
Neo4j with Scala: An Awesome Experience with Apache Spark [Community Post]

Software Consultant, Knóldus Software
2 min read
[As community content, this post reflects the views and opinions of the particular author and does not necessarily reflect the official stance of Neo4j. This was originally posted on the Knoldus blog and was used with permission.]
Editor’s Note: For more information on the Scala driver for Neo4j – AnormCypher – check out our developer page here.
Let’s continue our journey once more in this Neo4j and Scala series. In the last blog, we discussed data migration from other databases to Neo4j. Now we’ll discuss how we can combine Neo4j with Apache Spark.
Before starting today’s post, here’s a recap of everything we’ve covered so far:
- Getting Started with Neo4j and Scala: An Introduction
- Neo4j with Scala: User-Defined Procedures and APOC
- Neo4j with Scala: Migrate Data from Other Databases to Neo4j
We know that Apache Spark is a generalized framework for distributed data processing providing a functional API for manipulating data on a large scale, in-memory data caching and reuse across computations.
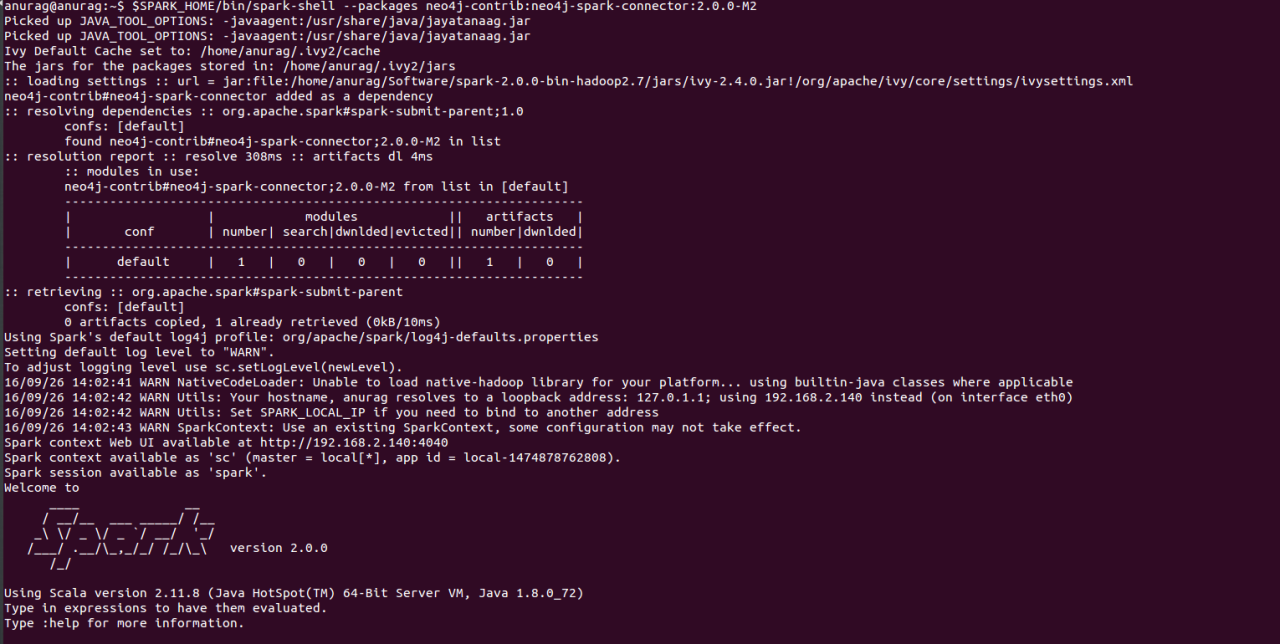
Now when we are using Neo4j as a graph database and we have to perform data processing, we can use Spark for data processing. We have to follow some basic steps before can start playing with Spark:
- We can download Apache Spark 2.0.0. Here we have to remember that we can only use Spark 2.0.0 because the connector we are going to use is build on Spark 2.0.0.
- Set the
SPARK_HOMEpath in the.bashrcfile (for Linux users). - Now we can use the Neo4j-Spark Connector.
Read the rest of this blog post on Neo4j and Scala by Anurag Srivastava on the Knoldus blog.
Share Article



Explore
Related Articles





