


SoundCloud Tag Recommendations using Neo4j [Community Post]

COO of SilverLogic
5 min read
[As community content, this post reflects the views and opinions of the particular author and does not necessarily reflect the official stance of Neo4j.]
Introduction
Discovery, especially non-text discovery, is hard.
When looking for a some new music to listen to, for example, I might not know exactly what I want, only that I’m looking for something a little folksy that emphasizes my love of New Wave.
On the other hand, I might know exactly what I want: Some guided meditation in a soothing female voice with cafe background sounds, but unless the SoundCloud or YouTube artist that made the track was good about adding tags and descriptions in a language I understand, I’ll never find it.
Site administrators want products to be easy to find, catalog and market without having to pay someone to experience and catalog thousands of user-uploaded items. Clean, user-generated (or user-selected) tags can go a long way towards improving discoverability.
Unfortunately, free-form tags might degrade discoverability, as users might enter misspelled words or tags that are too personal. However, with the power of the ConceptNet5 dataset, a website can easily help users select and search by relevant tags in multiple languages.
This post outlines how to use the ConceptNet5 dataset and the SoundCloud API to recommend tags for user-generated items.
The Datasets
ConceptNet5
ConceptNet5 is a semantic network built from nodes representing words or short phrases of natural language (“terms” or “concepts”), and the relationships (“associations”) between them.
SoundCloud
SoundCloud is a website in which users can upload and listen to audio tracks.
The Graph
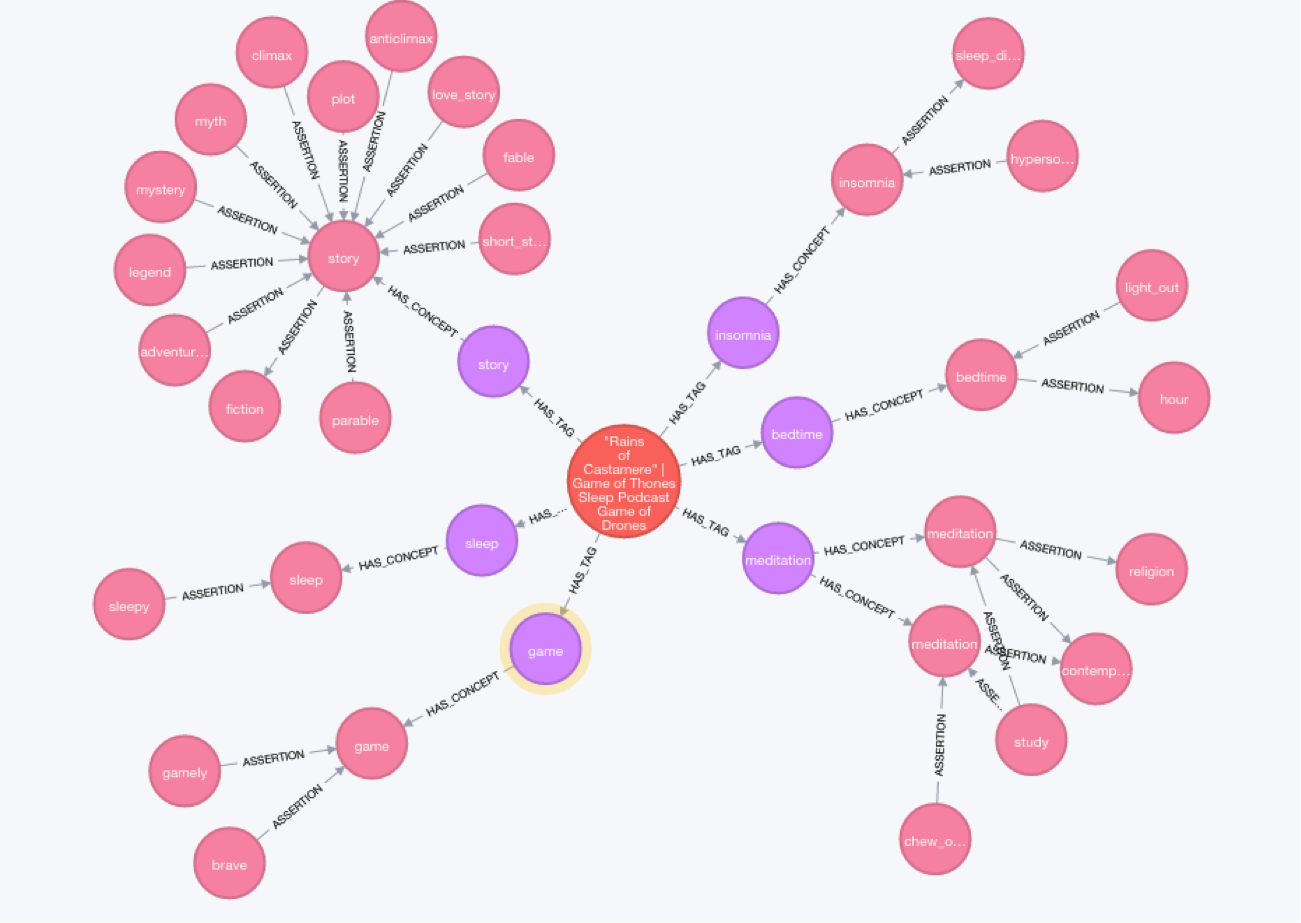
Evidently “Game of Drones” is a thing. The graph below depicts the track “Game of Drones,” its tags and the corresponding ConceptNet Concepts.
Nodes and their properties:
Track (orange)
- id: SoundCloud id of the track
- title: The title of the track
- playback_count: Number of times the track has been played
- permalink_url: URL of the track
Example Track:
- id: 241386808
- title: “Rains of Castamere” | Game of Thrones Sleep Podcast Game of Drones | Sleep With Me #219
- playback_count: 86
- permalink_url: https://soundcloud.com/sleepwithmepodcast/rains-of-castamere-game-of
Tag (purple)
- name: the name of the tag (for example, “story”)
Term (pink)
- concept: Concept represented by the term
- sense: In what sense is the term being used?
- language: In what language is the term
- partOfSpeech: The part of speech of the term
Example Term
- concept: story
