Network science: the hidden field behind machine learning, economics and genetics that you’ve (probably) never heard of – an interview with Dr. Aaron Clauset [Part 2]

Graph Analytics & AI Program Director
8 min read

Last week, in part one of my interview with Dr. Aaron Clauset, we reviewed how network science was evolving and how it’s dismantling preconceived notions about networks in general. Clauset also stressed the crucial role of interdisciplinary collaboration when it comes to network science.

Dr. Aaron Clauset is an Assistant Professor of Computer Science at the University of Colorado Boulder and in the BioFrontiers Institute. He’s also part of the external faculty at the Santa Fe Institute (for complexity studies).
This week, we’ll dive into how advancements in network science are impacting predictions based on connected data.
Which domains are making the most advancements in network science?
Clauset: We’re beginning to realize that interactions – which is what networks represent – are the way to understand complexity of all different kinds. All social processes at the population scale are complex and all biological processes at scale are complex.
One area that’s particularly interesting to me is computational social science, in part because there’s a lot of new data and many companies are terribly interested in predicting how people will behave. So we have data, interest and support.
In biology, the traditional approach to disease has been to find the one thing that’s broken and fix that. But it turns out that when two things are broken it’s much harder. When 1000 genes are involved and each compensates for others in some way, that’s a network problem. Many of the advancements coming in computational biology – like gene therapies – are related to looking at biological networks.
I’m really optimistic about what these two disciplines will do to drive network science. A lot of that will depend on developing new tools for answering both new and old questions.
What kind of tools do we need to develop?
Clauset: Everyone would like a “Google Maps for networks,” so you could see the big picture but then also drill down in different areas. Just being able to visually explore some of these network datasets and develop hypothesis would be helpful.
But it’s much easier to visualize the underlying geometry geographic data that makes it possible to zoom in and out between different scales. Network visualization is much harder because networks aren’t three dimensional.
To see anything at all, you have to use statistical tools and have an idea of what you’re looking for. As a result, it’s inherently hard to know what’s being hidden from you by the tool. People are working to solve this problem, but progress has been pretty slow.
Another exciting area is, of course, machine learning. Networks present a special challenge for standard machine learning techniques because most techniques – including deep learning – assume that observations are independent and by definition that’s not true in a network. Building new tools that can work with networks is an important area of work now.
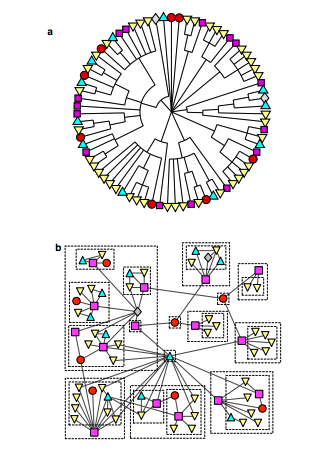
Taken from, “Hierarchical structure and the prediction of missing links in networks“
The machine learning community is incredibly good at developing tools and algorithms, including network methods. But, let’s be honest, most of the fancy techniques aren’t great in many practical settings because they’re too complicated. If a company wants to extract insights from their data, they need to know how the tool will fail and when it can lead them astray. The more complicated the technique, the less likely you are to understand how it actually works – and that’s a huge problem, especially in network settings where things interact.
Deep learning is a great example of a powerful technique that we don’t really understand yet, but it also clearly works in practice. But how and when does it fail? Failure modes end up being surprisingly important.
One fascinating area of work on failure modes is on algorithmic biases and measures of fairness. Another is on interpretable models, meaning models that a human can inspect to figure out what they are doing. For networks, probabilistic network models are a powerful and interpretable technique, and this area is one of my favorites for innovative network tools.
Is your research group working in these emerging areas of network science?
Clauset: One area of focus in my group is on probabilistic models for networks, and a long-running effort has been to develop techniques that learn from as many different types of auxiliary information as possible: dynamic information like node and edge changes over time and also metadata like node annotations and edge weights.
The models we build are generally interpretable and relatively simple, while still digesting all this information to make predictions: detecting anomalies; sensing change points in dynamics; and predicting missing links or attributes.
One of my students is working on an approach similar to what was used to win the Netflix Prize but for link prediction. We take a dozen state-of-the-art “community detection” algorithms, combine them with 35 measures of local network structure, and then learn a model to figure out how to combine them all into highly accurate predictions.
This approach is an example of the same ensemble method that won the Netflix Prize competition. These results are particularly exciting both because the performance is remarkably good and because the tool is revealing new insights about how different networks are structured.

