








Neo4j 2.0 will let you define sets of nodes within the graph
Update: 2.0.0-M02 is now available
 |
| Philip Rathle Senior Director of Products |
Update: 2.0.0-M02 is now available
Today we are releasing Milestone Release Neo4j 2.0.0-M01 of the Neo4j 2.0 series which we expect to be generally available (GA) in the next couple months. This release is significant in that it is the first time since the inception of Neo4j thirteen years ago that we are making a change to the property graph model. Specifically, we will be adding a new construct: labels.
We’ve completed a first cut at a significant addition to the data model, and are opening the code up now for early comment. Consider this milestone to be an experimental release, intended to solicit input. We look forward to hearing how you’d like to use these new features, and can’t wait to hear what you think.
It’s a What?
Let’s say you created a node for a person named Joe. Joe is not just any node: he is a person. Therefore you would probably want to designate the node for Joe as being a “Person”. If you’ve worked with Neo4j before, chances are that you’ve done this by adding a property called “type” with value “Person”, as follows:

This is useful, because now I can differentiate Joe from things in my graph that are quite different, such as “household goods” nodes and “geo location” nodes. Rightly so, these things should receive very different treatment.
Now let’s say you also want to give Joe a party affiliation: Left-Wing, Right-Wing, or the moderate Middle-Wing. While you could do this with a property as well, you may decide that you want to easily find all people of a given party affiliation. Knowing that Joe is “Middle-Wing”, you might decide to break the parties into nodes, and then associate Joe with his party, as below:

One thing you’d now naturally want the graph to do, is to automatically index the “Person” nodes (and no other nodes), according to the unique identifier for “Person”. (Let’s oversimplify and say this is “name”). If you’re using Cypher, this is a challenge today. In fact it’s not possible at all, because Neo4j doesn’t inherently know anything about “Person” being different from geo locations. If you want to index “name”, you end up doing it for everything in the graph, which mixes concerns. Geo Location names aren’t the same as person names, any more than a city is like a person. As for the “Middle-Wing” node, it ends up becoming extremely dense, cluttering the graph with lots of connections whose sole purpose is to designate nodes as belonging to a group.
We’ve been looking at better ways to do this. The ideal solution would help to make one’s graph more understandable, as well as to make Cypher more powerful, by allowing it to home in on nodes (as well as to index them) according to what they are.
2.0 therefore introduces a means of grouping or categorizing nodes. Provisionally we are calling this construct a “Label”. The term “Label” speaks to its generic use, and to the fact that nodes can have multiple labels. One of the many uses of labels–and perhaps the most intuitive one at first–is to provide “hooks” in the graph that you can associate with your application’s type system. Because the facility isn’t itself explicitly hierarchical (it’s just literally a tag, of which you can have zero to many per node), they’re being called labels.
Labels
A graph is a graph because it has relationships in the data. In a Property Graph, a relationship always has a type, describing how two nodes are related. Labels expand on that idea, describing how entire sets of nodes are related. This is a grouping mechanism for nodes. How does it work? Very simple: in the example above, rather than adding a “Type” property and connecting Joe to a Party node, you would add two labels: one for “Person”, and one for “Middle-Wing”, just like so:

This opens up quite a few possibilities, and probably stirs up a lot of ideas in your head. Rather than color your thinking about how to use labels, let’s look at an example using different color sets.
Color me happy
Let’s say we have an arbitrary domain of loosely related stuff, within which we at least know that things can be red, green, or blue. We could just add a “color” property to each node, or relate them to a value node for each color. But because we want to always work within this group, we’ll use labels to identify members of the sets.
First, create something red:
CREATE a node with a Label
CREATE (thing:Red {uid: “TK-421”, make: 191860 })
RETURN thing;
To find the thing we just created, we can search within just the Red nodes, then return the labels:
Find the Labels on a node
MATCH (thing:Red)
WHERE thing.uid = “TK-421”
RETURN labels(thing);
Why labels, plural? Because nodes can have multiple labels. Let’s say that “TK-421” also belongs to the blue set. Add a blue label like this:
Add a Label to a node
MATCH (thing:Red)
WHERE thing.uid = “TK-421”
SET thing :Blue;
The benefits of intentional labeling
While some Danes may be nervous about labels, much good comes from their use. Applying a label to a set of nodes makes your intention obvious — “these nodes are accessed frequently and thought of as a group.” The database itself can gain benefit from having your intention be explicit, because it can now do things with this information.
For starters, Neo4j can create indexes that will improve the performance when looking for nodes within the set. (Note the new Cypher syntax for index creation!):
CREATE INDEXES to speed up finding Red and Blue nodes
CREATE INDEX ON :Red(uid);
CREATE INDEX ON :Blue(uid);
Create a second labeled node and a relationship
CREATE (other_thing:Blue {uid: “TURK-182”, make: 181663})
WITH other_thing
MATCH (thing:Red)
WHERE thing.uid = “TK-421”
CREATE (thing)-[:HONORS]->(other_thing)
RETURN thing, other_thing;
There is much more fun to be had. Details are, as always, in the Neo4j Manual. Again, this simple change can have profound impact. As we’re exploring the possibilities and tuning the language and APIs, we’d love for you to play around with labels. Let us know how you want to use them, by providing feedback on the Google Group. (That way other people can see your feedback and respond with their own opinions and observations.)
One more thing…
Just in CASE
Cypher has a new CASE expression for mapping inputs to result values: a cousin to similar constructs found in every common programming language.
-
In its simple form, CASE uses a direct comparison of a property for picking the result value from the first matching WHEN:
MATCH (r:Red) RETURN CASE r.uid
WHEN “TK-421” THEN “Why aren’t you at your post?”
WHEN “TURK-182” THEN “the work of one man”
ELSE “…”
END
-
In the general form, each WHEN uses an arbitrary predicate for picking the result:
MATCH (r:Red) RETURN CASE
WHEN r.color > 180000 THEN “redish”
WHEN r.color < 180000 THEN “purplish”
ELSE “simply red”
END
Summary
Enjoy this preview milestone! Use the Neo4j Google Group to tell the Neo4j team and other members of the Neo4j community what you think. There are a few other improvements baked into this release as well, including to the shell, that we’ll cover in upcoming blogs. And of course you’ll be seeing more in upcoming Milestones of Neo4j 2.0. Meanwhile, we have upgraded a preview of the online console for you to test the new features, it now features the Matrix graph enhanced with labels.
One final note: if you are planning to go into production soon, we strongly recommend developing against 1.9, which we expect to be going GA in the next couple weeks (look for an RC this week).
Update – 2.0.0-M02 introduces Remote Transactions
The latest 2.0 milestone introduces a new HTTP endpoint for managing multiple Cypher statements within a single transaction. Just create the transaction with the first batch of statements. You’ll receive a URL to which additional requests can be submitted, and for committing or rolling back the transaction. See the Neo4j manual for all the details.
Enjoy, from the Neo4j Team!
Want to learn more about graph databases? Click below to get your free copy of O’Reilly’s Graph Databases ebook and discover how to use graph technologies for your application today.
Share Article



Explore
Related Articles
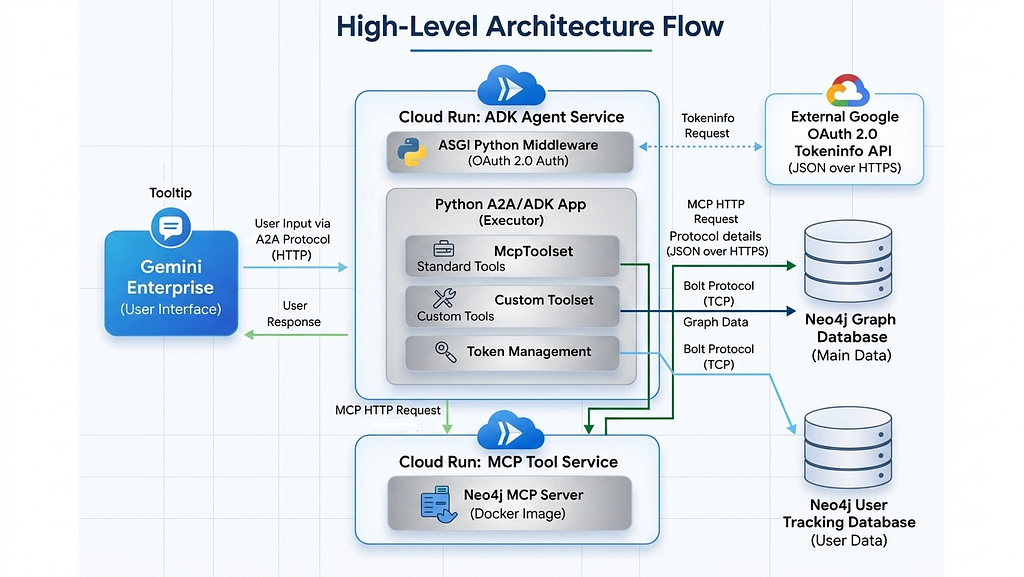



Architecting Graph-Based Agentic System: When a Regulator Asks “Why Was This Loan Approved?”