
The Present and Future of Artificial Intelligence and Machine Learning
20 min read

Editor’s Note: This is a transcription of a presentation given by Hilary Mason at GraphConnect New York in October 2018.
Presentation Summary
The metaphors we use to describe the world directly correspond to the way in which we build technology, particularly in the areas of artificial intelligence and machine learning. Take the example of the technology developed around the U.S. Census, which was based on the way train conductors counted passengers. This simple technology ultimately became the basis for modern computing.
One of the challenges facing AI today is the general lack of understanding surrounding new technological capabilities, and the fears that show up in daily news headlines. As experts in the field, it’s our job to help people understand what AI and machine learning really is, where it came from, and the successful ways it’s already being used in our daily lives — for example, with Google Maps and assigning text to images. Once this technology has become so integrated that it no longer causes alarm, we’ll know that we have succeeded in this effort.
One of the biggest challenges related to AI and Machine Learning today is that we’re waiting for the way in which we think about technology to catch up to our capabilities. But we’ve come up with a methodology to predict the future, which includes doing research to uncover the currently available research materials, a change in economics (i.e. what types of technology is becoming “cheaper”), if the capabilities are becoming commoditized, and if new data is becoming available.
The presentation concludes with an overview of the current machine learning technologies that exist today, including natural language generation, probabilistic methods for realtime streams, image analysis, and summarization. But having these technologies at our fingertips isn’t enough. Regardless of what we are able to develop, we as a community must think about the ethics surrounding these new tools, and respond accordingly.
Full Presentation: The Present and Future of Artificial Intelligence and Machine Learning
What we’re going to be talking about today is the present and future technology built upon machine learning and artificial intelligence:
But this is also a talk about metaphors. If you take one thing away from this presentation, I want you to think about how the metaphors we use to think about problem statements, and the world we’re creating, drive the architectural decisions that we make. They drive the design of our algorithms, and they drive even our creative solutions to the problems we want to solve. That’s why throughout this talk I’ve chosen to highlight the metaphors that have led to certain design decisions – and to give some context around why things are the way they are.
Metaphors control the way we think about the world, and are powerful tools for creating new kinds of solutions and opening up new opportunities.
Metaphors: The Census and the Birth of Modern Computing
The first metaphor I want to share with you is related to the Census. Below is a photo of some people on a train in the 1880s:

Why am I showing you this? Because it’s the metaphor that led to the creation of the system below:

In the 1880s, we conducted the U.S. census by sending people around the country by train, taking information by hand on paper. We weren’t able to do this using any available technology at the time, and it wasn’t very effective or efficient. Herman Hollerith of New York was inspired by the way train conductors would punch holes in tickets to create an automated counting machine that he patented. That original punch card design led to the later design that you saw in the 1930’s, which led directly to the architectural metaphors we all use today in our computing environments. So for obvious reasons, this is a really important metaphor.
He started a company that was originally called the Tabulating Machine Company, later renamed to IBM. My favorite joke is from Vinton Cerf, who once said that if computer scientists named Kentucky Fried Chicken, we would have called it Hot Dead Bird.
The AI Headlines of Today
Let’s go through a few of my favorite recent AI headlines. This article is about someone who created a bot that raps like Kanye West. Every so often I go to Google news and search for “artificial intelligence” to see what comes up. Half of the articles are filled with a “doom and gloom” mentality, and the other half show more optimism; messaging that spans from “AI is curing cancer” to “AI is going to destroy society.”
The article “Is Artificial Intelligence a danger? More than half of UK FEARS robots will take over” was just published in the Express yesterday, so there’s still a lot of work for us to do. Unfortunately, the conversation hasn’t really progressed.
Then there’s the reporter who set out to become BFFs with a chatbot – which forgot his name. In the transcript, he asks “What’s my name?” and the chatbot responds “hello, undefined.” Of course nerds know why that is, but to normal people that might seem a bit weird. This a great example that shows how the vocabulary we use changes the way we think about the technology.
We’ve moved away from talking about AI and machine learning as computer programs to talking about them like these magical boxes or creatures that are going to emerge from nowhere, take our jobs, rap like Kanye West, and then forget our names.
But I’d like to share a way to think about this practically. I am relentlessly practical in the sense that I get excited about different possibilities, but then I actually have to go home and build something that works.
That means we need to have robust metaphors for talking about what we want to do before we can decide on the solution. And I often find that in machine learning, posing the question is the real challenge. The answers are either trivial or impossible.
Building The Foundation for AI
Let’s think about a concept that has become commonplace vocabulary: big data. 10 years ago, we would be having a big data conversation focused around the ability to get at all of our data in one place and count things in that data. It sounds simple, but was absolutely transformative at the time.
But it wasn’t transformative because we hadn’t done it already; it was transformative because something that was previously inaccessible and incredibly expensive became something cheap and accessible. That opened up this entire new area of work with new use cases, new applications, and creativity around the technology.
That was 10 years ago in big data. We see the same thing happening today in graph databases. Once you can count things, you can count things for business purposes.
You can do analytics, you can spread out the kinds of things you want to count, you can put that technology in more people’s hands. You can count things for a reason. And when you can count things cleverly, you can use data science to model things, make predictions, and build representations of your data using different metaphors to explore the world. And when you can count things cleverly with feedback loops in systems that appear useful and magical, that’s when you have machine learning and AI.
But, the technology is just moving up the stack:

You can’t perform machine learning or create AI without data science, analytics, big data, or a fundamental data representation.
When you think about those metaphors, I would not dismiss AI out of hand. Think of it instead as a new label for this technology that is the result of moving up the capability stack; where things that were previously expensive or out of reach have become possible, in reach, and useful to a wider variety of people. This is why we see such a flowering of interest in machine learning and AI today. And it is up to us as technologists to make sure that people understand what is real, and what is not.
What Does Successful AI Look Like?
Google Maps
So, what does AI look like when we do it well? One of my favorite machine learning applications of all time is Google maps with the traffic view turned on:

What’s so special about this technology is that it’s really, really boring.
The app tells you the best route to take to your destination, and you don’t have to think about it at all. You don’t need to be even a little bit aware of the technology that powers this tool. That every phone running Android is sending data back to Google, that they’re doing incredible predictions using historical and real-time data. That a cellular tower network is coordinating to stream that information down to your device, and you don’t even need to think about the visualization because everyone who grows up in our society is trained to recognize that green means go and red means stop. You just look at this and understand what it means.
It’s a successful machine learning product because we don’t think of it as a machine learning product at all. We just use it to get where we’re going, and then turn it off. And that’s what success looks like, when we stop getting excited about AI and start instead getting excited about what AI applications can do for us. But this is a hard place to get.
Matching Text with Images
I’m going to share a quick personal example of being an edge case in this data-enabled universe. In 2007, there was a startup called Cuil which was going to try to defeat Google by pairing images with webpage results. Google didn’t do this at the time, so it was a big deal.
Below is what came up when you searched my name:

There is an actress who shares the same odd spelling of my name, and who played the role of “ugly hag” in a movie:
In 2006, Microsoft Bing — which had some of the best minds in the data science world — rolled out their celebrity visualizer inside of Bing search. Again, I am not a celebrity; I’m a nerd who shares my name with a celebrity. But this is what came up when you pulled up the other Hilary’s bio:
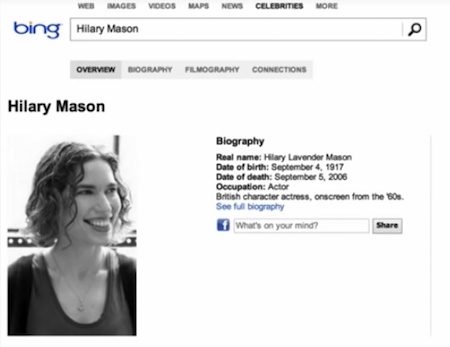
Again, even some of the best minds in the world struggle to bring in the right data at the right time. And that’s why it’s so exciting, and the reason we need new metaphors, and new ways of representing and thinking about our data. We’re waiting for the way in which we think about technology to catch up to our capabilities.
This is why we should be having this conversation right now, and thinking about the interplay between metaphor, how we think about the world, and the architectures we design to build. Many of the biggest opportunities to do this well are right here.
One of the advantages I have is getting to work with a wide variety of people who are working on interesting machine learning and AI applications.
Everybody thinks that all of the cool stuff only happens in startups. But established businesses have collected a large amount of data as a side effect of operating those businesses for a longer period of time. They have creative people who are ready to embrace these new metaphors for development, and have the biggest opportunities. These people may be in Fortune 100’s, or they may be researchers tackling really interesting challenges. You have those big opportunities.
Machine Learning: How to See the Future
If you do work in machine learning, you know that predicting is hard, and predicting the future is even harder. I’m going to go over the process my applied machine learning research group goes through to try and see the future, and hopefully you can take our methodology back to your own work.
At Fast Forward Labs, which is now part of Cloudera, we do quarterly reports on emerging machine learning applications designed for real business use cases. Our team reads 30 papers filled with data that people record in the real world, and writes code to try to figure out what will work at scale.
Our goal is to be our customer’s nerd best friend who accelerates the pace at which they can take advantage of these technologies. To do that, we have to see what’s coming, and aim six months to two years ahead of what is currently in production.
Here’s our secret: Drink coffee, and have ideas – even bad ones. What I want to point out here is, you need to have a lot of ideas and that means deliberately trying to have bad ideas.
When I visit a company and they show me the machine learning projects they’re working on and they are all good ideas, I get very worried. If you only pursue the things that are obviously good ideas, you are missing out on a lot of the opportunity for things that might be a little bit risky, but could have a huge potential payoff.
So, have a lot of ideas and then validate, so go as broad and wide as you can and then once you have that collection, validate against robust criteria that can be quantitative.
These are the criteria we use:
Research Activity
Look for active research activity that’s relevant to a particular machine learning application. Are people publishing relevant papers? Are there papers in one academic domain that could be moved into another? One of the advantages of having a team like ours is that we have people from all different backgrounds: computer scientists, physicists, neuroscientists, electrical engineers. There are people who have solved a problem in one field, but don’t bother to tell anyone else. But when you get that kind of diverse thinking in one room, you have a lot of creativity and a lot of potential knowledge that can be moved from one realm to another.
A Change in Economics
Is there a change in the economics the systems require to architect a solution? Meaning, what is the cost of a GPU or CPU computer? I could draw this same graph for pretty much any of the systems we rely on, but this particular example that I find so compelling is the micro SD card:
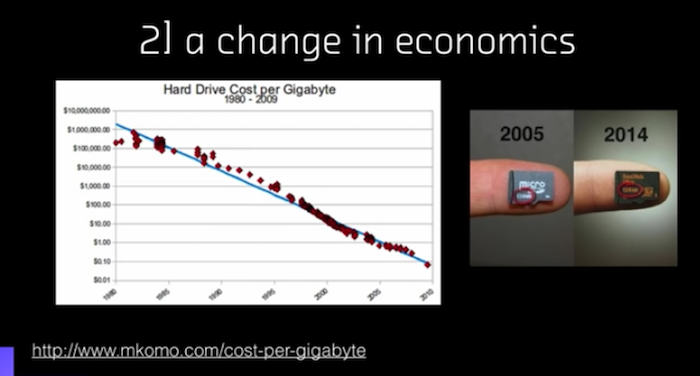
Its capacity has increased orders of magnitude over a decade. Same price, same card, same form factor. We live in a world in which even if something is out of reach for you today, don’t throw it away because a year from now, it might be cheap. There might be some service you can just use to do it.
Capabilities Becoming Commoditized
We look for capabilities becoming commoditized, particularly in open source libraries. Hadoop itself is the core example of something that was very hard and expensive to do, even though people knew how to do it.
Once the Open Source project became reasonably widely adopted, you could take for granted that you could have that infrastructure in one place, count things, and get an answer fairly easily. Word2vec is another great example in the machine learning space. Word embeddings are very mathematically complex. Writing your own takes a significant investment of time and energy. But now you can download them and get up and running in a couple of hours.
Commoditization is a moving wave and it’s hugely powerful for our ability to execute on machine learning.
New Data Becomes Available
The last thing to look for is new data becoming available, whether that’s internally or externally. It may be data you’re generating because you launched a new product or feature, or it may be data you can collect from the world, or purchase. But wherever the data comes from, you need data to be available in order to pursue machine learning.

I pulled up this Wikipedia page on data science for two reasons.
The first is that Wikipedia is the dirty secret of every MLP application run by startups because the information is widely available and is licensed for commercial purposes.
The second reason is that for a long time, Wikipedia data science page cited the creation of the page as a major milestone in the evolution of data science as a profession. That’s the most Wikipedia thing I’ve ever seen.
Once you have your criteria, you go through your set of ideas and set aside things that might be possible from those that probably aren’t. You can progressively explore these risky capabilities.
In our group, we do a three hour lit review that consists of googling and reading abstracts from published papers to determine whether or not we should explore the idea any further. Next, we pick a subset of papers to read and come to some individual point of view about whether or not it’s worth the investment. We then take the subset of papers that passed through the earlier filters to go write code.
By bounding the investment of time you’re going to spend, this progressive exploration allows you to consider risky ideas that might otherwise not be worth your time. It also helps you repeatedly get to the same answer regardless of how many people are working on it.
Now to show you that predicting the future actually is hard, below are some postcards from France from around 1900 predicting life in the year 2000:

In the center postcard, there are children in a classroom wearing cullenders on their head getting the knowledge pumped directly into their brains. On the right side, there are firefighters with wings flying to put out fires. And even though we have technologies that address some of these things, they were implemented in ways that the people of 1900 couldn’t even contemplate.
Making exact predictions is challenging, so if your predictions are in the right direction you’re doing a pretty good job.
Technology Deep Dive
Now let’s dive into a discussion of some of the actual machine learning technologies that exist today, and some that will emerge in the near future. All of these tools came out of the process described above. Sow you know how to see the future and I’ll tell you what we see there.
Natural Language Generation
One of our reports is on natural language generation, something that you might have seen in the news, like this one from the Associated Press: AP’s journalists are writing their own stories now. There actually is an Automation Editor who oversees these algorithms. He oversees the software system that generates their stories, but no people.
We built a prototype that generates real estate advertisements. You input the characteristics of an apartment that you either want to buy or sell, and the tool writes the ad for you. But it gets really funky when you tell it things that don’t exist.
For example, if you want to sell a one bedroom, sixteen bathroom apartment on the Upper East side with a doorman, it will return something like a “sun-filled home has a lot of bathrooms.” My point is not that robots are writing articles, but rather to point out how we as humans interact with data. You can imagine all of this language in columns of data or graphs of data:
You can imagine a graph in the middle, and we expect every professional to be able to read a graph and Excel. But most people intuitively understand a language-based interpretation of that data, which is what this technology gets us: We can go from structured data to a language-based representation of that data in the form of a couple of sentences that describe what the data says. The real power is in bringing the understanding of structured data to a much wider audience through the power of language.
We’ve seen this implemented for two customers.
The first is a bank that uses this technology to automatically generate compliance filings, which has a really interesting story behind it. The second is a celebrity fashion magazine that uses a structured JSON feed of celebrity clothing to create a mobile app that would create text saying, for example, that Kim Kardashian is wearing this specific sweater, which you could buy.
Both tools have the same math but take very different forms. Again, a metaphor is here.
Probabilistic Methods for Realtime Streams
We think there are new architectures that are necessary to understand the world in real time.
When you think about this from an engineering point of view, you go from a metaphor where, for example, we keep our data in a batch environment and generate an average. It’s pretty straightforward, but depending on how large or how distributed your data set is, it might actually take quite a long time to calculate.
But what if we live in a world where our computing device is the size of my thumbnail with a highly limited memory and an incoming data stream of thousands of events per second? How would we calculate an average in that environment?
The answer here is using an algorithm called reservoir sampling. You have a constrained amount of compute and memory required, you have a certain amount of buckets that you’re always probabilistically updating, and you can take the average at any time, which is just N (because you’re taking the average of N buckets). Now instead of a correct answer you have a correct answer with error bars.
This is a metaphor for thinking about the design of systems that I like to imagine is the way we will finally build that Star Trek tricorder that we have yet to do. Instead, here is a demonstration of running it across the entire corpus of comments on Reddit with one small EC2 instance:

You can see similarities in language used between “shower thoughts” and “why I’m single.” People talk about the same things in those little corners of the internet.
This is the graph metaphor that allowed us to build a system that wouldn’t have been possible if we were constrained by the older metaphors of architecture design. There a huge amount of power in these probabilistic techniques that we are broadly as a community just starting to exploit.
Deep Learning: Image Analysis
Of course, I can’t give a talk about AI and machine learning without talking about deep learning. Deep learning is really an evolution of neural networks with neurons that look something like this:
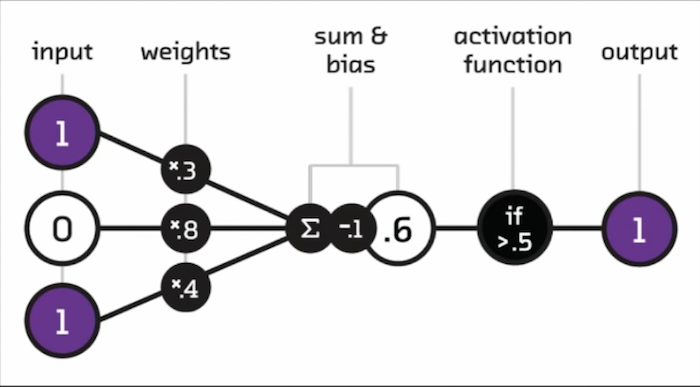
Many of them together, and then in layers. “Deep” refers to how many layers there are, and isn’t really a technical term. I say that because I’ve even seen plenty of deep learning papers with only one layer of deep networks.
This neural network was inspired by the way we thought the brain worked in the 1940’s and 50’s. In fact, the first neural networks were developed at Cornell Aeronautical Laboratory in the form of hardware that could recognize a light turning on and off.
Today, they’ve enabled analysis of rich media that was previously entirely out of reach. Here’s a demo in which you can use an Instagram filter that will tell you ‘this person likes to take pictures of Ireland’.
I’m going to run through an example of how we got this technology wrong, because we as machine learning developers and scientists have a responsibility to show the boundaries of these technologies. And because I love cheeseburgers, I’m going to use the example of Bleecker Burger, a cheeseburger restaurant in New York:

It classified everything pretty well. In the top left, it tells us these are burgers. The ones at the bottom says that it’s food, but it might be a meatloaf, it could be a hot dog – we’re not entirely sure. There’s a flagpole in there, which is the only thing pulled that isn’t burgers, and then there’s crab.
So, what is crab? We can tell based on the below that this neural network has learned that anything that looks like french fries near water or a dock is crab:

Again, I’m sharing this with you to say that it’s our responsibility to not only understand the power of these techniques and these metaphors, but sometimes they go a little weird. As individuals, we are responsible for keeping them from going weird.
Summarization
If you apply these same kinds of deep learning to text using tools like word embeddings and sentence embeddings, you can start to build things like a system that will take an article and extract the sentences that intuitively contain the same information:

It’s all done automatically, and works for any article in the English language because of the way the models were trained. However, you could easily develop this for other languages as well.
This kind of tool gives us a new way to not just look at single pieces of text, but to look at corpuses of content with 50,000 documents on the same topic and extract the different viewpoints. You do this by clustering, finding the viewpoints in that corpus, and summarizing each one. This is something that you can do pretty easily now.
The last one ties to algorithmic interpretability. When you build all these black box models, how do you look inside? And why do you look inside?
One is that the government makes you. Compliance and regulatory adherence often legally requires you to be able to explain why a system did what it did. For those of you who who wrote this off because you don’t work in finance or healthcare, let’s get to the second reason. Sometimes these systems do really strange things, and you want to be able to know why. It simply allows you to build better systems overall.
To give you a bit of intuition, this is a set of algorithms that you put on top of your black box algorithms that permeate the inputs, look at how the outputs and the classifications change, and then infer which features were significant in the black box model.
In this case, this gives us the ability to go into a telecom churn analysis and figure out not just the probability that a customer with churn, but why and what action you can take:

You can play with actions and see the probabilities changing to change that classification and, therefore, that customer’s fate:

That’s why this is a really useful set of techniques outside of compliance and regulation use cases.
Conclusion
I’m going to end with my favorite examples of graphs in machine learning. One is from an article by Gilad Lotan, the chief data scientist at Buzzfeed, which he created after the inauguration of our President.
He did a huge analysis of emoji use on social media, and created the below representation which has everyone who was happy about the inauguration on the right, and everyone else on the left:

The way things cluster in this graph visualization tells us the human story. Again, it’s the right metaphor for analysis of that particular, very emotional moment in time for the American people.
Another project we did was to help one of the top accounting firms in the world figure out automation around tax codes. We wanted to understand when the tax code changes in the United States – which it does in a very complex way – at the local, state through new laws and changes in the judicial interpretation of existing code.
We were able to build the below model that helped them automatically build a machine learning tool to support their CPAs in their workflows so they didn’t miss anything:

By using graphs and machine learning, there was a fundamentally new capability added to the firm.
We were also able to create a similar analysis of how we trade commodities. News coming in affects things that you have in your investment portfolio, and you need to be able to see those connections.
This is an example of using the power of that metaphor to build tools that enhance the capabilities of human professionals in doing their job even better by getting them the right information at exactly the right moment.
I’ll end with a few points of caution for anyone who’s going to run out and do this. It is hard. We don’t entirely know what we’re doing yet. Best practices are emerging. And if you are building something with technology, I encourage you to think very deeply about the impact of what you build on the world we live in.
I co-authored the book “Ethics and Data Science” with DJ and Mike Loukides about the practice of ethics and data science. This book poses questions, but won’t provide you with all the answers.
I think this is the big question that data science practitioners are thinking of our moment. Think about this as you build these technologies.
My favorite metaphor is that technology and machine learning in particular is actually giving us superpowers because it is giving us the technical ability to do things that are out of reach of our cognition as unadorned, unaided human beings. And it is a very exciting moment to be working in this space.
Share Article



Explore
Related Articles


How to Improve Multi-Hop Reasoning With Knowledge Graphs and LLMs

What Are the Different Types of Graph Algorithms & When to Use Them?


