Introducing the newest RDBMS-to-Neo4j ETL tool

Software Engineer, Neo4j Team
11 min read

Introduction
The Neo4j team is beginning to work on better ways of integrating Neo4j with other data management systems and data sources. A common case is the need to import data from existing databases, either to seed a new Neo4j database, or to maintain a graph data model view in sync with an existing data store.
There are many approaches to data integration: one common approach is the use of Extract, Transform, Load (ETL) tools that can be used to copy data from store to store.
As a first step we are building components that can be assembled into an ETL pipeline.
neo4j-etl-components is an open source project from Neo4j to bridge the gap between the relational database world and the graph database world. You can now easily import your MySQL database into your own Neo4j instance with ETL components that can be activated by neo4j-etl.
About neo4j-etl
The Neo4j ETL tool extracts the metadata from a MySQL schema and then applies some default mapping rules for a CSV export to be consumed by the neo4j-import tool for the actual bulk import. All of this is via one single command with no intervention from the user. Like so:
./bin/neo4j-etl mysql export --user--password --database northwind --destination $NEO4J_HOME/data/databases/graph.db/ --import-tool $NEO4J_HOME/bin --csv-directory /tmp
It is available now in our contrib repository for you to test it out and most importantly contribute your feedback, expertise and ideas on extending the tooling and making it useable for other databases. More details can be found in the ETL tool’s documentation.
Here is the story of how we developed the mapping rules based on practical experience:
The story of how we got here
People understand and communicate with the world with the help of visual cues. I use the London Tube map and Google Maps on a day-to-day basis. When someone new joins my team, we use an architecture diagram to help them understand what different components of the application does. Developers and DBAs use Entity-Relationship (ER) diagrams to design and analyse data and their relationships and find a course of optimisations that yield better performing systems.
We enforce structure to make sense of the world around us. However, we are often restricted by imposing premature structure in the database world. I’d like to share what I learnt from porting data and relationships from a relational database (MySQL) into Neo4j which will hopefully convince you to trail freely on the schema-optional side of the database world.
The metamorphosis of the mapping rules
At first we thought the rules to interpret a schema are fairly easy, because that is what schemas do: make it easy to interpret data and its interactions with each other.
Remember:

Iteration 0: Dealing with structure
We started with:
- All information is stored in relations or tables => In Neo4j, we store information in nodes with properties (roughly the equivalent of rows of data).
- Relationships between stored items of information (rows in tables) indicated by JOINs => In Neo4j, we store relationships between nodes explicitly as relationships.
Iteration 1: Don’t Forget the Keys
The steps:
- Identify first-class objects: tables and JOINs
- Export to Neo4j
Querying for tables: Easy. Check. 🙂
Querying for JOINs: This is where the problem lies. JOINs are not first-class citizens in relational databases. Keys joining the tables are.
So we updated the rules accordingly:
- All information is stored in tables => In Neo4j, store information in nodes with properties.
- Relationships between stored items of information (rows in tables) are indicated by keys joining the tables => In Neo4j, store relationships between nodes explicitly as relationships.
Iteration 2: What constitutes a key?
The steps:
- Identify first-class objects: tables and keys
- Export to Neo4j
Querying for tables: Already done
Querying for keys: Keys are expressed as constraints in MySQL. The usual ones are PrimaryKey and ForeignKey.
Primary key: Identifies unique records in a table
It is possible in MySQL and in many other databases to define PrimaryKey not as one single column but a group of columns, a.k.a. a composite or compound key. For example, an author can be uniquely identified using his or her first name and last name, in which case we combine these two columns to create a unique identifier whilst importing the data.
Foreign key: Identifies relationships between tables
Sweet, just what I was looking for. Every key has a source as the start table and target as the end table. In other words the start node and end node of a relationship in Neo4j.
Here is an example: How are Territories linked to Regions? All territories are associated with a specific region. Let’s compare the relational and graph view of the world:
The Relational Database View in MySQL:
Territories have a ForeignKey RegionId that refers to the PrimaryKey RegionId in the Region table.

The Graph Database View in Neo4j:
If we import this into the graph, a Territory start node is linked with the Region end node like this: (Territory)-[:REGION]->(Region)
You can see that we don’t need the keys (Territories.RegionId, Region.RegionId)anymore to provide the relationship between them.

