Neo4j enables up to 100x faster analytics and real-time decision-making

Chief Product Officer, Neo4j
8 min read

Today, we’re thrilled to announce major new capabilities for operational and analytical workloads that enable cloud customers to drive up to 100x faster analytics and real-time decision-making on a single database.
- Parallel Runtime based on morsel-based parallelism, splits complex analytical graph queries into concurrent threads across multiple CPU cores, increasing query speed up to 100x.
- Native Change Data Capture (CDC) automates tracking and notification of database changes so organizations can make mission-critical decisions in real time.
- Knowledge Graph Embedding models find missing relationships and infer new connections within knowledge graphs for greater semantic understanding.
- New Pathfinding Algorithms make complex workflows more efficient by identifying critical paths between graph nodes and determining the best sequence for dependent tasks.
These new capabilities are designed to help organizations dramatically accelerate graph analytics and develop the next wave of real-time, mission-critical applications. They reflect our vision of a simpler, more powerful graph database and analytics offering that integrates seamlessly into existing enterprise architectures.
Neo4j partners like GraphAware are already leveraging these new capabilities to help organizations improve business and operational outcomes.
“Neo4j’s new capabilities enable modern law enforcement to fight more crimes and solve them faster,” says Christophe Willemson, CTO of GraphAware. “They can react with greater agility to mission-critical events — for example, sending alerts to front-line officers when the phone number of a person of interest pings from a cellular tower near a high-risk event where a VIP is present.”
Experience the new capabilities firsthand. They’re available to try today at no cost with Neo4j AuraDB. Below, we dive deeper into what each capability delivers.
Building a database for all your operational & analytical needs
Parallel runtime
Parallel Runtime dramatically reduces the response times of analytical queries, which are often “graph-global,” meaning they need to traverse large parts of the graph to uncover complex or hidden patterns. Neo4j has dipped into academics to find an innovative solution based on morsel-based parallelism. Parallel runtime splits those queries into multiple software threads, which run concurrently across multiple CPU cores — increasing query speeds by up to 100x.
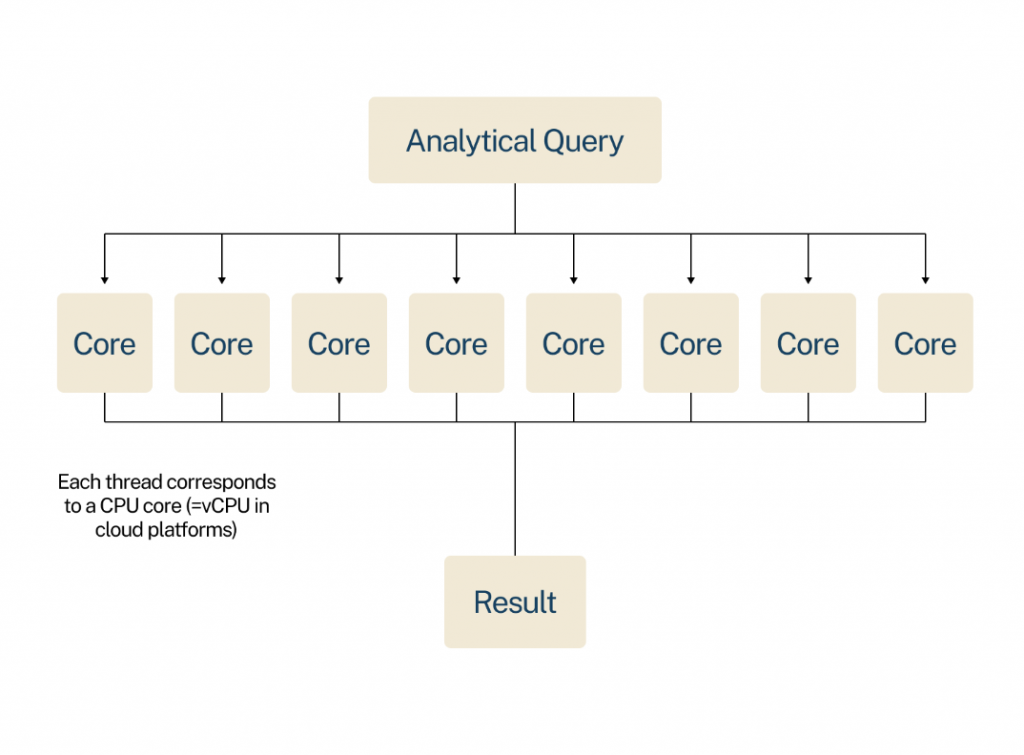


