The all-new, officially supported Neo4j-JDBC driver 3.0

Head of Product Innovation & Developer Strategy, Neo4j
8 min read
The release of the all new Neo4j-JDBC driver 3.0 solves many of your Neo4j data integration questions.
Today we are happy to announce the availability of the new Neo4j-JDBC driver 3.0. We’re most grateful to our partner LARUS Business Automation from Italy for shouldering the majority of the development and support work.
Many of you have a wide variety of requirements to integrate Neo4j with other data sources, business intelligence (BI) suites, ETL and reporting tools, and specific system components.
While our new official drivers allow you to quickly write such integration tools and applications in any of the supported languages, more often than not, you just want to use a standard library, some configuration and the Cypher statements needed for your use case.
Meet the Neo4j-JDBC-Driver version 3.0 – our newest contributors’ effort – primarily developed by our Italian Partner Larus BA from beautiful Venice.
JDBC: The powerhorse of data integration
The JDBC standard is almost as old as Java itself and has evolved beyond database access for Java developers to a general integration component that allows tools of all kinds to interact with your trusted database. Originally built for relational databases (RDBMS), it has a lot of specifics around them (tables, schema, etc.) but in the essence covers the following aspects:
- Send parameterized textual query statements to a database
- Receive tabular results
- Provide result metadata and profiling
- Handle connection strings, with configuration options
- Support authentication
- Provide manual or automatic transaction management
All of these are necessary regardless if your database is relational or not. That’s why JDBC drivers were developed for a number of other NoSQL databases to ease integration (e.g., Cassandra, MongoDB, etc.).
History
Our first Neo4j-JDBC driver was started in December of 2011 by Rickard Öberg; that was more than four years ago. It built upon the HTTP endpoints and was just a spare-time activity but was already quite useful.
Now, with the shiny new Neo4j 3.0 release in April and its officially supported Bolt drivers, our trusted and active partner Larus BA from Italy jumped into action.
Due to requirements of their customers to integrate Neo4j with Pentaho, JasperReports and Talend, they saw the opportunity to work with us on creating this new JDBC driver from scratch using the latest APIs and technologies.
We started with the implementation for the Bolt protocol, then added an HTTP transport for older Neo4j installations. Going forward, we will also support an embedded transport that can work directly with store-files on disk.
During the development and presentation of an intermediate state at GraphConnect Europe, we were able to release several milestones and release candidates.
A lot of testing with many of the integration tools was done, with a lot of additional help from other trusted partners like Ralf Becher from TiQ solutions; Florent Biville, the author of LiquiGraph; and our experienced field engineers Stefan Armbruster and Benoit Simard.
And today we’re happy to announce the general availability of the 3.0 version of Neo4j-JDBC for your integration needs.
You now can:
- Download the JAR-library you need for your tools
- Use the driver with your tools or inside your graph-enabled applications
- Read the documentation
- Get the source code and contribute back
- Raise issues and provide feedback
In the following examples below, we want to demonstrate how you would integrate with Neo4j for some of the most popular tools, with most of the example queries based on our movies dataset (:play movies in the Neo4j Browser).
These examples hopefully give you enough information so that whatever tool you use, you should be able to configure and use the Neo4j-JDBC driver. If not, please reach out to us.
If you need official, professional support for the Neo4j-JDBC driver, just raise a support ticket.
Cheers, Michael for the Neo4j-JDBC contributors team.
Now, examples galore:
Squirrel SQL

