


Personalized Product Recommendations at Nordstrom
Data Scientist
8 min read

Editor’s Note: This presentation was given by Seth Dimick at GraphConnect New York in September 2018. At the time Dimick gave this talk, he was a data scientist at Nordstrom.
Presentation Summary
Using a property graph model to surface relevant content to users is now common practice for many digital experiences, from social media to retail.
At Nordstrom, a one-step Markov chain, or transition matrix, was implemented in October 2017 to provide shoppers with personalized homepage content on the mobile web experience. This implementation yielded significant conversion lift. However, while the transition matrix implementation proved successful in one instance, the approach was hard to scale and iterate when using relational data structures.
To expand upon this success, Nordstrom Data Scientist Seth Dimick’s Summer 2018 Nordstrom Hackathon team, Graphathon, built a Neo4j graph database with our website clickstream data. The MVP graph model included product view and purchase data connected by shopper interactions for adult men’s shoes.
In this post, Dimick discusses the importance of recommendations and why graphs are integral in providing useful and popular recommendations with existing data. He presents the graph that his team came up with and the strategies they utilized in the process.
Full Presentation: Personalized Product Recommendations at Nordstrom
My name is Seth Dimick and I’ve been working in analytics at Nordstrom for the last two years. Nordstrom is a fashion retailer that strives to deliver the best customer experiences in both our stores and online.
At Nordstrom.com, we know that a seamless digital experience is not only beneficial to the customer, but is now expected. Doing this requires investment in technology. One of the key investments Nordstrom makes is an internal hackathon program.