What the Data Looks Like in MySQL:
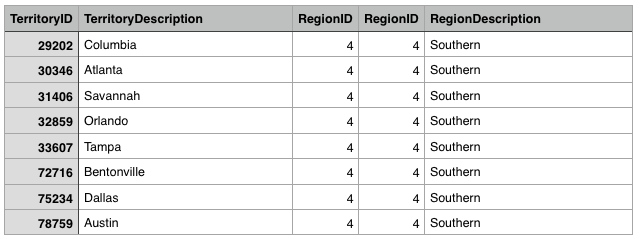
What the Data Looks Like in Neo4j:

Composite keys: special cases
As you probably know from experience, a ForeignKey constraint can be placed on a composite PrimaryKey, which poses an additional challenge.
CompositeKeys are often composed with domain-relevant natural keys. The Northwind database uses artificial (surrogate or synthetic) numeric keys instead. As an example, Suppliers in Northwind could be identified by TaxNumber and Country instead of the artificial SupplierId. These two columns would be part of a CompositeKey, which you would have to use as a ForeignKey to Supplier.
The neo4j-etl tool handles composite keys automatically based on the meta information from the relational database. See the documentation for more details.
An update to the rules is due:
- All information is stored in tables => In Neo4j, store information in nodes with properties.
- Relationships between stored items of information (rows in tables) are indicated by constraints that link tables together => In Neo4j, store relationships between nodes explicitly as relationships.
Iteration 3: JoinTables – are they JOINs or tables?
Once we’ve identified clear first-class objects like tables and primary and foreign key constraints the next obvious step is to:
- Export to Neo4j
To export, we go through the list of tables to identify what are the different kind of constraints placed on them. Some tables have a PrimaryKey UNIQUE constraint placed on them, those mostly contain entities from the domain. These are the easy ones to convert as nodes.
As we went about doing that, we find out there are exceptions: JoinTables.
In MySQL…
The structure of some tables represent a JOIN table, wherein a table is joined with another table through an interim table. This is usually done to represent a many-to-many relationship or sometimes done as a normalisation exercise.
For example, OrderDetails is a JOIN table to signify a join between Orders and Products.

…Translated to Neo4j:
If we were to follow the rules that we had previously set, we would end up with three nodes: Orders, OrderDetails and Products.
But in Neo4j, relationships are first-class entities so we can skip the interim node and can instead import it as: (Order)-[:ORDER_DETAIL]->(Product).
Unlike MySQL, you do not need to create a table to store details about the JOIN such as UnitPrice, Quantity or Discount. Instead, you can store this information on the relationship as a property.

Note: OrderDetails has OrderId and ProductId as a CompositePrimaryKey. The JoinTable rule should still apply in this scenario.
Well you guessed it now, another update to the rules:
- All information is stored in tables => In Neo4j, store information in nodes with properties.
- Relationships between stored items of information (rows in tables) are indicated by constraints that link tables together => In Neo4j, store relationships between nodes explicitly as relationships.
- Interpret the constraints as either JOINs or JoinTables:
- JOINs => Store JOINs as relationships.
- JoinTables are not tables; they are also stored as relationships.
Iteration 4: Intermediate entities
Getting back to work:
- Identify first-class objects: tables, constraints, JOINs and JoinTables
- Export to Neo4j
When we try importing JoinTables, it’s not hard to notice a few anomalies.
In MySQL…
There are tables that appear as JOIN tables but JOIN more than two tables, i.e., they contain more than two ForeignKeys.
In Northwind, we don’t have such a table, but Orders could be seen as such an intermediate table that connects all the other tables such as Employees, Customers and Shippers.

