
Neo4j: Real-World Performance Experience with a Graph Model

Matt Byrne, Stuart Begg, Andrew Sammons & Kaspar Minosyants, Senesis Agency Software Development Team
16 min read

[As community content, this post reflects the views and opinions of the particular authors and does not necessarily reflect the official stance of Neo4j.]
It’s All about Performance
Ultimately it’s the performance of your company as a whole which determines whether you remain in business.
It was with this thought in mind that we began a major project to improve the data management performance of Sensis, working out of Melbourne, Australia.
Sensis is Australia’s leading marketing services company, offering a range of digital and traditional marketing services, with over 300,000 customers. Over the past two to three years Sensis has been undergoing a transformation to ensure they have the right people, systems, products and technologies in place to deliver efficiencies and be able to take full advantage of all digital opportunities.
Our applications manage a large volume of time-sensitive information for and about our customers, so improving technology support and interactions with this information is key to business performance.
A little over year ago, we decided on Neo4j as our underlying data management tool for business information. We made the choice based on types of interactions with the information, the structure of the information and a desire to improve the flexibility of our data management strategy.
This article examines some of the aspects of implementing an enterprise system using Neo4j, with a particular focus on lessons learned about enhancing performance.
Learning – or Getting Started
This first task when introducing a new technology is make yourself familiar with the technology itself and to understand how it functions. Being on the other side of the planet from the Neo4j headquarters (more on that later), we started with the Neo4j O’Reilly book, Graph Databases.
We found, however, that the best quick start to understanding Neo4j is this free online course, in addition to a number of other great resources from around the web. See the end of this article for more resources.
Graph Data Modelling
The initial task was to model our business and Neo4j made this data modelling task simpler than a relational database store, given the natural transition of a whiteboarded model to a graph.
We had done extensive work on understanding the relationships and it was now time to formulate an appropriate model, and the components that make up that model.
Here’s what we found and did:
- Neo4j currently does not have a native date/time/timestamp value type.
- With regard to performance, Neo4j appears to have lower optimisation features around querying for
nullvalues. - Neo4j does not appear to use its indexing features when evaluating numerical inequality predicates.
- Neo4j does not appear to use its more modern indexing facilities for relationship properties.
We’ll cover the effects of each of these points in this article.
Neo4j with Dates and Times
Our model has a temporal requirement for versioning. However, Neo4j has no native support for dates and times. As such, our general approach is to store them as long integer values. This approach is much better than a formatted String for unambiguous comparisons.
While it may be obvious to many readers, when storing any date/time as milliseconds since Epoch, be sure to convert times to UTC first. This not only avoids ambiguity, but also avoids time shifts that local time zones may encounter, especially when daylight saving time starts and ends.
Within Java, Java 8 provides a fluent API for dates and times, and the Joda library does the same for those stuck with older (end-of-life) versions of Java.
Adopting a Time-Based Versioned Model
With our requirement for versioning, our system needed to keep an audit trail of all changes to the model, including the ability to retrieve the exact state of a part of the model at a given point in time.
We were directed to this very informative article on Time-Based Versioned Graphs by Ian Robinson and the approach seemed to suit our requirements nicely.
Robinson’s approach was to “separate structure from state” by storing a State node for every standard node that stores all of the business information (key-values).
Every change then creates a subsequent State. The standard nodes are referred to as “identity nodes”. All relationships have a from date and to date with the default to date being the maximum long integer value, 9223372036854775807, rather than null.
The idea being that if a relationship is no longer required you can expire the relationship by setting the to date to be the time of expiration (usually now), rather than physically deleting the relationship.
Adapting the Data Model
Since Neo4j supports having many labels for a node we decided to add a “base” label to all nodes depending on which of the two types they described – Entity or State.
Using the terminology from the article, we gave all identity nodes the base label of Entity and all state nodes the base label of State.
As an example, we have a node with the label ContentGroup. This would be modelled as follows.
MATCH (e:ContentGroup:Entity)-[r:HAS_STATE]->(s:ContentGroupState:State) RETURN e, r, s
This gives us two benefits: firstly, we can write Cypher statements around these abstract “base” labels, and secondly, we can define separate indexes and constraints across all Entity and State nodes.