- sense: a_piece_of_fiction_that_narrates_a_chain_of_related_events
- language: en
- partOfSpeech: n
Relationships and their properties:
(Track)-[:HAS_TAG]->(Tag)
SoundCloud tracks have tags generated by their creators. This is an N:N relationship.
(Tag)-[:HAS_CONCEPT]->(Term)
Tags are matched to Terms by their names. As related terms can have the same name (there are multiple senses of “toast”, for example), this is a 1:N relationship.
(Term)-[:ASSERTION]-(Term)
Assertions are how ConceptNet concepts are related to one another and have the properties:
- type: ‘IsA’, ‘IsNotA’, ‘DerivedFrom’, and many more
- weight: the strength of the assertion, calculated by ConceptNet
- surfaceText: A sentence explaining the assertion
Load the Data
The Code
Let’s load up the database:
import soundcloud
import six
import requests
import json
from py2neo import authenticate, Graph
NEO4J_USERNAME = "neo4j" #use your actual username
NEO4J_PASSWORD = "12345678" #use your actual password
SOUNDCLOUD_CLIENT_ID = '05b0dd03002bfa83d2109bbdfd7f1265'
client = soundcloud.Client(client_id=SOUNDCLOUD_CLIENT_ID)
authenticate("localhost:7474", NEO4J_USERNAME, NEO4J_PASSWORD)
graph = Graph()
page_size = 100
search_query = 'ambient' #or whatever you want your database to be about
# uniqueness constraints
graph.cypher.execute('CREATE CONSTRAINT ON (track:Track) ASSERT track.id IS UNIQUE')
graph.cypher.execute('CREATE CONSTRAINT ON (tag:Tag) ASSERT tag.name IS UNIQUE')
# Concept Import Query
addConceptNetData = """
WITH {json} AS document
UNWIND document.edges AS edges
WITH
SPLIT(edges.start,"/")[3] AS startConcept,
SPLIT(edges.start,"/")[2] AS startLanguage,
CASE WHEN SPLIT(edges.start,"/")[4] <> "" THEN SPLIT(edges.start,"/")[4] ELSE "" END AS startPartOfSpeech,
CASE WHEN SPLIT(edges.start,"/")[5] <> "" THEN SPLIT(edges.start,"/")[5] ELSE "" END AS startSense,
SPLIT(edges.rel,"/")[2] AS relType,
CASE WHEN edges.surfaceText <> "" THEN edges.surfaceText ELSE "" END AS surfaceText,
edges.weight AS weight,
SPLIT(edges.end,"/")[3] AS endConcept,
SPLIT(edges.end,"/")[2] AS endLanguage,
CASE WHEN SPLIT(edges.end,"/")[4] <> "" THEN SPLIT(edges.end,"/")[4] ELSE "" END AS endPartOfSpeech,
CASE WHEN SPLIT(edges.end,"/")[5] <> "" THEN SPLIT(edges.end,"/")[5] ELSE "" END AS endSense
MERGE (start:Term {concept:startConcept, language:startLanguage, partOfSpeech:startPartOfSpeech, sense:startSense})
MERGE (end:Term {concept:endConcept, language:endLanguage, partOfSpeech:endPartOfSpeech, sense:endSense})
MERGE (start)-[r:ASSERTION {type:relType, weight:weight, surfaceText:surfaceText}]-(end)
"""
# add track to database
addSoundCloudTrack = """