We hold three hackathons each year. Typically, we hack for two days and on the third day, we present a completed project to a panel of senior leadership for judging.
So for last summer’s hackathon, my team and I decided to take on graph recommendations.
A quick disclaimer before we get into things: Recommendations is not my domain of expertise and neither is graph. I just wanted to try it out. But, I hope that me walking you through this process will help you generate your own graph ideas.
Why Recommendations?
So, why recommendations? If you’re coming from an industry other than retail, you may not know their importance.
Recommendations on a website have become an essential navigation and discoverability tool for online shoppers. Imagine getting to a product page on a website and only having the option of either adding that item to your bag or hitting the back button. In this scenario, you’ve essentially reached a dead end, which is not a good shopping experience at all.
What we need to do is provide the right path forward for the shopper. Through numerous A/B tests on our website, we confirmed that tweaks in recommendation placement and strategy make a huge impact to the customer experience as well as shopper outcomes.
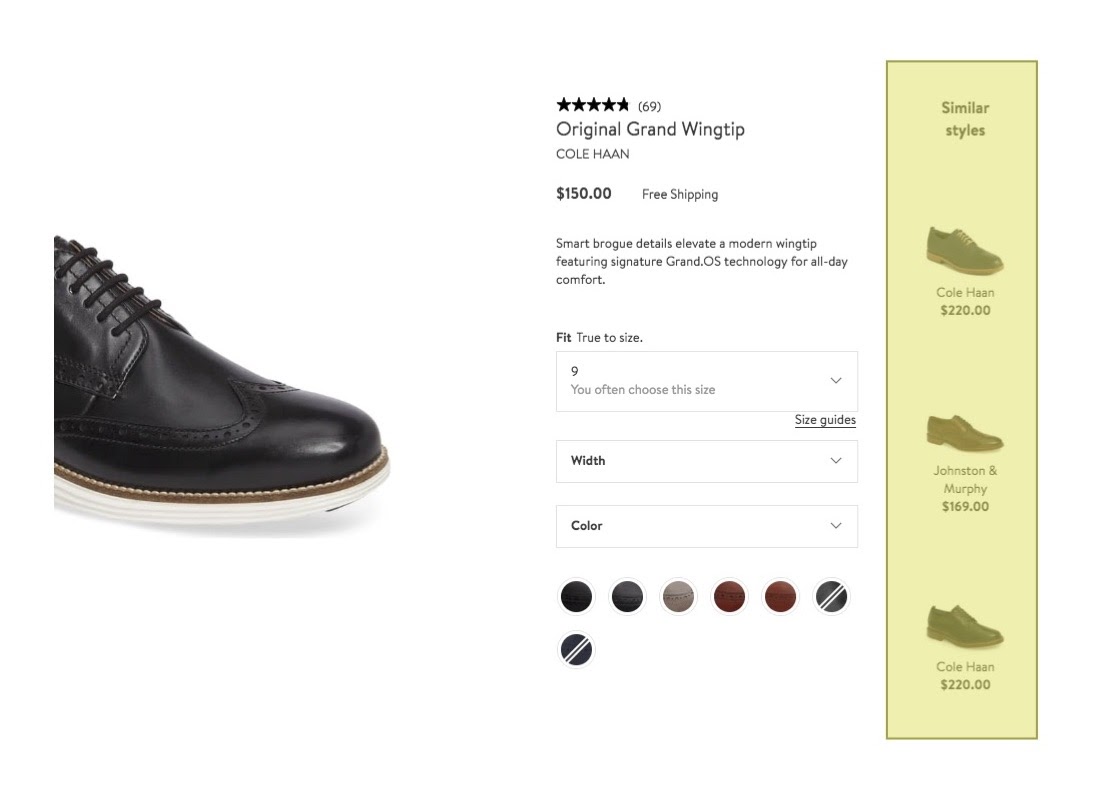
So, that’s why we need recommendations in general. Specifically for Nordstrom, there’s also a personalization opportunity for our recommendations in real time.
Before participating in this hackathon, I worked on a project where I helped personalize the order of content on our mobile home page.
On our mobile homepage, we have this series of content tiles, shown in the image below. Some of these tiles are fixed marketing initiatives, but others are product based. Here, we have the freedom to rearrange the tiles based on shoppers and their preferences.
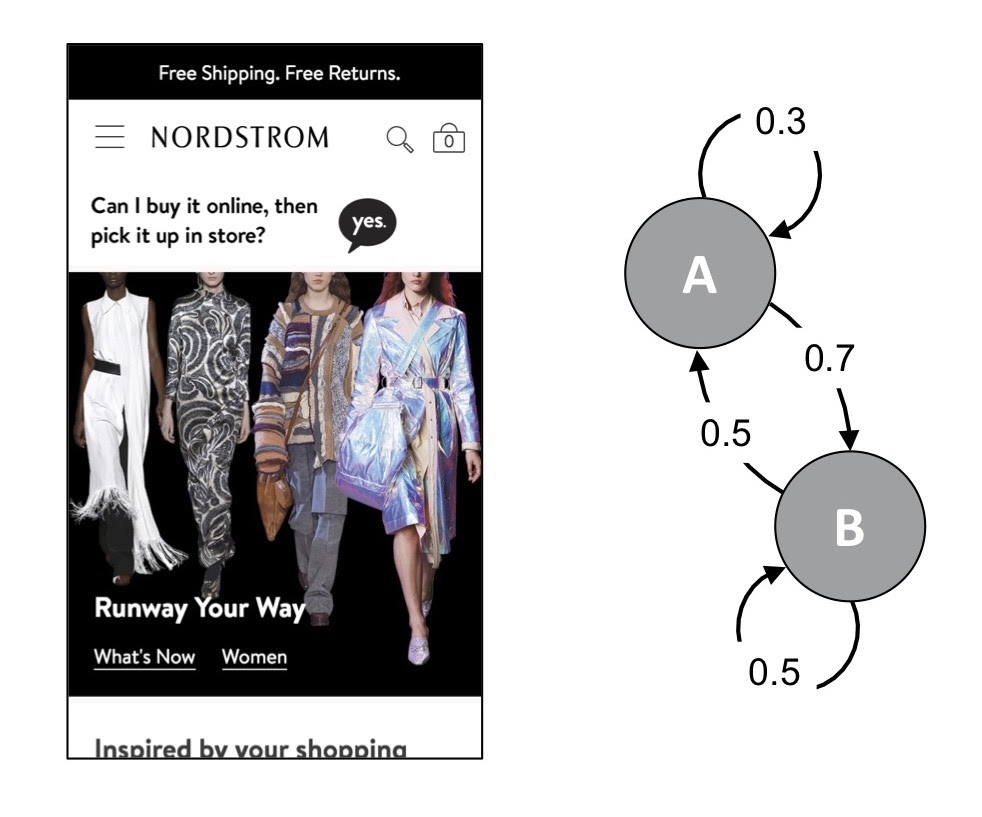
What we did before using graph was we used a Markov chain model approach, shown on the right, which is naturally a graph in your mind.