We can now query all Entity nodes with associated states.
MATCH (e:Entity)-[r:HAS_STATE]->(s:State) RETURN e, r, s
Another adaptation we made to the article approach was to add a convenience for identifying the current relationships. Based on the approach taken in the article, the initial approach to querying an Entity with its current state would be as follows.
MATCH (e: Entity)-[r:HAS_STATE {to: 9223372036854775807}]->(s: State)
RETURN e, r, s
This approach requires that you remember the magic, maximum long integer when querying current state. For this reason we added a property, current, to all relationships that is set to true when the to date is set to the maximum long integer and set to false whenever it has been expired.
The query now looks like this:
MATCH (e:Entity)-[r:HAS_STATE {current: true}]->(s:State)
RETURN e, r s
We have embedded the logic that maintains the state of this flag within the layer that we use to interact with Neo4j. We maintain strict test coverage of this code so that we have confidence that the flag will not become inconsistent with the value of the associated to date.
Optimising Queries for Current State
Obviously there is storage and processing overhead associated with storing and retrieving State nodes for every Entity. It also adds complexity when mapping this model to and from objects in your code.
When writing to the database, the code needs to expire a State relationship if one exists for the Entity and then create the new State node. When reading, the code needs to use the values from the State node for a given Entity.
We found we could live with the overhead in writes. But, mostly, the queries that our application uses are only concerned with the current state. On top of this, we didn’t want all of our queries to have to deal with separate State nodes.
The aforementioned article has a section at the bottom listing “Variations and Optimisations” that addresses some of these issues. However, in our implementation, we simplified things a step further by always replicating the current state on the Entity node itself.
This means that the queries that are only concerned with the current state can be completely free of any state considerations. The query for all entities with current state now looks like this.
MATCH (e:Entity) RETURN e
As long as the query is either implicitly excluding State nodes by specifying the Entity label, or explicitly excludes State label nodes then the query will be back to its simple form.
This deviates slightly from “separate structure from state”, but it meets all of our requirements. In addition, the majority of our queries are simpler to maintain, have fewer database hits, and result in a smaller payload.
When we query historical data we simply revert to querying State nodes.
Tuning and Troubleshooting
Neo4j and Similarities to Relational Databases
Cypher is a bespoke database query language for Neo4j. However, it is inspired by SQL. The Neo4j team have made a very deliberate decision to make the transition easy for developers by keeping many idioms used in SQL.
In addition to this, some Neo4j schema and database tools share similarities with relational databases.
Backups and Restorations
Neo4j offers a simple solution to backups and restorations: replace the contents of the graph.db directory. When you backup a database you can either shutdown Neo4j and create a .tgz file containing the contents of the graph.db directory, or if you are on the Enterprise version of Neo4j, then you can create an online backup to a directory while Neo4j is still running, and then create a .tgz file from that directory.
To restore a database, you simply shut down Neo4j and replace your graph.db directory with the extract from one of the .tgz into that directory before restarting Neo4j.
Our environments are hosted in Amazon and so we store our backup files in an S3 bucket.
Here is an example set of commands to stop Neo4j, backup and start it back up again on an Ubuntu machine with an apt-get installation.
sudo service neo4j-service stop tar -czf /tmp/neo-backup.tgz -C /var/lib/neo4j/data/graph.db . sudo service neo4j-service start
And here’s an example of stopping Neo4j, clearing the graph.db directory, restoring the backup and starting Neo4j back up again.
It’s best to create a bash script for each of these two sets of commands because they will probably be used quite often.
sudo service neo4j-service stop sudo rm -rf /var/lib/neo4j/data/graph.db/* sudo tar -xzf /tmp/neo-backup.tgz -C /var/lib/neo4j/graph.db sudo service neo4j-service start
Profiling Cypher
To profile a Cypher statement there are two options: EXPLAIN and PROFILE.
EXPLAINwill show the execution plan without actually executing the statement or returning the statement results.PROFILEwill execute the statement and return the results along with more detailed profiling information.
These two options are similar to relational database profiling capabilities. When you are seeking quantitative results about tuning a Cypher statement then PROFILE is the one you should use.