MERGE (track:Track {title:{title}, id:{id}, playback_count:{playback_count}, permalink_url:{permalink_url}})
RETURN 1
"""
# add soundcloud tag and connect to conceptnet5 terms (1:N) since tags don't have senses
addSoundCloudTag = """
MATCH (track:Track {id:{id}})
MERGE (tag:Tag {name:{tag}})
MERGE (track)-[:HAS_TAG]->(tag)
WITH track, tag
MATCH (term:Term {concept:{tag}})
MERGE (tag)-[:HAS_CONCEPT]->(term)
RETURN track.title, tag.name, term.sense
"""
# Updating concepts: Making sure they are in there from ConceptNet
tracks = client.get('/tracks', order='created_at', limit=page_size, q=search_query)
for track in tracks:
tags = list(set(track.tag_list.lower().replace('"','').split(' ')))
graph.cypher.execute(addSoundCloudTrack, title=track.title, id=track.id, playback_count=track.playback_count, permalink_url=track.permalink_url)
for tag in tags:
# add ConceptNet stuff if necessary (add control so that same tag doesn't get added a billion times)
searchURL = "https://conceptnet5.media.mit.edu/data/5.4/c/en/" + tag + "?limit=100" #lower the limit for faster loading
searchJSON = requests.get(searchURL, headers = {"accept":"application/json"}).json()
graph.cypher.execute(addConceptNetData, json=searchJSON)
# connect soundcloud tag to conceptnet concept
graph.cypher.execute(addSoundCloudTag, tag=tag, id=track.id)
Recommend Some Tags!
Since the world of SoundCloud tag recommendations is surprisingly NSFW, let’s find some tag recommendations for tracks tagged with “meditation.”
MATCH (track:Track)-[a:HAS_TAG]-(tag:Tag)-[:HAS_CONCEPT]-(term:Term)
MATCH (track)-[:HAS_TAG]-(:Tag {name:'meditation'})
OPTIONAL MATCH (term)-[assert:ASSERTION]-(suggestedTag:Term)
WHERE assert.type IN ['SimilarTo','HasContext','IsA'] //trimming suggestions by type
RETURN track.title, collect(DISTINCT tag.name) AS Tags, collect(DISTINCT suggestedTag.concept) AS Suggestions
ORDER BY track.title ASC
Some sample results:

With these additional suggestions powering search results, users who prefer to call their bedtime rituals “relaxing while listening to a story” might have better luck.
Resources
Want to learn more about graph databases? Click below to get your free copy of O’Reilly’s Graph Databases ebook and discover how to use graph technology for your next project.
Share Article



Explore
Related Articles

Unlocking High-Conversion Recommendations with Graph Analytics in Snowflake

Why LeBron James Shouldn’t Drive Your Recommendations: The Intuition Behind the Jaccard Coefficient

Top 10 Graph Database Use Cases (With Real-World Case Studies)

Building a Recommendation Engine Using Neo4j Hands-On — Part 2

Building a Recommendation Engine Using Neo4j Hands-On — Part 1
