
A *Decade* of Graphs: Neo4j’s Top 10 Biggest Moments of the 2010s

Editor-in-Chief, Neo4j
8 min read

It’s a story too good not to tell: When you take a look back at everything that’s happened in the Neo4j community over the past 10 years, it’s amazing to see how far we’ve come.
What the decade began, Neo4j was a small, shy, open source community clustered around a bunch of alpha geeks (that’s a compliment!) in Malmö, Sweden. And now, Neo4j is the clear leader in the graph database sector – a sector the community created from scratch – with hundreds of customers and thousands of developers around the globe.
The story of Neo4j’s past decade is full of inspirational moments, big announcements and industry earthquakes. But, more than anything else, it’s a story of a generous, helpful and authentic community of developers growing the Neo4j graph one relationship at a time.
Of course, there were way too many cool moments to include from the past decade to fit into a single article, so we settled on the biggest event that happened in each year. (If you want the unauthorized Director’s Cut straight from the hands of Emil, I’ll meet you around back.)
Let’s dive in:
2009: Neo Technology Closes $2.5M Seed-Stage Investment
![]()
When the decade began, Hadoop was all the rage as it ushered in the Big Data phenomenon. But on the eve of 2009, in a quiet corner of the data management world, a technology known as Neo4j was about to have its first big moment.
Back then, Neo4j positioned itself as a netbase – short for network-oriented database – before co-founders Emil Eifrem, Johan Svensson and Peter Neubauer finally struck upon the name graph database due to its origins in graph theory.
But the biggest news of 2009 was much more significant: In October, Neo Technology – the commercial company behind Neo4j – closed its seed-stage investment with kickass VC firms Sunstone Capital and Conor Venture Partners (both of whom still back us today). With $2.5 million USD in the bank, they moved the company headquarters to Menlo Park, California and set up shop in Silicon Valley.
2010: Neo4j 1.0 Is Released
In early 2010, we were proud to announce the GA release of Neo4j 1.0. At that point, the world’s leading graph database was still the world’s only graph database, and features like the Cypher query language weren’t even around yet.
However, a recently released archive photo from that period confirms that Neo4j 1.0 looked absolutely adorable:

2011: Spring Data Neo4j Is Born
![]()
As the young Neo4j community grew, developers needed more language drivers and connectors.
2011 was the year Spring Data Neo4j (originally known as “Spring Data Graph”) joined the Neo4j ecosystem for developers working with the Spring framework. The original Spring Data Neo4j work was completed by the (already) legendary, unstoppable Michael Hunger.
(If you’re curious about the current state of Spring Data Neo4j, check out our developer guide here.)
2012: The 1st-Ever GraphConnect Kicks Off
![]()
The Neo4j community – like the graph database – is powered by connections. But human relationships are best cultivated face-to-face, so in 2012, we launched the inaugural GraphConnect conference in San Francisco.
It went pretty well, apparently, because we kept on hosting it year after year – and in 2020, you’re in for the GraphConnect of the decade.
2013: Neo4j 2.0 Transforms Graph Data, Again

We promise this isn’t just a scrolling list of every Neo4j release, but 2013 was an exceptionally important year for graphs.
Why? Because Neo4j 2.0 shipped with the brand-new Cypher query language and the Neo4j Browser, both of which would ease the adoption of graph database technology for developers around the globe. There’s a reason after all, that we titled the announcement “Graphs for Everyone.”
2014: Graphs Get Serious with O’Reilly

In 2014, a seismic shift occurred in the adoption of graph technology.
That shift followed the publication* of the O’Reilly book Graph Databases co-authored by Jim Webber, Ian Robinson and Emil Eifrem. The book showed the world that graph databases were a technology to be taken seriously, and a lot of developers joined the graph movement as a result.
*[The first edition was published in 2013 but to a limited audience. The second edition dropped in 2015 to a lot more fanfare. We settled for the median of the two dates.]
2015: openCypher Says “Hello, World.”
So, so much happened in the Neo4j community in 2015, but we swore we’d only pick one item per year.

By far, the biggest moment of 2015 was the announcement of the openCypher project (released live during Emil’s keynote at GraphConnect!). The openCypher project began the opening up and adoption of the Cypher graph query language to multiple graph database vendors, serving as the “SQL for graphs.”
As an integral part of Neo4j, Cypher had helped the world better understand the labeled property graph model, giving developers a new way to create, query and harness their connected data. Developers use Cypher to turn pages of byzantine SQL queries into a few lines of elegant, human-readable code.
Releasing this superpowered query language to the wider graph community via the openCypher project meant the best graph minds around the globe could contribute to its further evolution. Little did we know back then, but the openCypher project would become the forerunner of the standardization movement around Graph Query Language (GQL) just five years after its initial announcement – more on that below.
2016: The Panama Papers Are Powered by Neo4j
On 3 April 2016, the biggest data leak in recorded history was published worldwide by the International Consortium of Investigative Journalists (ICIJ).

