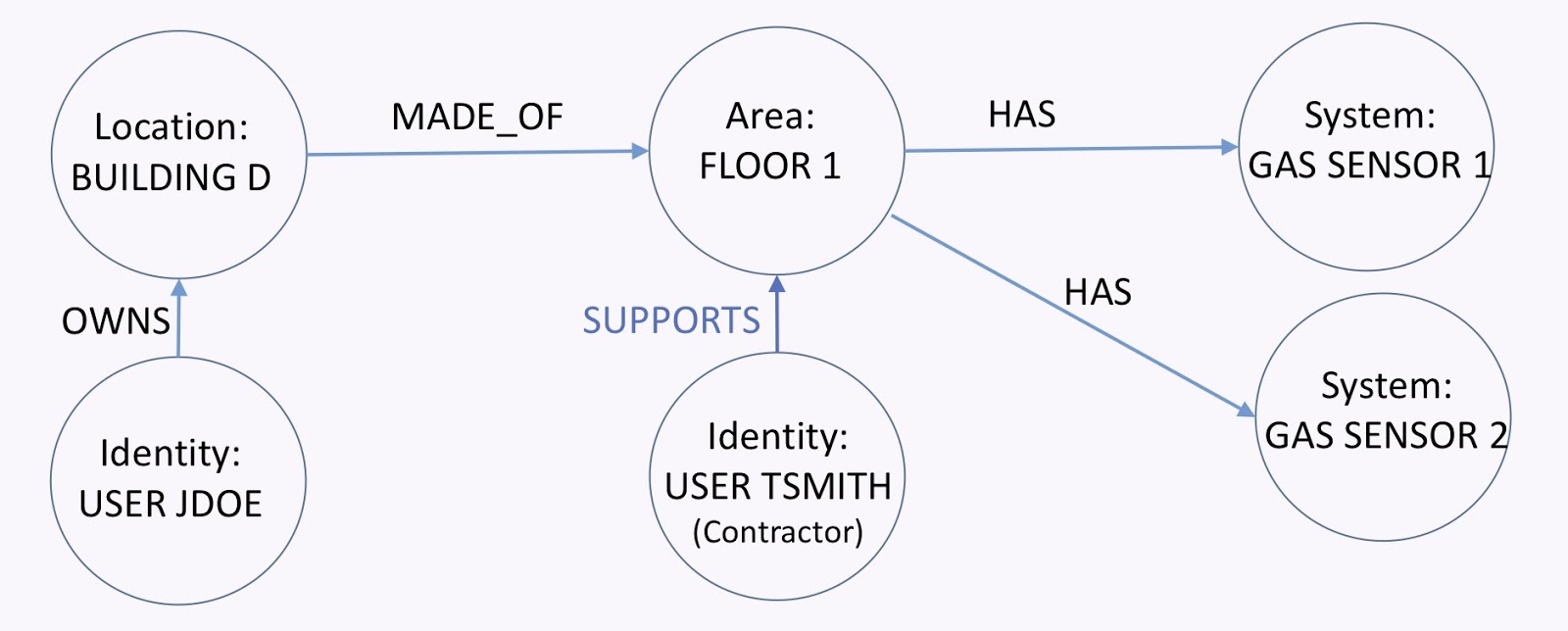
All I need to do is add the supports relationship. From here, I can find a path from that guy to the devices.
Putting it all together, we came up with a graph model that looked a bit like the one below, though the actual graph has around 500 million more nodes.
GraphQL: API Explosion
We just looked at how we usually tackle the identity and relationship explosion problems. Now let’s have a look at the API explosion problem, for which we propose GraphQL as a solution.
First, remember the API explosion problem, where we had all these entities and APIs that we had to manage and control the access to. The image is replicated below.
Instead, wouldn’t it be nice to have one single REST endpoint that would cater to not only the entities I have now, but all the entities? Well, that’s exactly what GraphQL proposes.