When we profile queries against production data, we simply retrieve the latest backup from S3 and restore that to our local database. This way we don’t need to access a live production database, and we can operate within the safety of our own local machine.
When you start profiling, the next step is to understand the results. The Neo4j execution plan documentation provides a lot of detail and shows results from the neo4j-shell. Although the shell can provide more detail, the Neo4j web console (defaulting to https://localhost:7474) has a nice graphical output that can be easier to follow initially.
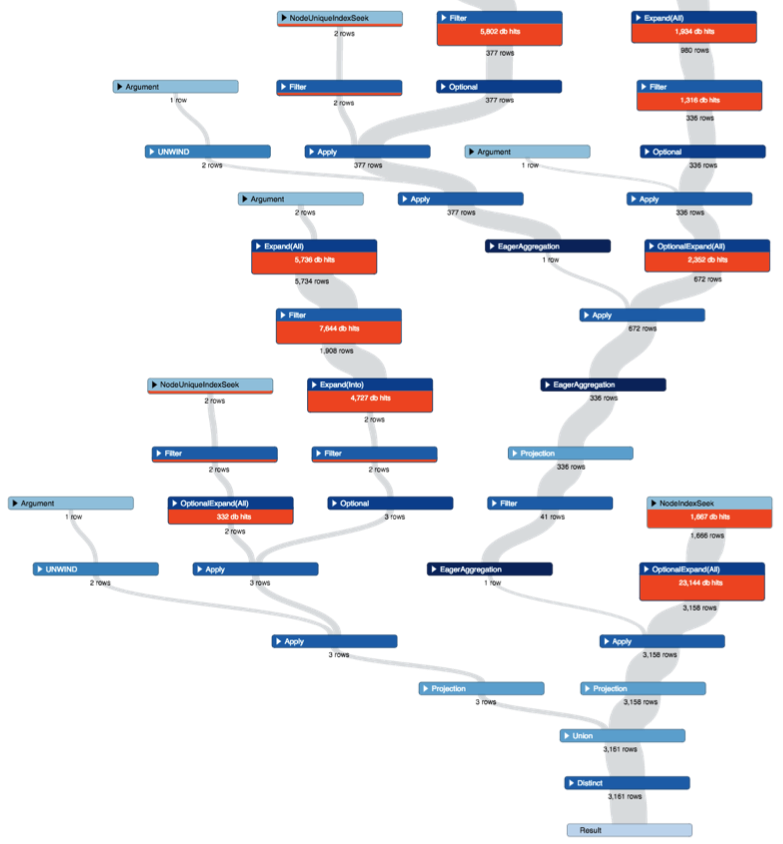
This can be especially true for complex queries. Below is part of the graphical profile output for a query we actually had to tune and in this case the visual plan made it much easier to follow.
At a high level, the goal is simple: get the number of database hits down.
Neo4j defines a database hit as “an abstract unit of storage engine work”. This is a much better metric to trace than the query execution time alone, as the number will be consistent.
Much like relational databases there is some “warm-up” while Neo4j internally caches and optimises, but even after a query is executed many times there are external factors such as garbage collection and server load that could also affect the execution time. The database hits metric is a constant, but keep an eye on execution times nonetheless!
Query Planners
When Neo4j translates a Cypher statement into an execution plan it uses one of two planners: Rule or Cost. The Rule planner is the original Neo4j Cypher query planner that uses pre-determined rules.
These rules utilise indexes to eventually produce the execution plan. The Cost planner was introduced in Neo4j 2.2 and utilises a statistics service to dynamically optimise the execution plan based on projected costs.
This blog gives a very detailed description of how the Cost planner works and how it can be much more efficient compared to the Rule planner. However, Neo4j does warn that it is still in early stages and care should be taken when depending on it.
As of the current release (2.2.5) and since 2.2.0, our team has noticed that under the Cost planner, a simple Cypher query retrieving a node by an indexed property refuses to use an index when Neo4j is under load and thus slows down dramatically.
The issue is currently being rectified by the Neo4j team. It must be said, too, that there are no reports that other customers are experiencing the same problem.