A word cloud from Dr. Clauset’s research with the Santa Fe Institute.
This kind of algorithm development depends on having a large and diverse corpus of network datasets, and that is precisely what the ICON dataset provides. Like with a lot of machine learning techniques, this kind of work is very data needy, and we used nearly 500 networks from every domain imaginable to train the model, and as a result, it provides much better generalizability than if we trained it on the usual half-dozen datasets.
One goal of this project is to create a website that will perform all the backend calculations for you. You upload your data, the algorithms run and out spits different predictions.
What other research or work should we watch out for?
Clauset: Another of my students, Anna Boido, just put out a paper called Scale-free Networks Are Rare, which used the ICON index data to test another idea from early in network science: the claim that all networks are “scale free.”
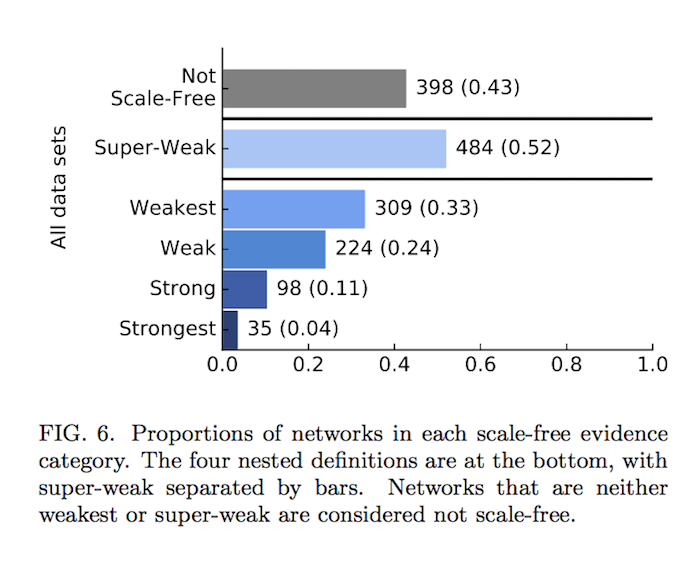
Taken from, “Scale-free Networks Are Rare“
Performing rigorous statistical tests on nearly 1000 network datasets of all different kinds, we found that only 4% exhibited strong evidence of being scale free. Evidently, a genuinely scale-free network is a bit like a unicorn. That said, degree distributions in most networks are, in fact, very heterogeneous, and this simple pattern by itself can lead to lots of interesting dynamics, e.g., in the spread of disease or memes.
Much like Kansuke Ikehara’s work, the take-home message here is that there’s much more structural diversity in networks than people previously thought, and some beliefs may need to be sacrificed if network science is to move forward. One of the tremendous things about the ICON dataset is that it provides a powerful, data-driven view into network structure, and we’re really excited about all the new discoveries that will be made by studying these large groups of real-world networks.
Taken from, “Hierarchical structure and the prediction of missing links in networks“
Is the study of structure the next big thing in network science?
Clauset: The study of structure is a crucial part of the study of networks. The big question is: how does the network’s structure shape the dynamics of a complex system?
This gets right back to the micro vs. macro question from last week, but ultimately, the big question is really about function. Connecting structure and function has always been difficult. But, there are many places where significant advances are happening.
Neuroscience is one where network science is helping make sense of new and very detailed datasets to unravel the way brains work. Ecology is another area where scientists have made great progress in understanding structure and function, particularly in food webs.
The basic idea is that network structure and interaction dynamics shape a system’s function. Certainly, structure constraints dynamics by determining who interacts with whom, and dynamics can drive structure, especially if interactions can be formed or broken. Anytime a system does something or carries out some kind of task, that function has to be related to dynamics and structure.
Studying structure helps us think about function and – as it turns out – there’s just a lot of work to be done yet to understand structure. Connecting these two is surely where a lot of big discoveries are lurking. I’m excited to see what comes out of exploring the true structural diversity of networks across domains, and the scientific explanations that are developed to explain it.
Conclusion
That wraps up our interview with Dr. Aaron Clauset on the hidden field of network science and how it’s revolutionizing the world around us – even if you can’t always see it. If you missed part one of our interview, catch it here.
Share Article



Explore
Related Articles
Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report

SumoDB in Neo4j: Chaining Multiple Graph Algorithms in Snowflake — Part 3



Why machines need embeddings: Turning graph structure into features
