







How Scribestar Uses Neo4j for Faster Coding Cycles

Chief Architect, Scribestar
9 min read
Editor’s Note: This presentation was given by Srinivas Suravarapu at GraphConnect Europe in April 2016. Here’s a quick review of what he covered:
–
What we’re going to be talking about today is the business benefits Scribestar enjoyed after switching to Neo4j:
Scribestar is a small company with only around 20 people. Even so, we’re building a great product that fills a market need. We target the legal industry — specifically lawyers and associates — and this new generation of lawyers relies on desktop publishing tools. Frequently documents are prepared in Word and circulated for edits, which naturally calls for a content management system use case.
Having a number of users working on a bunch of documents naturally lends to some sort of collaboration platform. We are building just such a platform predominantly on .NET, but we’re using Neo4j and RavenFS as file stores. We have to keep our customers’ data secure, so we use RavenFS because it comes with encryption services.
Let’s back up a moment to the technologies that were available eight years ago when I working at a different content management system startup, which we built in an SQL server. We stored our web pages in a content management system site map such as BLOBs alongside user metadata.
We found that as the amount of content grew, our database became less efficient. This can be attributed to the basic functionality of SQL, and unless you have endless amounts of money to spend on hardware, the entire system will come to a grinding halt.
Shortly after that time, there were attempts to start new CMS platforms as alternatives to SQL databases. These included Umbraco and RebelCMS, which relied on document stores. But the minute you try to place content and relational data together in any type of data store, you’re reducing the life cycle of your product because of the resulting cost and staffing increases.
From the very beginning you have to split your data properly, store it in the right place and pay attention to who’s consuming it. If you don’t, you’re putting your business at a huge disadvantage.
Perfecting Your Database Architecture
When choosing your data store, it’s crucial to pay attention to the type of data you’re working with and how it’s consumed by your application. With polyglot persistence, you can combine a number of data stores that best suit the different types of data you’re working with.
In our platform, every company is a tenancy, and users in each company are related to that tenancy. On the collaboration side, we call our content documents, which is a logical block that splits into several content pieces.
Each piece of content is unique in the sense that it maintains its data integrity even when separated from all other content. We put a graph in front of the content with a file store — RavenFS — that streams files back and forth to the web layer.
Below is a pared-down version of our database architecture:

We have collaboration services; data stores such as Neo4j and RavenFS; a publishing service that preps the document; a variety of infrastructure services; and a browser-based content editor.
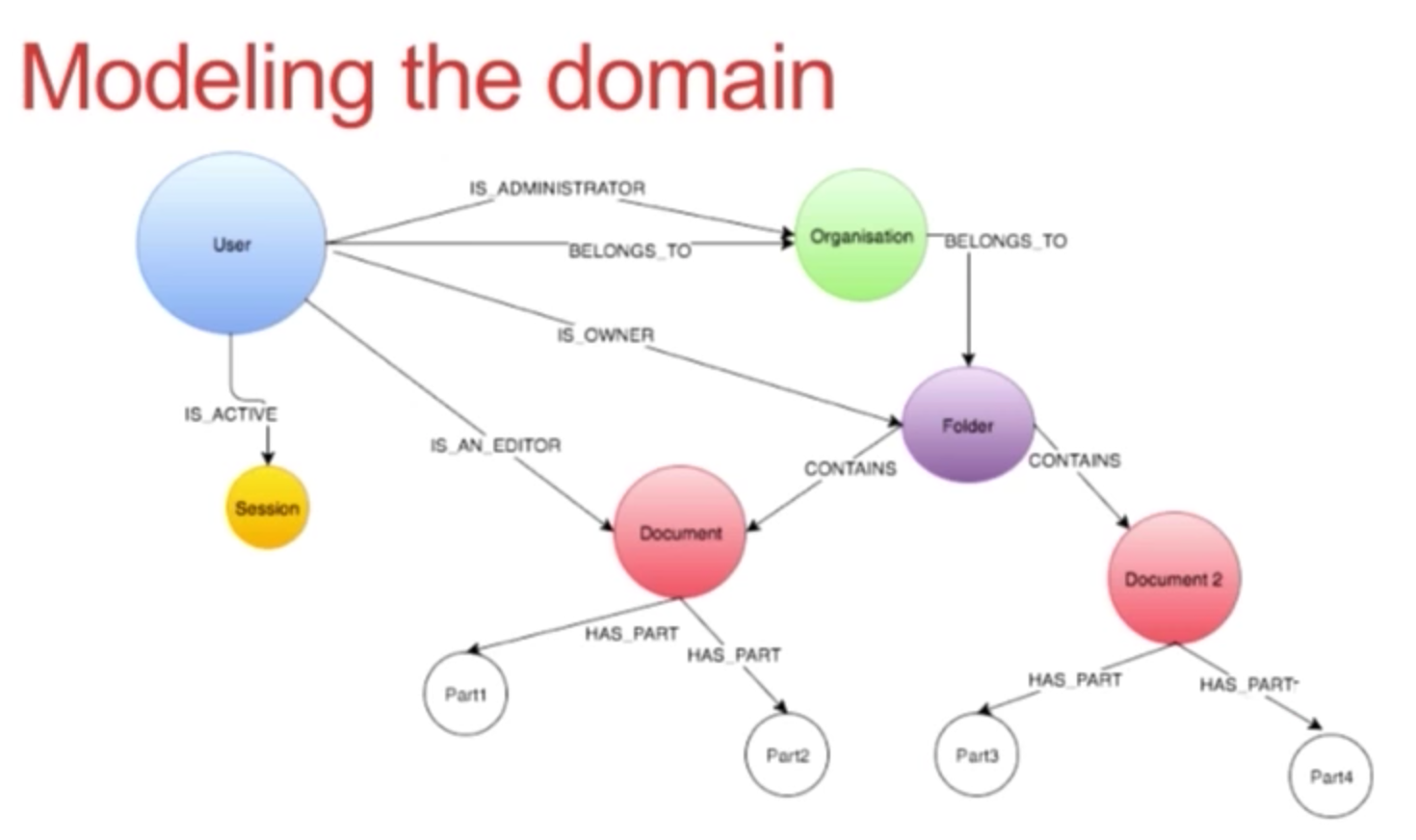
The Scribestar Domain Model
Below is the Scribestar domain and data model:
We have a user who is related to a few organizations and who we track each time they log in via sessions. By creating a session node, we can go back and see how many times a user has logged into the system and how long they were active. The document is the primary block of content from a user’s point of view and is grouped into the concept of folders.
It’s incredibly important to split up your data, so we decided to split our model into two parts using bounded context, which resulted in the following tree:

In this context, the document user is not the real user — it’s just the authentication and security information, which is a reference to that aggregate from another service. If we wanted to, we could even isolate every graph at the level of a document.
In our case, the document has all the information we need stored as properties that appear as fragments. And we’ve modeled the document so that it essentially knows where to go.
Every time a request comes to the collaboration service, the data store — Neo4j — quickly figures out where it needs to store that file. The only time we see latency is when a user is pushing a large volume of content back to the server in a file stream.
We maintain tenancies and users on the administration side of the domain in a very flexible model:

Building Versioning into the Data Store
And now comes the interesting part. How did we build versioning into our data store?