So, what is GraphQL? Many of you know it’s a generic query language for APIs over REST. Also, it was created by Facebook. Particularly, it’s a specification, meaning you can build your own. It has one single REST endpoint for all queries – both present and future. Moreover, it works with any backend store, but works greatly with Neo4j.
This is how it works. As shown in the image below, we have a client with a GraphQL client library embedded in it. It packages a query like the one below, which goes to a server. The server understands the query and transforms it into using some custom code – which could be JavaScript or your favorite language – into a query, like the Cypher query below, to the graph database. The database then returns data, and the GraphQL server packages a response.
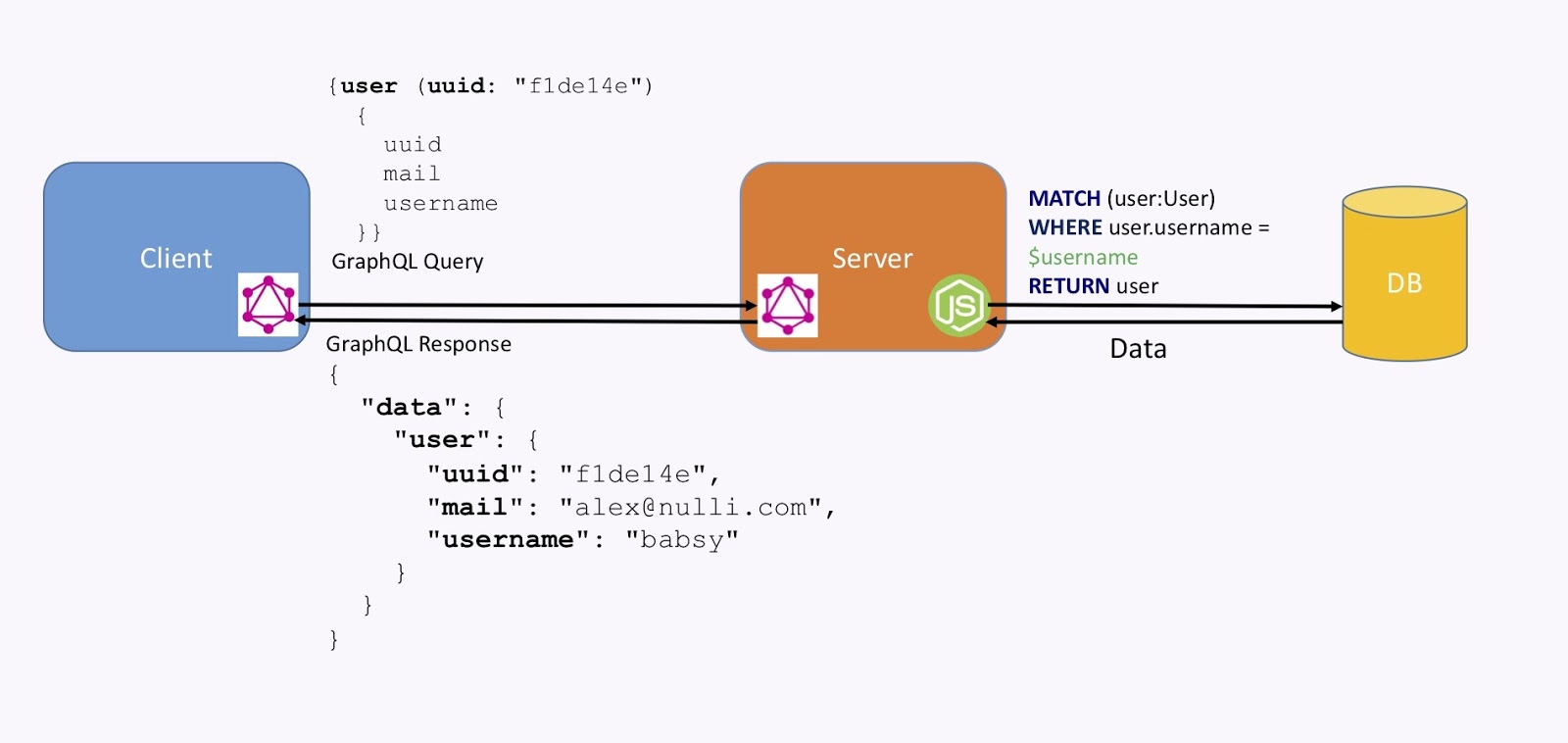
Here, the query was for a user. We requested the UID, the email and the username, and we got that back in this format, which is also standardized for GraphQL (this is a specification). From there, the client understands that and displays it.
To really make sense of the power of GraphQL, we have to zoom in on the server.

