Part 1: Using Neo4j in Business Process Modeling Scenarios

Principal Consulting Engineering, Neo4j
6 min read

When people think about Neo4j and problems it’s good at solving, there’s a pretty wide range of use cases that come to mind: recommendation engines, fraud ring detection, bills of materials, social network scenarios, multi-level marketing systems, asset management and analysis, role-based access control, graph algorithms and so on.
One of the use cases that don’t strike people as being “graphy” per se is business process management. So let’s talk about this and hopefully introduce yet another use case to the ever-growing list of things Neo4j is good at.
Let’s take a look at a very simple business process.
- Requestor submits a request
- Approver reviews it and either approves the request (at which point the process is done) or rejects it and the requestor has to modify the request based on approver’s input and re-submit it
Doesn’t get much simpler than that! So now let’s think about the data nomenclature involved here and what we can do with it:
- Request
- Request State
- Request Lifecycle Events – submitted, approved, rejected
- Metadata associated with Lifecycle Events – approved/rejected by/when/comments/etc.
- Actors involved in the process – request submitters and approvers
- Roles assigned to these Actors to indicate what they can do to requests in the certain stages of the flow
- Process itself! The sequence of events, allowed state transitions, etc.
What can we do with this data as in what kinds of questions can we answer based on it? Well, we can do things like:
- Find all Requests in the system
- Find all Requests in the certain state
- Find all Requests submitted by a certain Requestor
- Find out whether a specific Request can be approved/rejected/re-submitted
- See what comments were provided when a Request was rejected
- Check whether a specific state transition is allowed for a specific request
- Check whether state transition being applied to the request is allowed based on Actor’s role
There’s more we can do here but this is a good starting point.
Let’s take a stab at building a data model based on this nomenclature and see if/how we can answer these questions.
Data model will have three major parts to it:
- Business Process Model elements
- Request – related elements
- Role-Based Access Control elements
Let’s start with the Business Process Model. There are a couple of different ways to think about it. For example, we can think about it in terms of the Actions performed by Actors or we can think about it in terms of the States our Requests can travel through in the system.
Let’s take the State-based approach and see how things pan out.
create (ss:StateSubmitted) create (sa:StateApproved) create (sr:StateRejected) create (ss)-[:ALLOWED_TRANSITION]->(sa) create (ss)-[:ALLOWED_TRANSITION]->(sr) create (sr)-[:ALLOWED_TRANSITION]->(ss) return ss,sa,sr

