Powering recommendations with a graph database: A rapid retail example

Chief Scientist, Neo4j
6 min read

It’s one thing to say that Neo4j streamlines real-time recommendations; it’s another to show you the code so you can see for yourself.
In this series, we discuss how real-time recommendations support a number of different use cases, from product recommendations to logistics. Last week, we explained how and why organizations are using a graph database for real-time recommendations.
In previous posts, we covered how recommendations connect buyer and product data as well as highlighting real-world success stories.
In this final post, we’ll walk through code for a quick retail example so you can see exactly how easy real-time recommendations are using Neo4j.
Rapid example: A retail recommendation engine using Neo4j
In a retail scenario (either online or brick-and-mortar), we could store the baskets that customers have purchased in a graph like the one below.
This graph shows how we use a simple linked list of shopping baskets connected by NEXT relationships to create a purchase history for the customer.
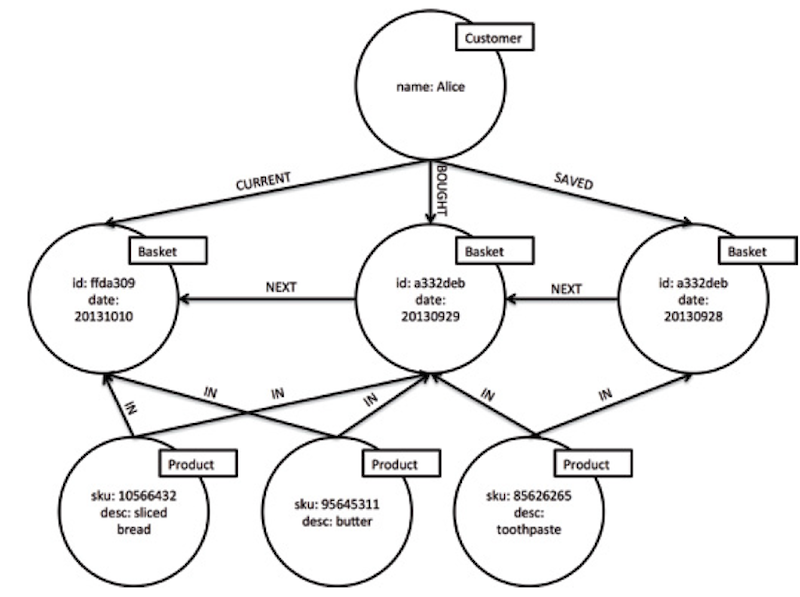
In the graph above, we see that the customer has visited three times, saved their first purchase for later (the SAVED relationship between customer and basket nodes).
Ultimately, the customer bought one basket (indicated by the BOUGHT relationship between customer and basket node) and is currently assembling a basket, shown by the CURRENT relationship that points to an active basket at the head of the linked list.
It’s important to understand this isn’t a schema or an entity-relationship (ER) diagram but represents actual data for a single customer. A real graph of many such customers would be huge (far too big for examples in a blog) but would exhibit the same kind of structure.
In graph form, it’s easy to figure out the customer’s behavior: They became a (potential) new customer but failed to commit to buying toothpaste and came back one day later and bought toothpaste, bread and butter. Finally, the customer settled on buying bread and butter in their next purchase – which is a repeated pattern in their purchase history we could ultimately use to serve them better.
Now that we have a graph of customers, and the past products they’ve bought, we think about recommendations to influence their future buying behavior.
By far, the simplest recommendation is to show popular products across the store. This is trivial in Cypher as we see in the following query:

The Cypher query above showcases a lot about Cypher.
First, the MATCH clause shows how ASCII-art is used to declare the graph structure (or pattern) that we’re looking for. In this case, it can be read as “customers who bought a basket that had a product in it” except since baskets aren’t particularly important for this query we’ve elided them using the anonymous node ().
Then we RETURN the data that matched the pattern and operate on it with some (familiar looking) aggregate functions. That is, we return the node representing the product(s) and the count of how many product nodes matched, then order by the number of nodes that matched in a descending fashion. We’ve also limited the returns to the top five, which gives us the most popular products in the purchasing data.
However, this query isn’t really contextualized by the customer but by all customers and so isn’t optimized for any given individual (though it might be very useful for supply chain management). We do better without much additional work by recommending historically popular purchases that the customer has made themselves, as in the following query:

The only change in this query, compared to the previous one, is the inclusion of a constraint on the customer node that it must contain a key name and a value Alice. This is actually a far better query from the customer’s point of view since it’s egocentric (as good recommendations should be!).
Of course, in an age of social selling it’d be even better to show the customer popular products in their social network rather than just their own purchases since this strongly influences buying behavior.
As you’d expect, adding a social dimension to a Neo4j graph database is easy, and querying for friends/friends-of-friends/neighbors/colleagues or other demographics is straightforward as in this query:

To retrieve the purchased products of both direct friends and friends-of-friends, we use the Cypher WITH clause to divide the query into two logical parts, piping results from the first part into the second. In the first part of this query, we see the family syntax where we find the current customer (Alice) and traverse the graph matching for either Alice’s direct friends or their friends (her friends-of-friends).
This is a straightforward query since Neo4j supports a flexible path-length notation, like so: -[:FRIEND*1..2]-> which means one or two FRIEND relationships deep. In this case, we get all friends (depth one) and friend-of-friends (at depth two), but the notation can be parameterized for any maximum and minimum depth.
In matching, we must take care not to include Alice herself in the results (because your friend’s friend is you!). It is the WHERE clause, which ensures there is only a match when the customer and candidate friend are not the same node.
We don’t want to get duplicate friends-of-friends that are also direct friends (which often happens in groups of friends). Using the DISTINCT keyword ensures that we don’t get duplicate results from equivalent pattern matches.
Once we have the friends and friends-of-friends of the customer, the WITH clause pipes the results from the first part of the query into the second. In the second half of the query, we’re back in familiar territory, matching against customers (the friends and friends-of-friends) who bought products and ranking them by sales (the number of bought baskets each product appeared in).
Conclusion
Graph technology enables you to incorporate customer feedback, adjust for seasonal trends or suggest birthday gift ideas based on data on the customer’s Facebook friends. And all in real time, without clever coding, and with no fear of the relational JOIN bomb.
See how leading companies are using Neo4j drive personalization at scale with this white paper, Powering Recommendations with a Graph Database. Click below to get your free copy.
Catch up with the rest of the real-time recommendation blog series:
Share Article



Explore
Related Articles
Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report

Unlocking high-conversion recommendations with graph analytics in Snowflake

Why LeBron James shouldn’t drive your recommendations: The intuition behind the Jaccard coefficient

Top 10 graph database use cases (with real-world case studies)

Building a recommendation engine using Neo4j hands-on—Part 2