Neo4j customers can now increase resource efficiency by performing transactional and analytical processing on the same database. Most graph databases aren’t designed to mix transactional and operational workloads this way, and RDBMS systems even require a second database for analytical workloads.
Parallel runtime accelerates analytical queries such as:
- Supply chains: Find food retailers supplied by wholesalers that buy eggs or poultry from farms within 5 km of reported avian flu cases.
- Social networks: Find VPs of marketing aged 18–54 who live in San Francisco or Seattle, went to Stanford, and work at Magnificent Seven firms.
- Cybersecurity: Find users who have logged into a host that communicated in the last 24 hours with a host that ran an executable with an unsigned certificate.
Change data capture
Change Data Capture (CDC) tracks and records data changes in real time so customers can take mission-critical actions based on current data. We’ve implemented CDC by recording data changes to a transaction log and providing an API that reads from the log:

If you use the streaming platform Confluent for event messages, we’ve enhanced our Confluent connector so that target systems can “subscribe” to a set of Neo4j changes. Those changes can then be published as “topics” in the Confluent data stream.
CDC delivers benefits across a variety of use cases, including:
- Identity and access management: Modify privileges in IAM applications the moment an employee is hired, promoted, or leaves.
- Master data management: When a recording artist releases new material, propagate new songs and lyrics to all applications in the creative and distribution life cycle.
- Law enforcement: When a young person’s image is detected in a police body camera footage, trigger necessary alerts.
- X360: Upgrade a customer’s churn risk the moment new information about that customer arrives.
- Supply chain: Send messages to any impacted manufacturing processes as soon as an order is modified.
Anil Masakal, Engineering Leader for Search and Answers Infrastructure at Dropbox, highlights the value of Change Data Capture:
“Neo4j’s Change Data Capture enables us to synchronize the latest changes happening in our customers’ various data sources instantaneously. It helps us guarantee that when they use Dropbox Dash, they can search and find their content accurately.”
Knowledge graph embedding
Customers now have a more powerful way to find missing relationships and infer new relationships in their knowledge graphs. Once you’ve created a Neo4j knowledge graph, you can export and train it and bring the generated embedding models into Neo4j Graph Data Science as properties. Similarity comparisons can then help predict missing relationships between entities, infer new relationships, and improve semantic understanding and reasoning.
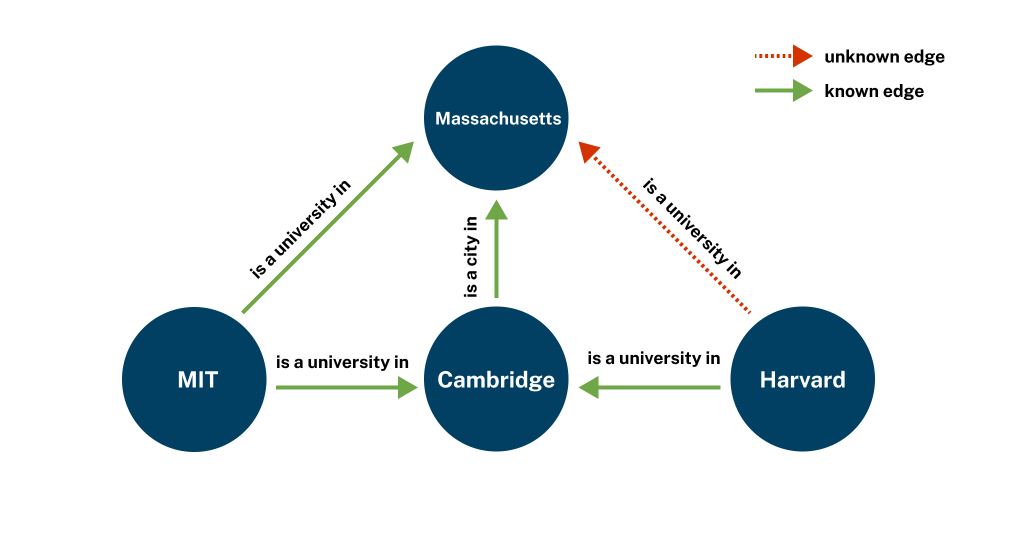
Tailored just for your data, our knowledge graph embedding technique improves prediction accuracy. It outperforms third-party algorithms by learning the specific relationships present in your knowledge graph. You can use it for:
- Generative AI: Improve accuracy during grounding by identifying missing relationships and making search results more relevant with a semantic understanding of relationships.
- Recommendation engines: Widen the range of recommendations by capturing different types of interactions between entities — e.g., recommend items not only similar to a user’s favorites but also complementary or related items.
- Semantic search: Semantic relationships like “part-of” and “related-to” can be encoded in the embedding, so search results include relational context.
- Life sciences: Predict drug target interactions, side effects, or protein binding, and discover similar molecules based on interaction data.
New pathfinding algorithms
Longest path
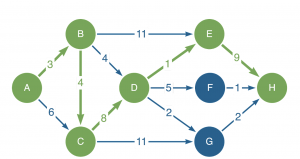
Our newest pathfinding algorithm – the thirteenth addition to our Graph Data Science library – identifies the longest path between two nodes. It enables organizations to optimize complex scheduling, for example:
- Supply chain/resource allocation: If tasks on a critical path are completed late, project delays often ensue. Identifying and allocating resources to those tasks can be critical.
- Resource allocation: Topological sorting can help organizations allocate resources (labor, vehicles, tools, warehouses) for every task in a complex sequence.
- Demand forecasting: Demand forecasting models can be integrated with topological sorting algorithms to ensure supply chains adapt quickly as demand shifts.
- Building software projects: Topological sorting helps establish the correct order for building components with multiple dependencies (libraries, jobs, modules, etc.).
- Supply chain optimization: Managers can ensure products are made, shipped, and delivered efficiently by ordering the movement of goods — from suppliers, manufacturers, and distributors to retailers and customers.
- Inventory management: With access to demand forecasts and production schedules, topological sort algorithms can determine the order in which inventories should be stocked or replenished.
- Solving complex problems in historical research.
- Analyzing glycochemistry to fight cancer.
- Improving public transit efficiency.
Topological sort