Cool. Let’s add some sample requests now.
unwind range(1, 10) as r match (ss:StateSubmitted) create (sr:Request)-[:IN_STATE]->(ss) set sr.request_id = r; unwind range(11, 20) as r match (sa:StateApproved) create (ra:Request)-[:IN_STATE]->(sa) set ra.request_id = r; unwind range(21, 30) as r match (sr:StateRejected) create (rr:Request)-[:IN_STATE]->(sr) set rr.request_id = r;
Side note: In a “real” scenario these request IDs will either come from the API that will e.g. be used by the end-user facing UI or maybe these requests will be ingested from the external datasource so the ID will be created as a part of the ingestion/ETL flow or something along the lines of APOC UUIDs can also be used.
Now that we have some sample data in our simple business flow, let’s look at some questions our graph can provide answers to:
- Get all requests in a certain state. I’m an approver and I want to see all requests IDs in my bucket waiting for my action. Doesn’t get much easier than this:
match (req:Request)-[:IN_STATE]->(:StateSubmitted) return req.request_id
Let’s take a quick look at the profile output for that query:
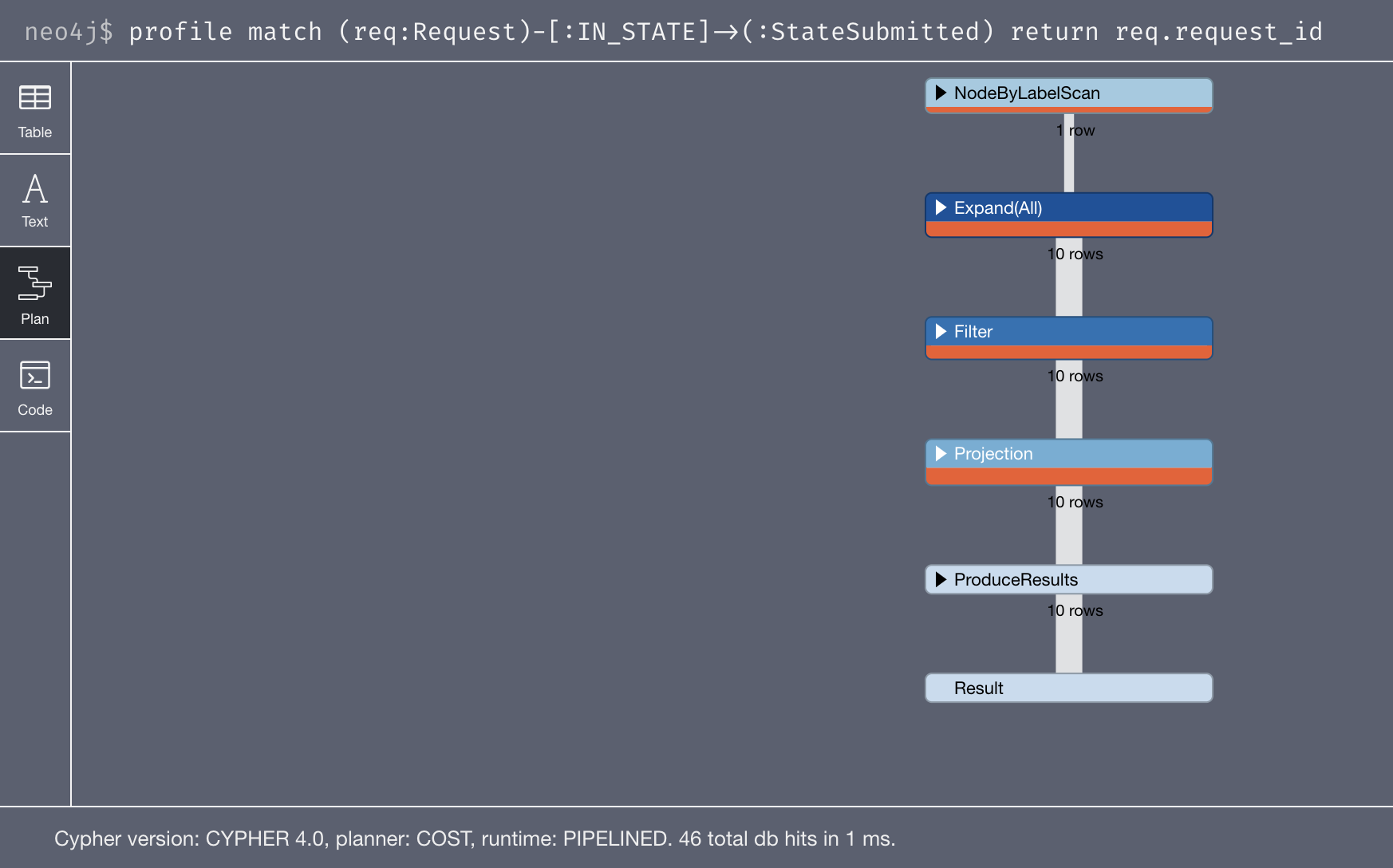
46 db hits. The planner is picking the StateSubmitted node and is expanding out of it. Then, as you can see, Neo4j has to filter out nodes on the other side of the :IN_STATE relationship to grab the Request nodes from the bucket of nodes it obtained in the expansion.
Since we know that there’s nothing else on the other side of the IN_STATE rel – just requests – if we get rid of the :Request label will the filter go away?
Let’s take a look:

That worked. No filter, 36 hits versus 46. Let’s stick to this query for now then:
match (req)-[:IN_STATE]->(:StateSubmitted) return req.request_id
- See how many requests are currently in the rejected state. I’m a submitter and want to adjust my workload based on that figure.
match ()-[:IN_STATE]->(:StateRejected) return count(*)
Let’s take a look at the profile:

1 db hit. Not bad. Neo4j internally stores the relationship count for every node – both total count (so something like match (:StateRejected)-[]->() return count(*) would also end up in 1 hit) and count per rel type. Think about how much more work RDBMS would have to do in comparison to get this count.
- See if a given request is eligible to be moved to a certain state. For example, as an API developer working with this data, I need to figure out if a certain Request can be moved to an Approved state.
Couple of different ways to go about this. Since we’ll be using request_id when selecting a Request to check whether it can be moved to some other state let’s first create an index on it:
create index on :Request(request_id)
To check the eligibility of a state transition for Request with request_id=8 (currently in Submitted state) to be moved to a Rejected State we can do something like this:
match (r:Request)-[:IN_STATE]->()-[:ALLOWED_TRANSITION]->(:StateRejected) where r.request_id = 8 return count(*) > 0 //true
… or this:
match (r:Request) where r.request_id = 8 return exists((r:Request)-[:IN_STATE]->()-[:ALLOWED_TRANSITION]->(:StateRejected)) //true
… or this:
match (r:Request) where r.request_id = 8 return size((r:Request)-[:IN_STATE]->()-[:ALLOWED_TRANSITION]->(:StateRejected)) > 0 //true
… or even this (which only uses 5 db hits to produce the result):
match shortestPath((r:Request)-[*]->(:StateRejected)) where r.request_id = 8 return count(*) > 0 //true
Let’s also look at one of the Rejected requests, let’s say request_id = 21 to see if it can be moved to the Submitted state:
match (r:Request)-[:IN_STATE]->()-[:ALLOWED_TRANSITION]->(:StateSubmitted) where r.request_id = 21 return count(*) > 0 //true
I’ll leave profiling output for these queries out of this post, would highly recommend looking at it however to gain some insight into how Neo4j goes about these operations. We’ll look more into using shortestPath() to check for connectivity between nodes in the next part of this series.
Let’s say our business is expanding and the process is getting more complex. For example, orders that go into the StateRejected bucket now have to have an additional Review step before they become eligible for resubmission again. With non-graph representation of the flow this would be a major ordeal. But we’re talking Neo4j here, so it’s no big deal. 🙂
All we need to do is remove ALLOWED_TRANSITION relationship between StateRejected and StateSubmitted nodes and introduce new StateReviewRejection state node between StateRejected and StateSubmitted nodes:
match (sr:StateRejected)-[r:ALLOWED_TRANSITION]->(ss:StateSubmitted) delete r create (sr)-[:ALLOWED_TRANSITION]->(:StateReviewRejection)-[:ALLOWED_TRANSITION]->(ss)
Let’s take a look at the updated process flow graph:
match (x)-[r:ALLOWED_TRANSITION]->(y) return x,r,y

Now let’s see if our request #21 is still eligible to become a Submitted request:
match (r:Request)-[:IN_STATE]->()-[:ALLOWED_TRANSITION]->(:StateSubmitted) where r.request_id = 21 return count(*) > 0 //false! now it has to go through the StateReviewRejection node
This wraps up part 1 in this series about business processing models in Neo4j. In the next installment, we’ll look at superimposing Users and Roles on our graph and using them to derive role-based access control (RBACs) decisions.
Share Article



Explore
Related Articles

Hybrid Search in Neo4j: Full-Text, Vectors, and Graph Topology with Cypher


A workbench for teams to query, explore, and visualize graph data


Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.