Squirrel SQL is a widely used SQL workbench that supports many databases out of the box. Adding the JDBC driver was straightforward, as was running Cypher queries and getting tabular results back.
Pentaho
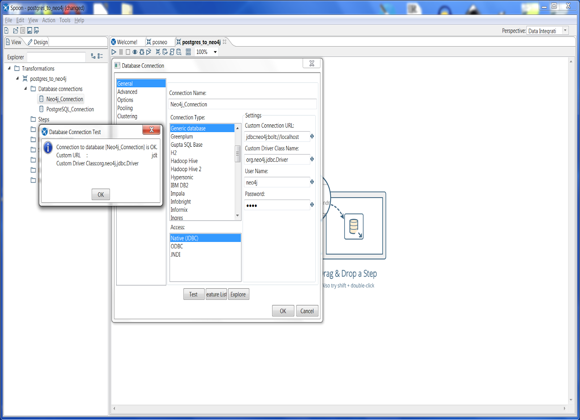
Step 1: Create Database Connections
Select a new database connections and insert Neo4j connection parameters and test it:
Connection Type: Generic database
Custom Connection URL: “jdbc:neo4j:bolt://localhost:7687”
Custom Driver Class Name: “org.neo4j.jdbc.Driver”
Login and password:
Step 2: Create Steps and Hops
From Design, select input and click on table input to insert the source table. From Scripting click on Execute SQL script.
Double click on table input. Select the source database connection and write query to extract data from source, then press the Preview button to check your query.
Double click on Hops, select as From step the table input and as to step the Execute SQL Script.
Double click on Execute SQL script. Click on Get Fields to retrieve the column from source database. Write the Cypher to create nodes and relationship:

Step 3: Run the Job
Click on run this transformation or job and wait until finished.
QlikView / Qlik Sense via TIQ JDBC Connector
(Thanks a lot to Ralf Becher, TIQ Solutions)
TIQ Solutions provides a commercial product to enable JDBC connectivity in QlikView and Qlik Sense. The configuration is simple.
In QlikView, you can connect to Neo4j directly. In Qlik Sense you need to copy the CUSTOM CONNECT script code.
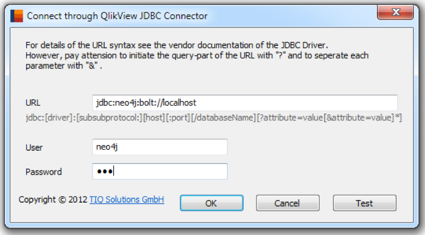
If your Neo4j connection is established, you now can execute Cypher queries in LOAD statements (but mention the SQL prefix). The results get loaded into memory tables as usual.


Tableau via jdbc2tde
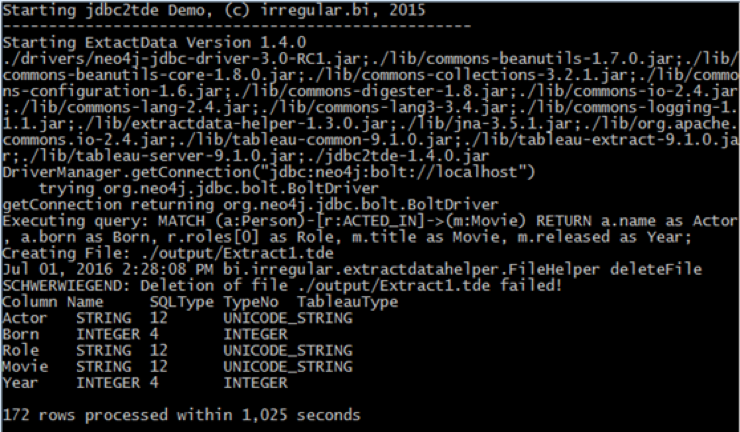
(Thanks a lot to Ralf Becher, TIQ Solutions)
Integration with Tableau is not that trivial as it only generates SQL. So you can either use the Tableau REST integration (which we will publish soon), or this tool from TIQ that uses JDBC queries to generate TDE files.
Those can then be loaded into Tableau and visualized and interacted with in the many ways you already know and love.