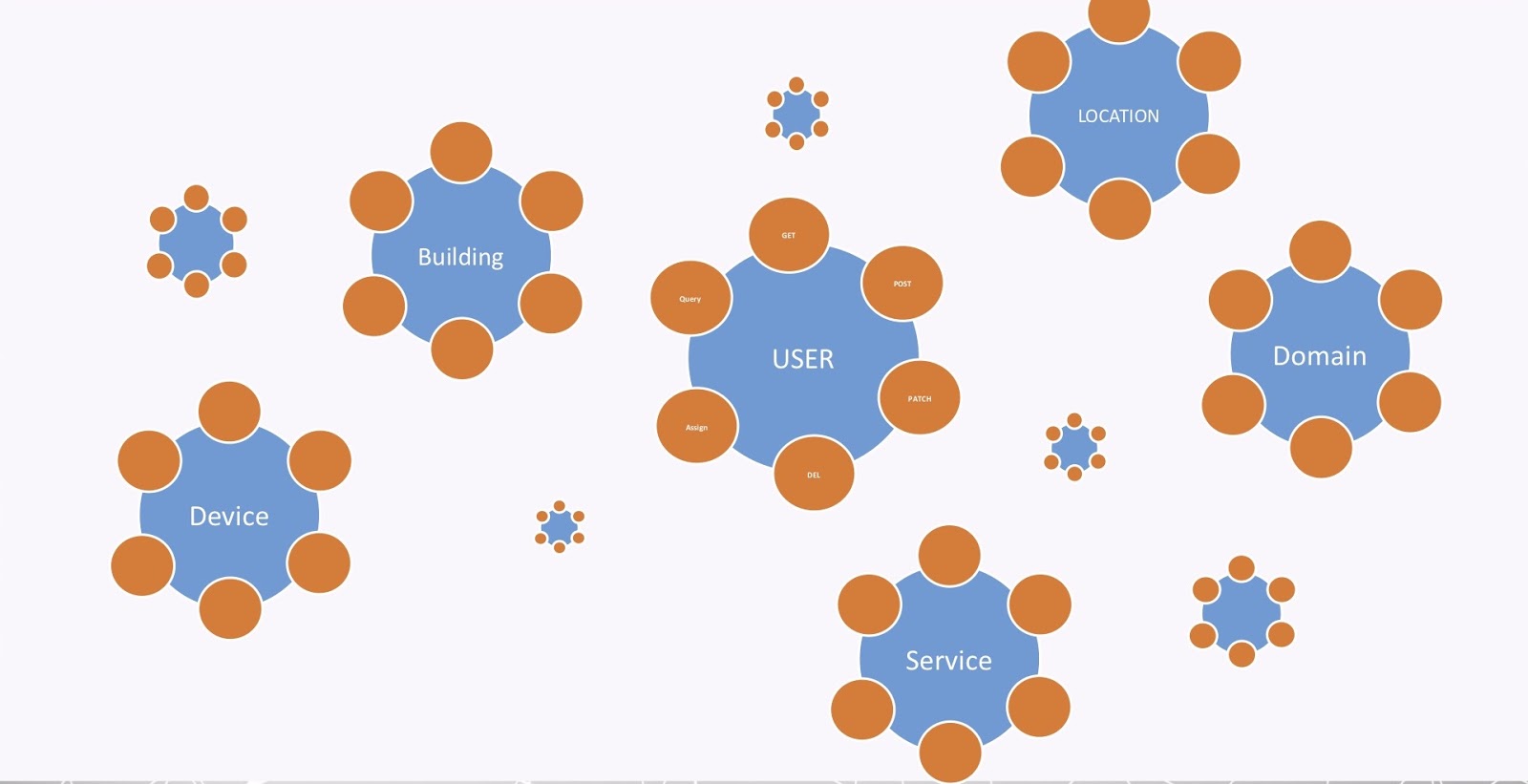
If we zoom in on the server, GraphQL works by defining a schema, which is made of three things, the first being a set of types. These are the object or entity types in your database that you’re willing to expose to your client. You don’t have to define all the types that you have in your database, but only those that you’re willing to expose to the client.
Then you have your queries, which are your reads, and your mutators, which are your writes. Through your query, you can get your data, and through the mutator, you can update it.
The mutators and queries are implemented through resolvers, which use your favorite programming language, like Neo4j!
In the images below, I’m going to present some code. At Nulli, we built our own IAM platform from the ground up using Graph QL, which runs on microservices and is docurized. Again, the schema is made of types.
As I mentioned, we wanted to implement true IRM. Because of that, the relationships are first-class citizens. Of course, we have a type relationship – which is shown below – but we also have user types and location types, device types and domains, which we define and then map to the types of data that we have in our database.