All the content changes are happening in the documents. Anyone working on a particular part in a document is changing content in that part — the yellow node at the bottom. We call it a check in and a checkout, just like in SharePoint.
When you checkout a part, we clone that node, create a new copy of the content from that particular point in time, and let the user work in the green node (checkout). Now if the user decides to check in at that exact same time, we just switch the relation and update the URA of the part of the work in progress. And if the user decides to abandon it, we don’t do anything; we know that the changes were abandoned.
The grey “document” node on the left of the model may seem unimportant, but it’s actually the source of how we view a user’s actions in a document over a period of time. TimeTree is a simple library for representing time in Neo4j as a tree of time instants, which we plan on plugging in to our data store in the near future. And all together, this makes up our sitemap.
Tips and Tricks for Modeling your Domain
When modeling your domain, there are a few things that are important to keep in mind. The first is to stay as close as possible to the domain and let the graph be a reflection of user actions in the system over time.
Does your data model look like a database table with very system-specific names and tasks? The best way to make sure members of your management team understand the data model is to make sure your graph represents the user domain in which you’re working, rather than of the system. This allows you to visually represent your data in a way users will understand.
Another thing to remember is that bounded contexts still apply, along with the rules of how you share information between two aggregates. Because we split the graph itself into several parts, we have a natural separation of data that then makes it much easier for us to scale that data. We also made sure we had simple, acyclic graphs, and because of this haven’t run into any issues with migration or with unique cases in separate places.
Coding Tips and Database Principles
We started our business four years ago, and three years ago we didn’t have a product. And even though we had already spent millions, we revisited and rebuilt our architecture and product in a more aggressively user-friendly way. But we needed to do this quickly, and I cannot tell you how thankful I am that we chose Neo4j.
We’re an agile company. We’ve been working on a feature backlog and are constantly building the product into our beta environment, and the platform’s speed and performance is continually improving.
It’s not uncommon that as soon as you put a team of people in front of any new graph technology such as Neo4j, they forget all the key principles that applied in their previous database. These principles include the following:

I included the bullet about reuse due to an issue we came across, which was caused by reusing Cypher queries with full graph scans. Instead of reusing your queries, duplicate and isolate them. For example, if query A asks for one projection of data and query B asks for an additional projection of data, keep the queries separate.
Tricks for Tuning your Cypher
I was really pleased with Neo4j’s Cypher tuning. As soon as I turned on query logging, I could easily — and quickly — pinpoint and fix our database issues. For the last several months, we’ve been tweaking our systems and are now miles ahead of where we were.
Below are some quick pointers for tuning your Cypher:

The Business Benefits of Switching to Neo4j
As I mentioned earlier, we had a team of about 25 people when I first joined Scribestar. At the time, we were working on this massive algorithm on differential synchronization, which allows for the synchronization of content changes.
Below is an outline of the business benefits that resulted from our switch to Neo4j, although these successes were also due in part to some of the other tools we were using:

The team that built our solution was half the size of the original team. Our new system is much faster than our old system, and while I can’t place a specific number on the increase, it’s at least in the double-digits.
Here’s a quick example. When we initially ran testing in our Neo4j database at check in with 500,000 nodes, it took four to five seconds because we didn’t have our indexes right. This is because our queries were doing scans of the entire graph when it should have just been looking for a specific node. After correcting this, the average time after 20 runs came down to 39 milliseconds.

The complexity of the work has also been reduced. We analyzed our data from Q1 2015 to Q1 2016 and went from 43-day coding cycles to 17- or 18-day cycles. This was because the definition of cycle time changed. When we were first doing cycles, it was just about developing and testing.
Now, our cycles are about developing, testing, going through a UAT phase, having a performance test review, and then going into a beta environment. So the cycle time has widened up, but the ability to actually build these things has been constant.
The next thing I’m able to do is show my COO the graph. He’s ex-general counsel, and if he as a lawyer can understand the graph, then it’s very likely our users can understand it as well. He can immediately understand how the documents and content are moved, what documents are worked on at a specific point in time, etc.
What The Future Holds for Scribestar

In the future, if RavenFS gives us a lot of problems, we can switch it out for something more like Riak or S3. We have to host everything in-house because we have a system with strict security requirements and encrypted data in file stores. This unfortunately results in some latency, but this level of security is essential to our product.
It would be great to have Linkurious on the same dashboard as Neo4j, because this would allow us to translate the data in one place while continuing to control access.
In terms of value from the graph itself, I’ll refer to the legal concept of precedent. When you prepare a document for a specific circumstance with a specific set of people, if that recurs in the future, it’s a precedent. This is why you can categorize these documents and use them for historical reasons.
Neo4j has been a great addition to our technology stack, and I have high hopes for how it’s going to scale out for us in the future.
Dive into Neo4j with this free ebook – Learning Neo4j – and catch up to speed with the world’s leading graph database.
Share Article



Explore
Related Articles


Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.