Other than instances where we see this issue, we have noticed that the execution plans generated by the Cost planner are significantly faster than those of the Rule planner.
Indexes
Indexes are a powerful tuning tool in relational databases and Neo4j also has indexes. The indexing capabilities in Neo4j, however, come with some limitations. (These are limitations as of the currently latest version 2.2.5, so if you are using a version later than this it may be worth double-checking these limitations still exist.)
- There are no composite indexes. Each index can only be applied to a single property.
- Indexes can only be used for exact value matching. Any range checks (such as
WHERE node.property < 100) will not utilise an index. - Indexes will not be used for
IS NULLchecks (or the inverse,NOT). - Relationship properties cannot be indexed (unless you resort to using “legacy indexes”).
The indexes are only used to find the starting node when generating an execution plan and Neo4j will then traverse paths from that point. For this reason, adding an index may not have the effect that you are seeking. So, take care to pay attention to profiling results of your queries.
One optimisation we made in relation to null values and indexes was to use a default, “dummy” value for a String property that is optional, but key to some of our queries. This meant that we could always search using an index, however it was one example of when we needed to consider “perfect” design versus performance optimisations.
Query Optimisations
Some simple tips for writing Cypher queries may be obvious to some but are worth noting.
- Apply an index to key properties that are used for filtering.
- Use labels effectively since labels form the backbone of indexing.
- Always parameterise your Cypher statements. Avoiding repeated conversion of raw Cypher to an eventual execution plan is done by literal comparison of the Cypher string. If the same Cypher can be supplied despite the parameter values, then this makes execution quicker.
- Where possible, specify the relationship type in the query even if there is only one type of relationship to your given node. This allows node traversal to end quicker, resulting in fewer database hits.
Our model is all based around root nodes with the ContentGroup label, with each ContentGroup containing descendants containing various pieces of content with children of children, with varying depth.
The model can be described as a directed acyclic graph, meaning that if you follow the relationships from a ContentGroup you will always arrive at a terminating point because no cyclic paths exist. The content within that ContentGroup is constantly evolving.
We needed to produce a Cypher query to return a ContentGroup with all of its associated content, without hardcoding the query to the specific labels.
Our first attempt at this query was similar to the following:
MATCH (cg:ContentGroup:Entity {identifier: {identifier})-[r* {current: true}]->(other: Entity)
RETURN cg, r, other
Here is a breakdown of that query:
MATCH (cg:ContentGroup:Entity {identifier: {identifier})
We manage our own unique identifiers (using UUID) and have a uniqueness constraint on Entity(identifier), so we must also specify the Entity label when querying to utilise the index.
-[r* {current: true}]->(other: Entity)
Find all other Entity nodes with a wildcard depth of relationships (r*). Since our model is acyclic we have confidence that the maximum number of relationships will never be infinite.
This query worked fine when our ContentGroups contained a small number of descending nodes, however when the ContentGroup was large (containing hundreds of nodes at various depths) then the query started to perform quite poorly.
This is because Neo4j interprets r* as finding every combination of relationships to a node – not just the longest relationship path.
This caused the number of database hits to rise sharply. Even when we limited this to a maximum depth (r*1..5) we still observed poor performance results.
We needed to keep the flexibility and ambiguity of the query above, while also improving the performance and achieving the goal of finding all nodes belonging to a ContentGroup. Our solution to this was an approach similar to tuning relational models: denormalise.
Most of the descending nodes within a ContentGroup can only belong to a single ContentGroup, so for those nodes we decided to set a rootId property with the value being the identifier of the ContentGroup.
With our model, any other descending nodes that can be shared between ContentGroups are always just a single relationship away from either the ContentGroup itself, or a node that has a rootId set to that ContentGroup identifier.
With this in mind, our query became the following:
MATCH (e:Entity {rootId: {identifier}})
OPTIONAL MATCH (e)-[r {current: true}]->(other:Entity)
RETURN e, other, r
Here is a breakdown of the optimised query:
MATCH (e:Entity {rootId: {identifier}})
Now we can simply look for all Entity nodes with rootId that is the specified ContentGroup identifier, which will also retrieve the ContentGroup itself.
