
New Supervised Machine Learning Workflows in Neo4j!


4 min read

Just a few months ago, we announced graph-native machine learning in Neo4j with graph embeddings and an ML model catalog. Applying state-of-the-science machine learning for graphs was super exciting for many of you (and us!), and we’re thrilled about the creative applications the community has deployed.
Today, we’re announcing our GDS 1.5 release, which brings you more of the features you love: new algorithms, more machine learning, and easier production deployment!
In the latest release of the Neo4j Graph Data Science (GDS) Library, we’ve packed in a lot of features and enhancements – including two new algorithms, performance improvements for some of your existing favorites, and a new low-memory format optimized for large graphs.
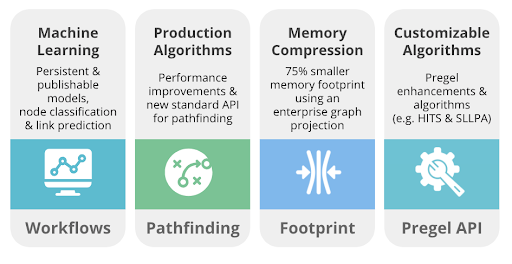
Major Enhancements in Neo4j GDS version 1.5
In this release, we’re most excited to bring you ML workflows – supervised machine learning to predict node labels and missing relationships – along with the tooling to enable better collaboration in production environments (because you asked for it).
With GDS v1.5, you can create an end-to-end model-building pipeline to take advantage of advanced ML techniques and continually update your graph – all without leaving Neo4j!
Supervised ML Workflow in Neo4j
Let’s walk through the kind of workflow that’s now possible in Neo4j: combining graph algorithms and graph embeddings for high-quality feature engineering, training supervised ML models to “fill in the blanks” about missing node labels or relationships, and then saving and sharing your models with your team.
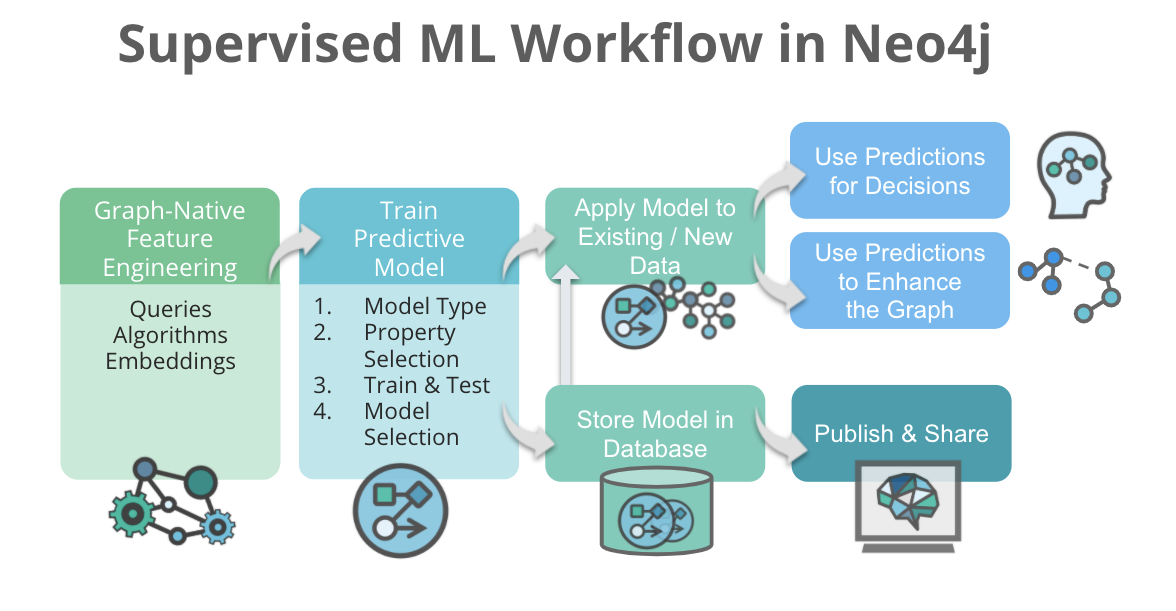
Graph-Native Feature Engineering
Once you’ve got your data into Neo4j, the first thing you’ll want to do is use graph algorithms and graph embeddings to explore your data, identify trends and outliers, and generate high-quality features that can be used in your predictive model. We introduced graph embeddings in our last release. And we like to think of them as the graph algorithm to use when you aren’t quite sure what you’re looking for, but you know that the graph structure is important:
Quick Tip: A graph embedding isn’t human readable like a community ID or centrality score you might get from running a traditional graph algorithm. It’s a set of numbers that represent parts of your graph, but it’s in exactly the right format for use in machine learning algorithms.
Once you’ve enriched your graph with algorithm results – like centrality scores or community membership – or generated ML representations with embeddings, it’s time to train a model!
Training a Predictive Model – in Neo4j!
One of the primary motivations for doing graph data science is to make predictions about your graph: Graph algorithms help you make better predictions by generating highly informative features, but predictive models help you enrich your graph by predicting missing node labels or properties or predicting missing or unobserved relationships.
With the Neo4j 1.5 release, we’re enabling you to train supervised, predictive models all in Neo4j, for node classification and link prediction.
How does this work?
- Identify the type of model you want to build – a node classification model to predict missing labels or categories, or a link prediction model to predict relationships in your graph.
- Decide which properties you want to use to make your predictions.
- Neo4j then performs a train/test split of your data, builds various models, evaluates results, and then returns the best-performing predictive model.
- Now apply this trained model to new data (unobserved parts of your graph, or fresh information) to predict missing information, as well as provide confidence scores for those predictions.
For example, let’s imagine you have a retail transaction graph: customers and the items and services they’ve purchased. You could use node classification to predict which customers are most likely to make returns, or churn from your service. Or, you could use link prediction to predict new relationships between customers and items they’ll buy in the future to make recommendations.
By allowing users to train and apply models within Neo4j, it’s now possible to extract new facts and continually enhance your graph.
Persisting and Sharing an ML model in Neo4j
It’s also now possible to persist some ML models in Neo4j – so they’re stored in the database and survive restarts – and share models among teams.
After you train your models, you can see them in your model catalog, which lists each available model and provides metadata about the type of model, configuration data, and model specific details.
Once you’ve trained a model that you like, and want to persist it, GDS Enterprise Edition users can store models – save them to disk – making them available after the database restarts. You can also load and use any existing stored model (no retraining!).
Users can also publish their models, sharing them with their team members, so anyone using the same database case can apply these models to their data.
With GDS 1.5, you can train a node classification or link prediction model in the Neo4j database, persist that model, manage it, store it, and share it with your team using graph-native customized code.
Conclusion
Until now, few companies outside of leading Big Tech have had the resources and ability to take advantage of advanced graph-based ML techniques. Neo4j for Graph Data Science is the first and only commercially available graph-native ML functionality for enterprises.
If you’d like to hear more about the latest supervised ML workflow, register for our webinar Supervised Graph Machine Learning: Now in Neo4j on March 11, where we’ll walk through an example and be available for your questions.
To get your hands on the latest from the GDS Library, visit our download center or go straight to our GitHub repo.
Cheers,
Dr. Alicia Frame and Amy Hodler
Get the book Graph Data Science For Dummies for free now.
Share Article



Explore
Related Articles

Mastering Fraud Detection With Temporal Graph Modeling

What Are the Different Types of Graph Algorithms & When to Use Them?



Neo4j Expands AWS Collaboration With New Competencies in Finance, Automotive, GenAI, and ML