The 2.6 TB of data revealed the financial dealings of over 200,000 offshore entities – many of whom were hiding dirty money or evading taxes – including 12 current world leaders and hundreds of other public officials and celebrities.
Journalists at the ICIJ used Neo4j to decipher the 11.5 million documents and files included in the leak, and the Neo4j community grew massively as more citizen developers saw the potential of graph-powered data journalism.
2017: Neo4j Gets Inc.-ed

In 2017, we finally said goodbye to Neo Technology…and we officially changed our company name to Neo4j, Inc.
With the change, we accepted the fact that “Neo4j” is how the world has always known us, and it signalled our continued commitment to Neo4j – the open source graph database project.
(This announcement isn’t to be confused with that other time we jokingly talked about changing our name. That was just a really clever April Fools’ Day prank.)
2018: Neo4j Closed the Largest Single Investment in the Graph Space

In late 2018, Emil was thrilled to announce that Neo4j had just closed $80 million in a series E funding round. The round meant that Neo4j had raised a total of $160 million in growth funding, representing the largest cumulative investment in the graph technology category.
Emil marked the event by talking about the new Cambrian explosion of graph-powered artificial intelligence just over the horizon.
2019: GQL + AuraDB Make Waves
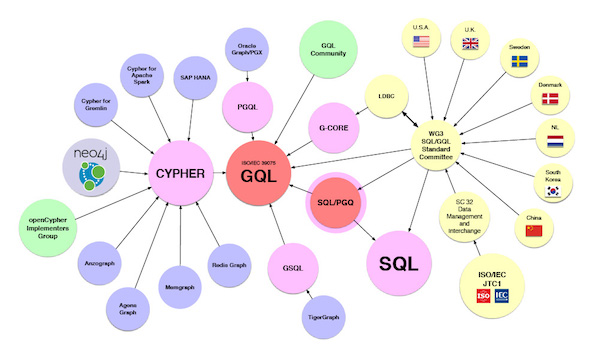
Okay, we cheated on this one and just had to pick two moments. We promise you’ll understand!
First, in September, international standards committees voted to make Graph Query Language (GQL) the first ISO/IEC international standard database language project since the development of SQL. The addition of GQL as an international standard is good news all around for the graph tech ecosystem.

Then, in November, we launched Neo4j AuraDB, the first fully managed native graph database as a service. As Neo4j’s first cloud offering, AuraDB is a game changer for small and mid-sized businesses who want to harness the power of connected data.
(2019 was sorta a huge year for the Neo4j community, so for a more detailed recap, check out our 2019 year in review article.)
The Honorable Mentions
The 2010s were a busy decade for the Neo4j community, so we’d be remiss if some of these other key events of the past ten years didn’t at least get a shout out:
- 2009: The Neo4j APOC library made its debut, albeit under a way less cooler acronym.
- 2010: Facebook started using the term “graph” in the alpha geek sense – with their Graph API and Open Graph Protocol – which was a big boost toward graph understanding among non-graphista developers.
- 2011: We began naming Neo4j milestone releases after Swedish train stations along a north-to-south route ending in Malmö. Every adolescent database goes through a Swedish-train-station-naming phase, and this was our year.
- 2013: This year saw the advent of the famous (infamous?) Beer Graph, first built by Rik Van Bruggen.
- 2014: Nearly 12 years after Neo4j was first developed, we finally created and consolidated our web activity around Neo4j.com. We’re not sure exactly why, but apparently we had to try to sell it really hard to the community back then. Seems simple enough?
- 2015: The Graphistania podcast – hosted by graphista Rik Van Bruggen – published its first interview with Michael Hunger from Developer Relations.
- 2016: Neo4j raised its largest fundraising round (at the time) in our series D round worth $36M. Some of us wanted Emil to do a particular song and dance to celebrate…but he declined.
- 2017: In the strongest validation of the graph market to date, Amazon Neptune unveiled their own graph database, Amazon Neptune. Emil welcomed Amazon’s entry as a rising tide that would lift all boats – and as a boon to all end-users of graph technology.
- 2018: At GraphTour SF, we announced the forthcoming release of Neo4j Bloom, a brand-new graph data visualization tool for both technical and non-technical graphistas alike. Neo4j officially became a two-product company(!).
- 2019: The unstoppable duo, Amy Hodler & Mark Needham, published their book with O’Reilly: Graph Algorithms: Practical Examples in Apache Spark and Neo4j.
Psst! What other events or announcements did we skip?
2020: Graphistas Conquer the Globe
As the next decade dawns, it’s impossible to say where the global graph community might go next. (Emil will, of course, share his thoughts later this week!)
But if the 2020s are anything like the journey that transpired over the 2010s – which went from “What do we call it? Maybe, like, uh a…graph…graph database?” to “GQL was just accepted as an ISO/IEC standards project” – if the 2020s are anything like that journey, then we have a lot to look forward to.
And you know what’s going to make it all happen? Building and nurturing the graph tech community one relationship at a time. So keep up the good work.
Get your free copy of the O’Reilly book Graph Algorithms: Practical Examples in Apache Spark and Neo4j and learn how to put graph algorithms to work on your connected data.
Share Article



Explore
Related Articles

Neo4j Named a 2025 Gartner® Peer Insights™ Customers’ Choice for Cloud Database Management Systems



Neo4j Graph Analytics for Snowflake: Bringing Graph-Powered Insights to the AI Data Cloud

What Are the Different Types of Graph Algorithms & When to Use Them?