OPTIONAL MATCH (e)-[r {current: true}]->(other:Entity)
Next, we need to retrieve the relationships between the matched Entity nodes and any other Entity nodes. This not only maps relationships between the already matched nodes, but it also finds any other nodes that are shared and thus do not have a rootId.
In actual fact, any nodes that are shared between many ContentGroups have the rootId property with a value of SHARED. Thus, we can search for these nodes in other queries (this is the performance tweak around nulls that we mentioned at the end of the Indexes section above).
This change to our data model and query had a dramatic effect on the number of database hits (and as such, query execution times) for a large ContentGroup in some of our queries.
The example profiles below show the differences between our two example versions of the queries.
The first profile shows the original results with the Rule planner, with 361,292 db hits and 47-second query time.

After switching to the Cost planner and using our optimised query the db hits went down to 33,743 hits and took easily under a second for our large dataset.

It’s easy to see the benefits through these profiles; however, we’ve seen much more dramatic differences in our larger, more complex queries. Note that the results above are based around a large ContentGroup and over 99% of the time this query returns in tens of milliseconds.
Of course there is a lot more to performance tuning than has been mentioned here. We also stumbled across this great tuning article that was recently written by Michael Hunger. The article mentions server configuration tweaks that we adapted as well as some not-so-obvious tuning tips and is a great read!
Dealing with the Neo4j Team from Australia
Our current team is based in Melbourne, Australia, and have a commercial agreement with Neo4j for the Enterprise version and support.
The support and general assistance we have received from the Neo4j team has been exemplary – especially when compared with that of some other large relational database vendors.
The fact still remains, however, that there is no Australian office and it does feel as though we are the other side of the world (as, in fact, we are). Logistically it’s no different from operating with any other distributed team across time zones, and the Neo4j team have been very accommodating.
Generally the Neo4j team does not externally speculate about expected features or confirmed bugfixes in upcoming releases, especially if you do not have a commercial agreement in place.
The easiest way to keep track of it all is to keep an eye on the GitHub commits directly. The issue tracking in GitHub is not their main tracking system either, so don’t depend on it too much. The Neo4j source code is just Java and Scala at the end of the day so take a peek through the code and follow their work.
Of course it also goes without saying that there is plenty of activity and support available on Stack Overflow from the Neo4j community.
Application Integration with Neo4j
We are running Java 8 and the latest Spring Boot, bundled as a self-executing jar. We needed to find a way to manage our database migrations from release to release, much like Flyway and Liquibase do for other types of databases.
A tool exists on GitHub, called Liquigraph, and is based on how Liquibase works. However, at the time of our development, it did not meet all of our requirements. We provided feedback through this comment (see comments from mbyrne00) about why the tool did not suit our needs, and we also provided ideas for further improvement.
We decided to implement our own solution, with the details being beyond the scope of this article. Our solution is based on the approach taken by Flyway and as such we named it Flygraph (original, right?).
Flygraph is currently too dependent on our internal modules and technologies to open source; however, we are more than happy to share details in a future article with code samples.
At a high level, it is purely focused on running Neo4j in Server Mode, it prevents multiple instances running migrations concurrently, it allows Java migrations (not just plain Cypher), it integrates with the Spring framework, it allows traceability and it optionally blocks selected web endpoints while processing.
Conclusion
Working with Neo4j has been an extremely rewarding and enjoyable experience.
Like any new technology, Neo4j comes with its own challenges and limitations; however, the benefits it brings have easily outweighed these limitations. We have been through an educating learning experience so we hope this article will assist others in getting started and having the confidence to introduce Neo4j to their technology base.
Further Information
Below are links to further information that have been referenced in this article:
- Learning and Reference
- Articles and Blogs
- Time-Based Versioned Graphs
- Introducing the new Cypher Query Optimizer
- 5 Secrets to Neo4j 2.2 Query Tuning
- GitHub
Need more tips on how to effectively use Neo4j? Register for our online training class, Neo4j in Production, and learn how master the world’s leading graph database.
Share Article



Explore
Related Articles



Text2Cypher Across Languages: Evaluating Foundational Models Beyond English


