Running decision trees in Neo4j

Field Engineer
11 min read

Editor’s Note: This presentation was given by Max De Marzi at GraphConnect 2018 in New York City.
Presentation summary
In this presentation, Max De Marzi shares how decision trees are used to make near real-time decisions using a graph database. In this case, he uses the unorthodox example of nightclub entrance criteria .
Max uses the example of a fictional nightclub. The club rules are that anyone over the age of 21 is always welcome within the club. However, on some nights men 18 and older are allowed inside, and on other nights, women 18 and older are allowed in. The last two rules change at the owner’s discretion.
In order to enforce these rules programmatically, Max shows you how to use a decision tree in a graph database. Your decision tree is bound by rule nodes that match those provided by the establishment.
In order to build a decision tree on top of a graph database, you need to use the traversal framework Java API. Traversal APIs use evaluators and expanders. Evaluators distinguish whether a path is correct or not, while expanders continue to input information as you traverse the decision tree graph.
If we have input our information correctly, then we can turn to the isTrue method. The isTrue method compiles and runs the code then evaluates and returns the results of that evaluation in real time. The isTrue method is a Boolean so your results are delivered as a true or false statement.
Max concludes his presentation with an example of running the code and results. The value of a decision tree is it takes code as data and runs it in real time. This can be done with up to (and over) 10 different rule nodes and still deliver the same result performance.
Full presentation
My name is Max De Marzi. I’m Neo4j sales engineer, and I’ve been with the company for eight years. Today, I’ll be discussing decision trees in graph databases.
Bars, cocktails, dreams, disco and party
I’m going to start this post with a sign.

This is a really nice sign. It says “Bar, Cocktails, Dreams, Disco and Party.” This is the sign of a place we want to get into. However, the problem is, there’s a dude in front of the sign with a big giant hand. He says, “You can’t get in unless you pass some kind of test.”
There are some rules for getting into this disco. The rules are:
- Anyone over the age of 21 is allowed to get in.
- On some nights, women 18 years old are allowed in.
- On some other nights, men 18 years old are allowed in.
The last two rules change dynamically. The rules are subject to change whenever the owners feel like it. Our question is: How do we present this in a graph data model? We present it kind of like so, below.

In the above graph model, we have a tree, this is what our decisions are going to fit into, and we have the first rule. The first rule asks: Are you age 21 or older? If the answer is true, then you go down to the yes node. From the IS_TRUE relationship, you are allowed to get into the club.
If the answer is false, and you are not age 21 or older, then we check something else. We then ask: Are you 18 or older?
Then the gender equals some gender, and we don’t know what that is just yet. And if that’s true, then that is great. That means that you are allowed to get in as well. However, if it’s false, out you go. You are not allowed in.
A closer look at the rule node
Here is a bit of a zoom in on what the rule node looks like.

As you can see above, we have an expression that says: You have to be over 18, and the gender equals female. The expression could be whatever you choose as long as you express it in code. In this case, our code is Java.
The rule node needs to know what kind of parameters it’s dealing with. In this case, we have age and gender. Those are the two parameters we care about. Then, we need to know what type of parameters these are. One is an integer and the other is a string.
One is an integer. One is a string. You could throw in an array, and do whatever you want with it, but we need to know what’s there.
Working with the Traversal Framework Java API
There was a time, before Cypher, where the traversal framework Java API ruled supreme. The traversal Java API is a vestige from our Java-only days. It basically said, “I’m going to describe a traversal, and this thing is going to execute it.”
A traversal API is a little bit hard to learn. It has a few things you need to figure out.

One thing you need to figure out is the order. Are you going to go depth first, or do you go breadth first? Ninety-nine percent of the time, you want to go depth first.
You will have to build a traversal API. The traversal API has an evaluator that tells you whether the path is good or not. You have the ability to tell the API to do some calculations, then do some analytics. Finally, the API could tell me whether I want to keep this path or not keep this path.
We also have uniqueness constraints. Do you want to have only the nodes be unique, relations be unique, or just keep it the default?
Then, we have an expander. The expander tells you where you will go next. As you’re traversing the graph dataset, it will tell you which direction to take, which relationship type to take, and what’s happening.
Building a stored procedure
Next, I’m going to build a stored procedure.
What I’m trying to do can’t be done with Cypher. The stored procedure is going to take two things. It’s going to take the tree that I care about and then it is going to take a set of facts.

If you’ve never done Neo4j’s Cypher procedure, then the above looks pretty ugly. It’s basically a little bit of Java code. You are able to use any JVM language. This thing is going to take some input, which is our tree, or the string where the tree is and a set of facts.
We’re going to find the tree in our graph. Then I’m going to look at this decision path method.
The decision path method
Let’s look at the decision path below.

We need to build a traversal description. Like I mentioned earlier, we are going to go depth first. We’re going to expand using a decision tree expander, and then we are going to enter facts into our decision tree expander. As we continue to traverse, we will enter in new facts. That’s why we create a new one every time.
The first thing we need to create is an evaluator. The evaluator tells us when to stop traversing or when to accept this path or not. The evaluator looks like below.