But to do all of this without graph itself, we had to use a transition matrix where we stored the probabilities of moving from one state to another. For a very simple Markov chain like the one above, you have four scores to store in your transition matrix: the probability of going from A to A, A to B, B to A and B to B.
To do this for the content on our page, we developed scores for the possibility of transitioning between brands, genders and age groups of our products. Then, we tied products and customers associated with the same attributes of content on the page. In this way, we found positive shopper outcomes by personalizing the order of this content and surfacing that relevant content sooner to the shopper.
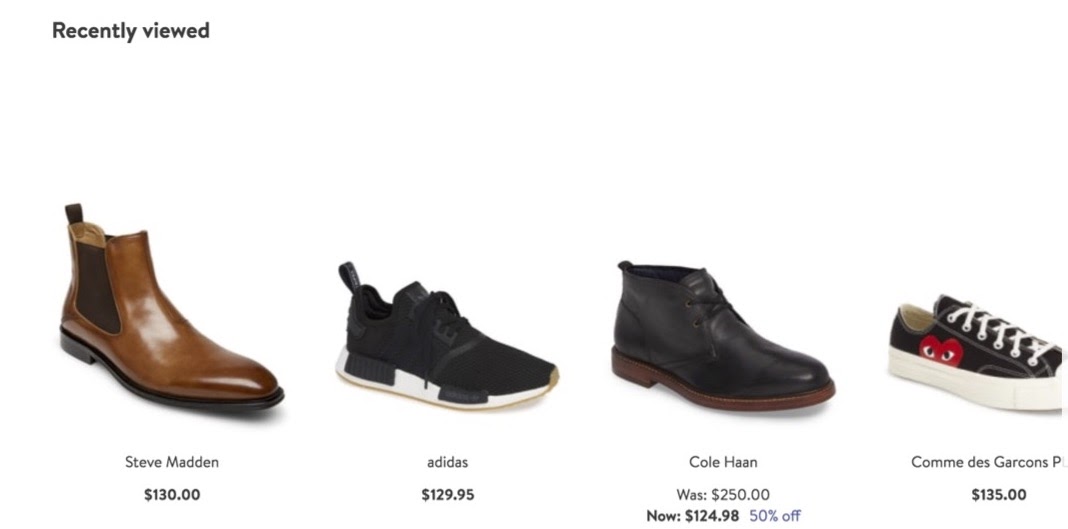
Another reason we tackled this with recommendations was that there was already data available on our site to recommend in real time for shoppers as they’re exploring our product pages. We have a live event stream on our website that populates our recently viewed tray of items (shown below), so we already know exactly what the shopper’s journey looks like as they go through our website.
Why Graph?
I was introduced to Neo4j in 2017 after doing a transition matrix approach, and thought it might be a good idea to try it out.
Particularly, I thought it would solve the scaling problem that I was facing. For the homepage, we were just documenting transitions between generic attributes of products, not exact products or – as we call them at Nordstroms – styles.

Imagine if you had a catalog of 200,000 possible styles. If you wanted to document transitions between just those styles, you would square 200,000 and immediately have 40 billion possible transitions to score and store relationally.