Our relationships have a start label and a start UID, as well as an end label and end UID. They also have the label of the relationship. We have a bunch of types like this – they’re just definitions, simple code.
The second thing in our GraphQL schema are queries, which are just a subset of the queries that we’ve defined in our GraphQL schema. As you can see, the queries are just definitions; if you’re familiar with object-oriented languages, they’re a bit like interfaces. It’s essentially the contract between the server and the client.

Queries basically just include a name, a set of input parameters and an output type. If we look at the one above, for example, can A access B? This is a query that you would run in order to evaluate the access that A has on B. If you have A as an identity, B as a resource, and you want to check if A can access B, what we’re doing in the backend is finding the path between A and B. If that path exists, then we grant access.
For that, we need the UIDs of A and B, which return an array of relationships. More often than not, A and B are separated by several relationships, so we really need the path.
Similarly, mutations are just the type for the things that we can change in our data. Here, you’ll see things like reset password, update your user profile, create a user, activate the profile and register your social email.

All of these need to be implemented through code with your resolvers. Below is an example implementation for our can A access B? query.
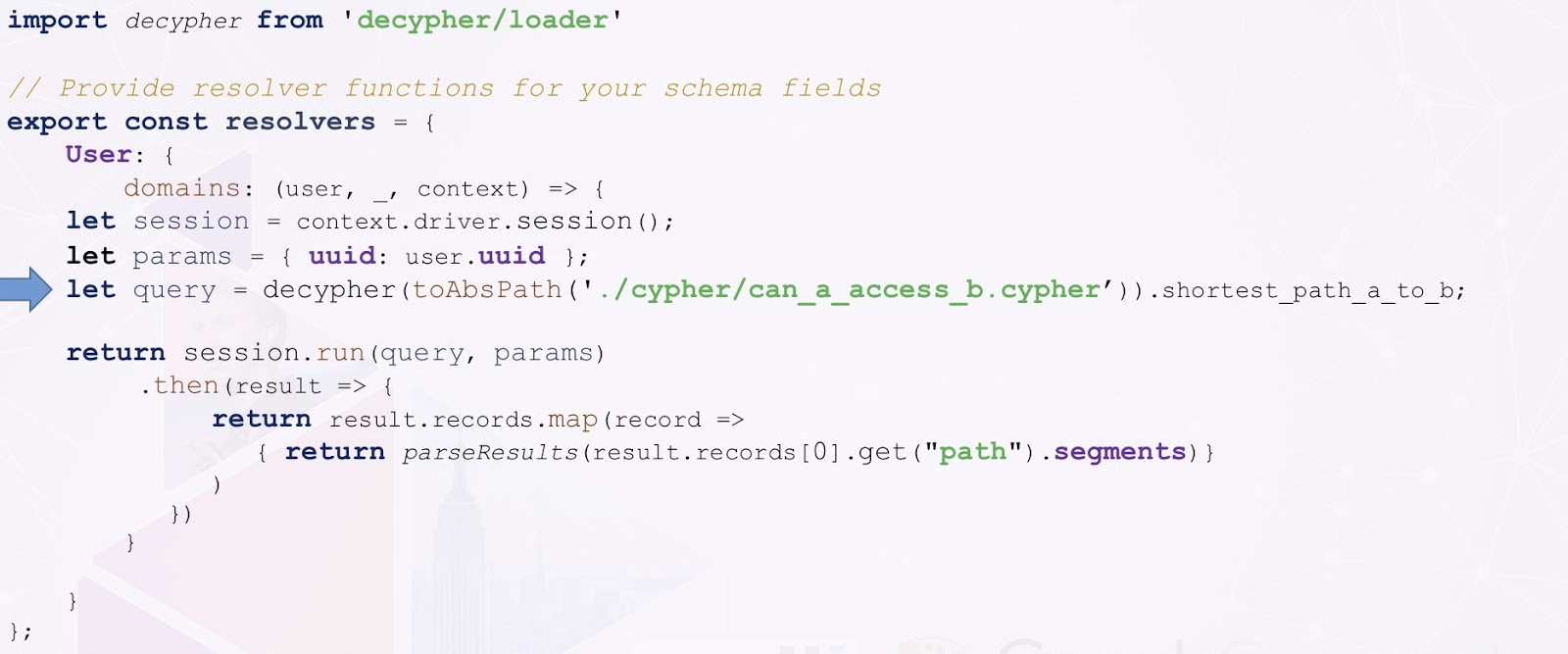
This is just JavaScript code. The only important piece here is the row in the middle there with the arrow. What that does is reads a Cypher query from a file, executes it against Neo4j and returns the result.
The query that we’re reading and running is basically the code below. As I mentioned before, we’re just finding the path between A and B.