It says, if you get to an answer, then stop. That is because the path is good. Include the path and stop working, because you found the answer. If not, keep going until you find the answer.
Building a path expander
The next thing we need to do is build the expander. The expander needs to be fed facts. That is where the magic happens.
This particular expander below has an expression evaluator.

This is where we’re going to build some dynamic Java. The expander works as a Boolean whether it’s true or false. I’m going to create it every time with a new set of facts, and by doing that, I’m creating my expander. I’m going to return a Boolean and have some facts.
The expander says, “If you get to an answer node, stop. Return nothing; don’t go anywhere. You’ve figured it out. You’ve found the answer; stop working.”

Let’s say I haven’t found an answer. Then I look at the end node or my current node in the path. I give the command, “If I have any path relationships, then continue on those; otherwise, stop.” What would happen then?
Eventually we get to a rule node, like the one shown below. To get to the rule, we have to evaluate the rule, execute it and see what’s going on.

The rule is going to go in and evaluate this other method called isTrue. That will figure out whether the true gets triggered or doesn’t get triggered. If it’s true, we continue down the isTrue relationships. If it’s false, we continue down the isFalse relationships and that’s it.
The isTrue Magical Method
What is this isTrue magical method, and what does it do?
isTrue tells us which way we’re going to go. Here’s how it works: We take the properties of the rule. The properties are what’s going to have our parameters, our parameter types and the expression of what the rule is.

We’re going to explode the parameter names and the parameter types into happy little arrays. We are going to have an array of strings and an array of classes. Then, we are going to create these objects from these facts.

We’re going to take these facts, pump them into our parameter types and add names with their types. Then, we’re going to set these parameters into this expression. Finally, we’re going to cook it.
This basically means we’re going to compile the code, run the code, evaluate it and return the results of that evaluation, which is a Boolean (i.e., our answer will only be true or false).
Running the code
We’re actually executing this code as we’re running the traversal.
We need to bring back Cypher. In this case, that is because we have to build a tree. To build a tree in Cypher, we have to create a tree node and then create some rules.

The rule says over 21, the second rule is a gender rule, over 18. We have our answer nodes, and then we connect everything together.
Now we have to pass in some facts to our stored procedure and see whether we fail or not. If it’s a male, 20 years old, we pass in gender male. If the male is age 20, we run this query, and it comes back with no.

Sorry, you’re staying home. You’re not allowed to go into the club.

Not only that, it comes back with a path, which tells us how we get to the answer of no. It went through, “Age over 21?”, nope, and then gender does not equal female. Therefore, he doesn’t get let in.
Our second user happens to be a woman who is 19. We run this query, and the answer is true. She’s not over 21, but she is over 18 and a woman.

Therefore, she is allowed in.
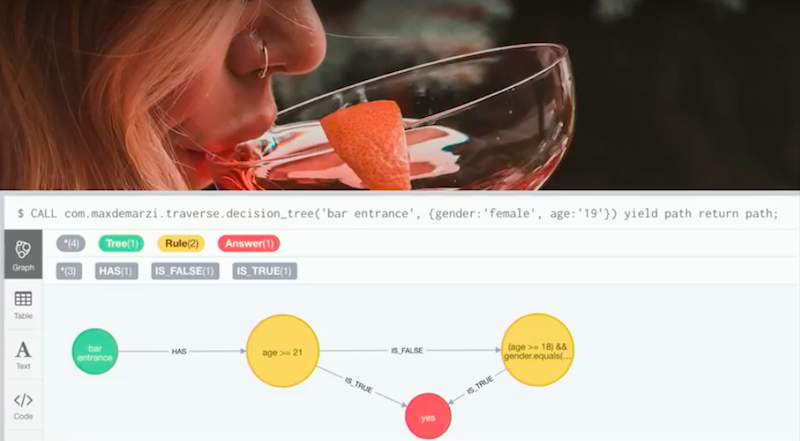
What this has done is taking code as data. This is deliverable to an end user, and the query ran in real time.
This use case came from a project where users were building pharmaceutical drug recommendations. These drug recommendations were based on research. The research comes out every quarter, and they have the decision tree of what drug do I give someone based on all the evidence and relevant medical papers.
There is a group of doctors who were analyzing this data and building a decision tree based on it. These guys were doing it by hand through just expert knowledge. However, there are other ways to build decision trees.
Conclusion
If you’d like to learn more about decision trees, I keep a self-named blog at MaxDeMarzi.com. There are 141 blog posts on different things related to Neo4j.
In addition, most of the code we write is open source, and you’ll find about 200 public repos on that account, most of which is MIT licensed. You’re free to grab it, and do whatever you want with it.
Share Article



Explore
Related Articles


A workbench for teams to query, explore, and visualize graph data
Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report


1 of 3: The difference between a graph, a knowledge graph, and a context graph