So I thought: What if we wanted to take more of the shopper context into consideration? Say you wanted to not only take into consideration one thing, but the thing they did before that as well? Here, if you wanted to do two steps, you’d need to cube 200,000. Now, you’re looking at eight quadrillion possibilities and some colossal joins that would make your database administrators very irritated with you.
Graphs, on the other hand, are perfectly suited for mapping a customer journey like this. You can just use one node for each of your styles and record relationships between them as they occur.
Scope
A quick note on the scope of this hackathon project that we did. I think it’s best practice – with any new data venture – to pick a small sample from all the possible data that exists.
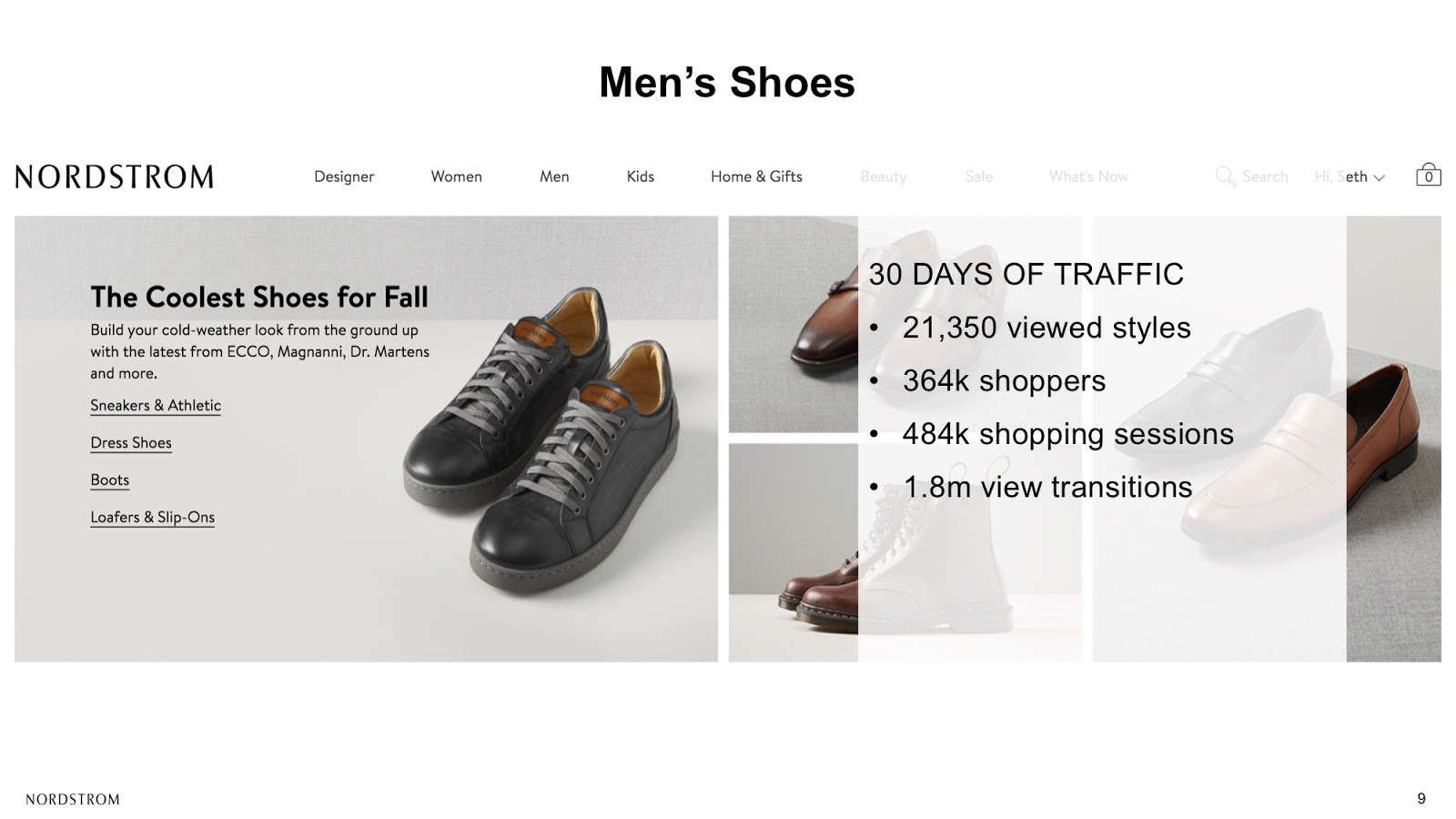
Our team tackled a sample from 30 days of traffic from our Men’s Shoes Category on the site, which looked at about 20,000 unique styles and two million transitions between those styles.