…Translated to Neo4j:
In Neo4j, such a table is imported as a node. Often times these are “missing” entities or concepts in your domain. The ForeignKeys are transformed into relationships as expected and the JOIN table is imported as an intermediate node.
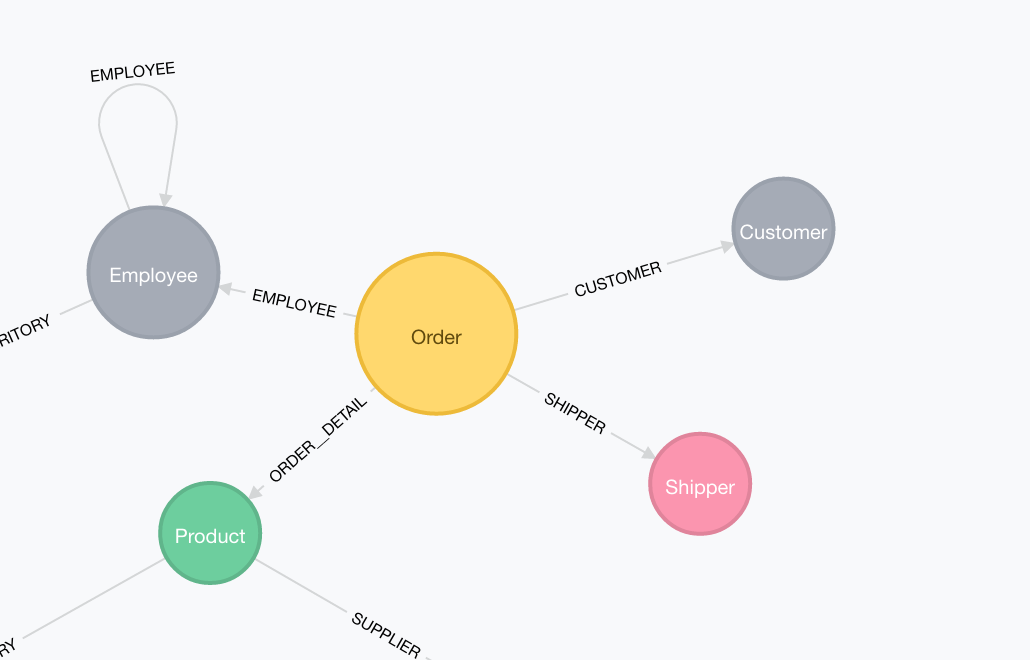
So we update the rules to the following:
- All information is stored in tables => In Neo4j, store information in nodes with properties.
- Relationships between stored items of information (rows in tables) are indicated by constraints that link tables together => In Neo4j, store relationships between nodes explicitly as relationships.
- Interpret the constraints as either JOINs or JoinTables.
- JOINs => Store JOINs as relationships.
- JoinTables that have exactly two
ForeignKeysare stored as relationships. - Tables that match the intermediate node case (more than two
ForeignKeys) get imported as nodes and the JOINs to the other tables are stored as relationships.
Iteration 5: Are we there yet? Applying the mapping rules during the export
Once we mapped the entire schema to Tables, JOINs and JoinTables we started working on the doing the actual import of data based on these mappings. We decided to use the neo4j-import tool to do our bulk import. This tool accepts CSV files that represent nodes and relationships.
A note on generating CSV files: We wrote a CSV generator that generates the files based on the mappings that we have already identified by interpreting the relational schema to the nodes and relationships.
Both capabilities (generate-mappings and export) are accessible via the neo4j-etl command-line tool.
You could run the complete operation at once, using the export command. We also made an architecture decision to have the ability to:
- Generate only the mapping in a JSON format using the
generate-mappingscommand. - Only running the export using an already generated mapping file by passing in a
csv-resourcesoption to theexportcommand.
This was done so that the users have more control over the process, e.g., to edit the mapping based on knowledge of their own domain. After all, you know your domain best. You can find more about the mapping format in the documentation.
./bin/neo4j-etl mysql export --user--password --database northwind --destination $NEO4J_HOME/data/databases/graph.db/ --import-tool $NEO4J_HOME/bin --csv-directory /tmp
Architecture diagram

Example of mapping a relational to a graph model
If you’ve gotten this far, here’s your before and after picture. 🙂
Let’s start with the full ER diagram of a Northwind database:

After you run the neo4j-etl tool against this Northwind database…
./bin/neo4j-etl mysql export --user--password --database northwind --destination $NEO4J_HOME/data/databases/graph.db/ --import-tool $NEO4J_HOME/bin --csv-directory /tmp
…the resulting graph model in Neo4j looks like this:
Conclusion
Personally, I learnt a lot about schema definitions and different ways to express this in both the relational database world and in the graph database world.
I hope this ETL tool will help you get one step closer to using Neo4j if not as a replacement, at least as a conjecture with your existing repertoire of databases in your ETL pipeline.
We are excited about the future of neo4j-etl-components and its adoption, and we are looking forward for your feedback and contributions.
Please go ahead and test the tool:
- GitHub Repository
- GitHub Issues
- Documentation
Cheers, Praveena
Share Article



Explore
Related Articles

Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report

POLE+O: The 5-Type Ontology That Solves the Hardest Part of Building a Knowledge Graph

1 of 3: The difference between a graph, a knowledge graph, and a context graph