If we find that path, then we can grant access.

Below is what the query run time could look like. We just package it like that and run it through our one single REST endpoint.

Below is what that request would look like.

Finally, below is what the result would look like. In this case, we only have one single row in our response because it was a simple relationship, but again, it’s essentially an array of several relationships that define a path.

GRANDStack
So now, the GRANDStack. As I mentioned, GraphQL is a specification, and you might think it all sounds like a lot of work to implement all of this yourself. But no – there’s GRANDStack! All of these things have been already done for you; all you have to do is use it.
The GRANDStack is the integration of Neo4j, the Apollo for the GraphQL Server and Client, as well as React.js for the Client UI Framework. They’ve worked together and packaged everything neatly so you can download this stuff, get ready and work on it right away.
This is how it all integrates together. We have React.js on the Client, with the Apollo Client Library running GraphQL and the Apollo Server running the GraphQL Server. We still need to implement our own resolvers, of course.
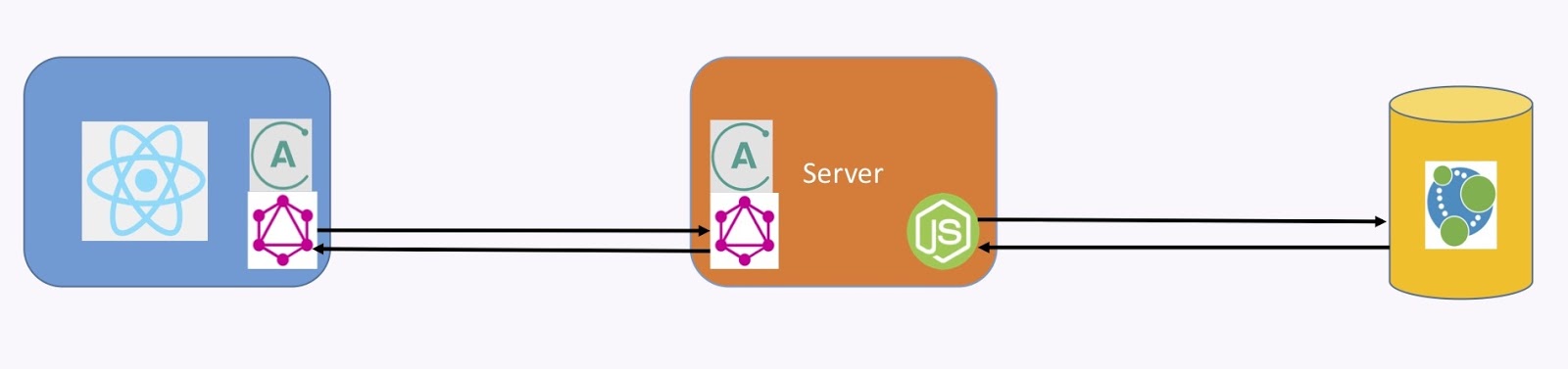
You can have a look at grandstack.io, download this and get going.
So, what’s the typical roadmap? How do you go about building something using GraphQL? Well, of course, you start with your business requirements. Then, you define your graph data model.
For the GraphQL part, you need to define the schema. We found that the important piece here is to describe the schema in the way your clients will use it. Again, you don’t have to define everything and you don’t have to expose everything – you just need to expose exactly what your clients need to use. No more, but no less.
Then, you implement the backend, your resolvers and mutators. You integrate Apollo into the Client using React.JS and you’re essentially done.
Share Article



Explore
Related Articles


Top 10 graph database use cases (with real-world case studies)

Win a $250 gift card: Build Conway’s Game of Life with GraphQL for AuraDB Beta