Talend
(Thanks a lot to Benoit Simard.)
With Talend, you can query or import your data into Neo4j using Talend JDBC Components.
On the Job, you just have to add a tJDBCConnection and add the usual fields: JDBC-URL, Driver-Jar, Driver, username and password.
On the Advanced Settings tab, you can also configure the auto-commit, if you want it.
Now, you can add some tJDBCInput to make some queries to your Neo4j databases like this:


JasperReports
(Thank you, Alberto d’Este.)
Step 1: Create New Data Adapters
Right click on Data Adapters and click on Create Data Adapter and select Database JDBC Connection.
Insert the values of JDBC driver: “org.neo4j.jdbc.Driver” and JDBC Url: “jdbc:neo4j:bolt://localhost” and add your username and password.
Then click on the Driver Classpath tab to add the Jar File and test the connection.
Step 2: Retrieve Columns from Database
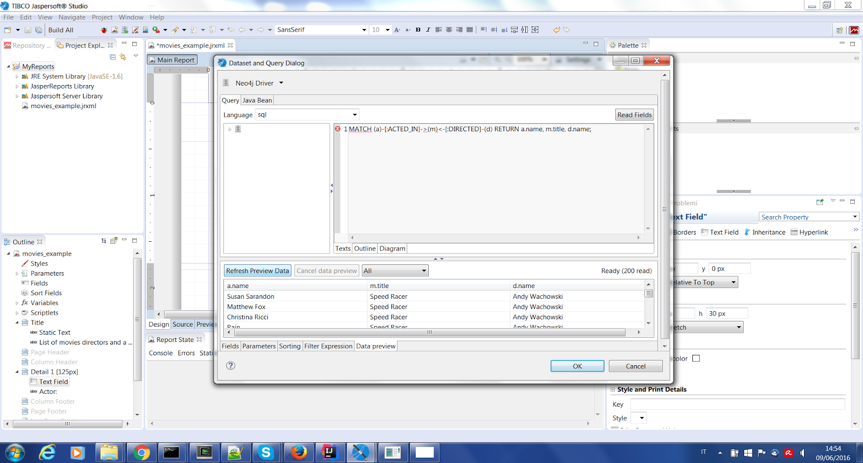
Create new JasperReport and select Data Set and Query editor Dialog.
Insert this Cypher statement, then click on Read Field.
MATCH (a)-[:ACTED_IN]->(m)<-[:DIRECTED]-(d) RETURN a.name, m.title, d.name;
You can check data retrieved on the Data Preview tab with Refresh Preview Data.
Step 3: Prepare Report and Create Document
BIRT

- Create a new Data source by right clicking “Data sources” -> New Data Source and choose the second option
- Create a new Connection profile store (click new on both windows)
- Choose “BIRT JDBC Data Source” and give it a name
- Load your Neo4j-JDBC jar by clicking “Manage Drivers” and select “Add”
- Fill the driver connection parameters
- Click “Next” and “Finish” and choose the newly created connection profile store
- Click “Next” and “Finish” and the Data Source should be created

- Create a new Dataset (right click Data Sets -> New Data Set) and choose Next
- Type the query you want to create your Dataset with and click Finish

A new window will appear showing the columns available with your query. You can also preview the results.

- Close this window and create a new Table element (Right click the document -> Insert -> Table)
- Choose 4 columns and click Finish
- Fill the table with the following data (drag and drop the data source columns in the right position)
- To export the report click Run -> View report -> As PDF
APOC
And to go totally meta, we can of course also use our APOC procedures library to query a Neo4j database via JDBC. Just place the neo4j-jdbc-3.0.jar into your $NEO4J_HOME/plugins directory and restart your server to pick it up.
Then you can run this Cypher statement:
CALL apoc.load.jdbc("jdbc:neo4j:bolt://localhost",
"MATCH (a:Actor)-[:ACTED_IN]->(m:Movie) RETURN a.name, m.title")

Want to explore more on how graph databases interact with relational databases and other RDBMS-based tools? Click below to download this ebook, The Definitive Guide to Graph Databases for the RDBMS Developer, and discover when and how to use graphs in conjunction with your relational database.
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher




A workbench for teams to query, explore, and visualize graph data