The Graph
Let’s get into the graph itself.
We had a very simple initial concept for our graph that would take into consideration just two steps of the customer journey: the current style being viewed and the most recent style viewed before that. Then, we wanted to find all the paths of shoppers who had done that before and moved on to another item. We would then suggest the top item based on the number of paths we observed.
We can do with a very simple schema graph. We just have one type of node representing our products with their specific styles. Then we have these next view relationships between them, which document a shopper’s sequential move from one product to another.

In order to do this correctly, we need to make sure that the two next view relationships in this scenario are done by the same shopper. We’d have to confirm that the shopper identifier is equated.
Luckily, we had one engineer on our team who had used graphs before. He knew that it’s actually much more performant to query on an indexed attribute, which you can do on a node.
So, we changed up our schema just a little bit (shown below) by adding more complexity and changing those next view relationships to nodes. Then, on those next view nodes in the middle, we actually put our shopper identifiers and added very simple next relationships connecting the chain, so each next view node had exactly two relationships.
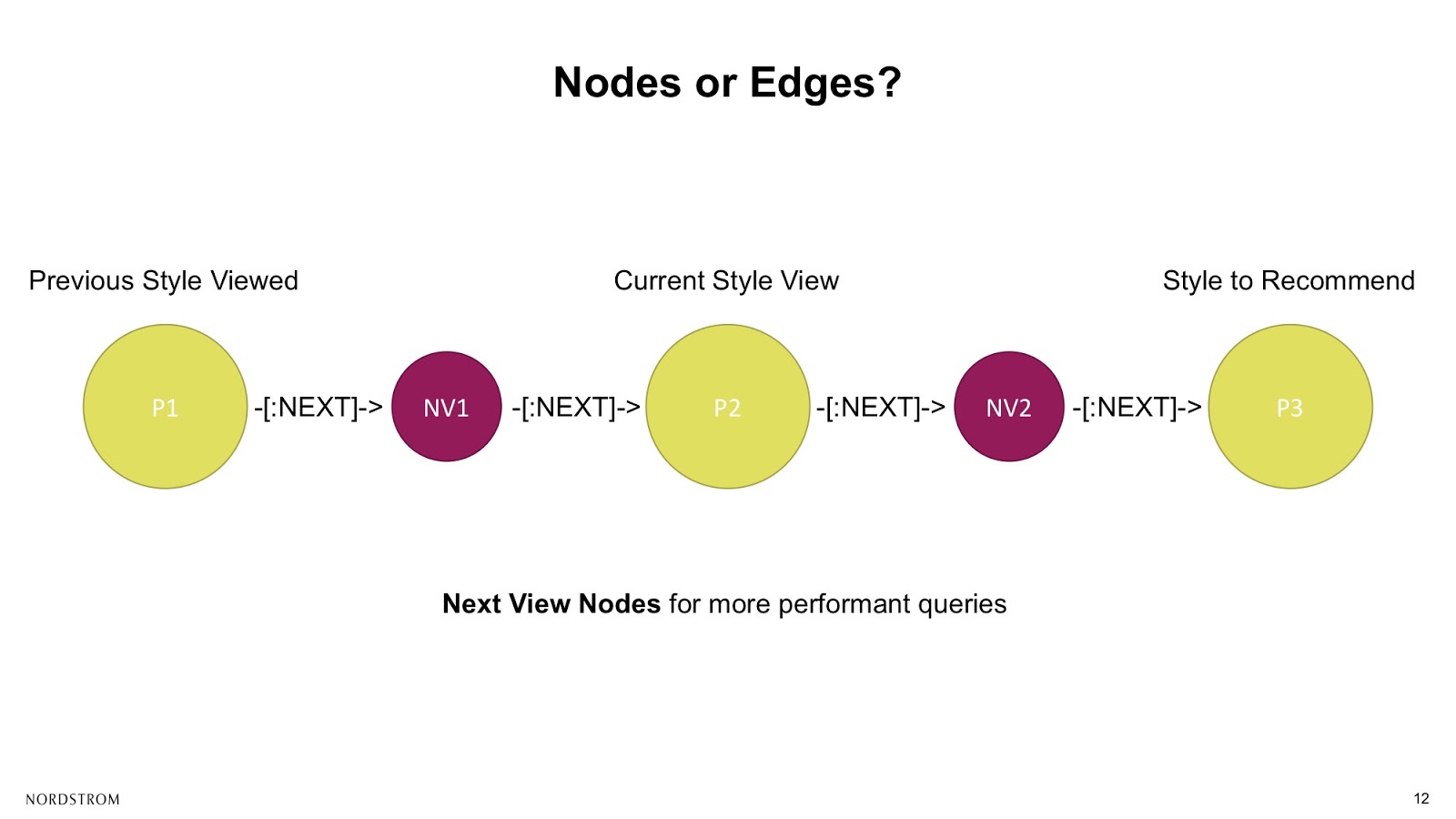