The fourteenth pathfinding algorithm in our Graph Data Science library sorts nodes in a directed acyclic graph by traversing them in order of dependency. This helps ensure that dependent tasks in a sequence are performed in the right order and prevents cyclic dependencies from causing deadlocks or incorrect program behavior. Topological sort has a wide variety of uses, from construction and shipping to demand forecasting and inventory management:
Building with the wisdom of the Neo4j community
These latest innovations were fueled by collaboration with our incredible open-source community, which has grown to more than 250,000 developers, data scientists, and architects across thousands of businesses, government agencies, and NGOs. It’s the largest community of graph practitioners and experts in the world, and it allows developers — including our own — to tap into knowledge developed over a decade of collective problem-solving.
We’ve watched the top minds in graph technology engage with the Neo4j community to solve previously unsolvable problems, transforming businesses around the globe in the process. Our new feature set represents another such transformation. We’re grateful to the Neo4j community — you’re essential to our evolution.
Speaking of collaboration, our annual conference, NODES 2023, is right around the corner. It’s a great opportunity to connect with your fellow graph practitioners and dig into fascinating graph use cases, including:
Leading graph technology innovation
These latest innovations join our recent milestones to solidify Neo4j’s position as the Graph Database & Analytics leader.
We recently integrated native vector search into our core database capabilities, enabling more accurate, explainable, and transparent outcomes for LLMs and other GenAI applications. We also launched a new GenAI data stack that makes it easy to start building apps enhanced by generative AI.
These innovations build on recent recognition, including winning Google Cloud’s 2023 Technology Partner of the Year award and being recognized in Gartner’s Magic Quadrant for Cloud Database Management Systems. With this momentum, we are ready to accelerate the pace of graph technology breakthroughs even further in the year ahead.
Get hands-on with the new capabilities today. Sign up for AuraDB Free, join our community, and let us know what you want to see next.
Share Article



Explore
Related Articles

Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report


1 of 3: The difference between a graph, a knowledge graph, and a context graph

2 of 3: Why graphs, knowledge graphs, and context graphs matter to customers