This allows us to perform the query much quicker and also aggregate faster on the nodes instead of the relationships. Believe it or not, we had a little extra time in the two days while we were building up this system, so we wanted to wow the judges and show how flexible this model can be by adding in a traditional property graph model as well.
From that same sample, we went ahead and added on shopper nodes in that time period with viewed and purchased relationships to our products, as shown below.
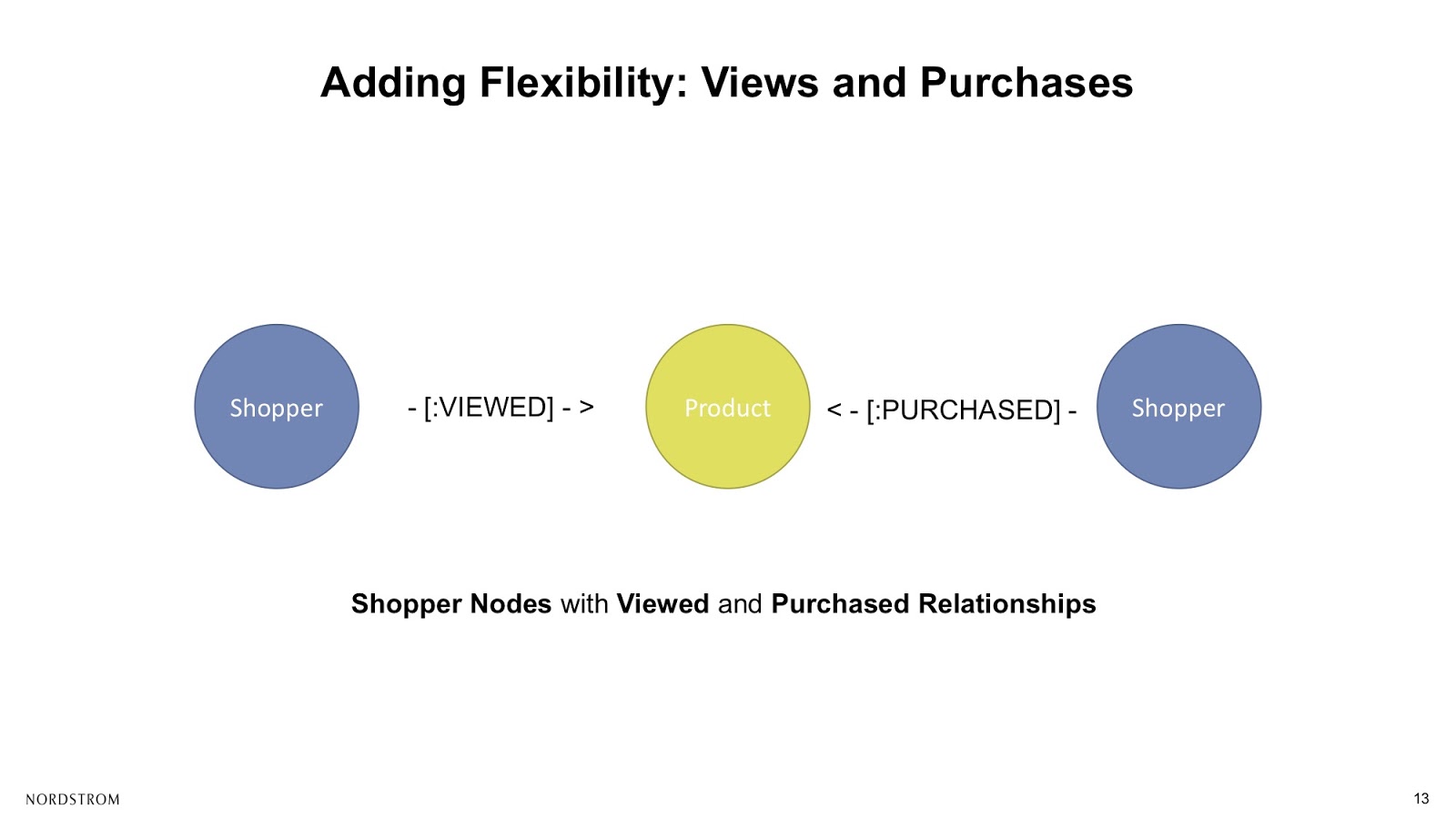
The Strategies
Let’s get into the strategies. First, I’ll cover how we emulated a very simple “People Also Bought” strategy.
We have some Cypher in the slide below, if you’re a little rusty on Cypher or haven’t done it before.

I’m not claiming this to be the most simple or pure way to write this query, but it’s very easy to understand, which is the great thing about Cypher. What we’re doing with this Cypher query is we’re simply finding all the shoppers who bought the currently viewed style.
Then, we’re going to take those same shoppers that we’ve saved as S on the left-hand side (in that second line) and we’re going to find all the products that those shoppers purchased, where those products are not the one that we’re looking at right now. What we can do from there is count up the number of people who’ve bought each one of these unique styles and return the top ones.
The one we actually wanted to execute on for this Hackathon was taking into consideration more context for our “Viewed Next” feature, which is written out very simply below.

With our parametrized style1 on the top line, we’re looking for the style you viewed previously – the one most recent in our events stream – and the style that you’re viewing right now, and then looking for all the paths where anyone viewed those two items sequentially and went on to view a third product after that.
Once we had all those paths found, we could simply count up which styles on the end have the most paths going towards them and return the most popular ones.
What’s Next?
As I said above, recommendations is not my domain of expertise, but one of the team members on this Hackathon does work on that recommendation platform. They continue to investigate how to get graph-based strategies on par with our current system and what it will take to get this into production.
For me, I’m hoping to leverage this experience to apply to a different domain area that I do work on, which is the “Looks” aspect of the Nordstrom website.

Right now, you’ll see it across a lot of different product pages. These looks are hand-curated stylings of our products put together by merchants and stylists to help our customers visualize how to wear these products. They also serve as an additional recommendation to cross-sell our items, just like a salesperson does for you in the store.
In this way, I hope to use graphs to model these hand-curated outfits, find the associations between products and their attributes, and build out a suite of tools for our stylists and merchants create these looks more efficiently.
Share Article



Explore
Related Articles

Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.



Unlocking High-Conversion Recommendations with Graph Analytics in Snowflake

