Streamlining processes with Neo4j at Glidewell Laboratories


17 min read
Editor’s Note: This presentation was given by Galit Gontar and Robert Edwards at GraphConnect San Francisco in October 2016:
Presentation summary
As a vertically integrated company, Glidewell Laboratories needs their processes and workflows to be flexible and open to innovation. However, an obscured manufacturing process was causing a variety of efficiency challenges in the developing of their personalized dental-related products.
They needed to create a workflow that would allow them to track a product through every step in the process, from receipt of an order to shipping out to a customer.
By using Neo4j, they were able to develop a workflow model with multiple uses and inherent visibility. Their workflow adopted a polyglot persistence approach, using Neo4j for the live workflow and MongoDB for versioning and metadata.
The benefits of the Neo4j workflow engine included the fact that it was generic, modular and reusable. Also, it was able to be broken down by department and accommodate both conditional workflow processes and failure steps.
Gontar and Edwards then dive into detailed examples of the workflow architecture, including both its external, consumer applications (like checking an order) and its internal, employee applications (including views for workflow designers, managers and technicians).
Full presentation: Streamlining processes with Neo4j at Glidewell Laboratories
What we’re going to be talking about today is how Neo4j helped us with streamlining processes to develop a generic workflow engine:
Robert Edwards:
You might be wondering, “What does a dental laboratory need with a workflow engine, much less a workflow engine backed by Neo4j?”
At Glidewell Laboratories, we make teeth and are one of the largest dental laboratories in the world. To give you a sense of size, 80% of the dental laboratories in the United States employ 12 people or less, and a lot of their workflows are pretty simple.
Compare that to Glidewell, which has just over 4,500 employees. Our main lab and headquarters is in Newport Beach, California, and a few miles down the road is our Irvine campus which has about seven, eight, nine buildings — and is growing. The ability to easily locate a product can become very difficult.
Teeth are very unique. Manufacturing them is almost like manufacturing a snowflake. We also offer a variety of different materials and products. For example, dentures include a crown, a bridge and an implant.
Glidewell Laboratories: A vertically integrated company to Spark innovation
We are a vertically integrated company, meaning we have our own chefs that cater our parties, masseuses and a gym — not because it’s “Silicon Valley” cool, but because our leadership believes that if you have these types of resources at your disposal, you can innovate more quickly.
And we truly believe in innovation. So beyond the masseuses and the chefs, we have our own construction crews that build our cubicles and desks. They take the spaces in each of those seven buildings and reorganize them to our specifications for whatever it is we want to do.
We also have a team of material scientists that creates and researches different materials and processes for future products. We have mechanical engineers that build the machines, such as mills that build out the blocks created by our material scientists; robotics; and ovens, which our teams use to test their theories. We also have our own CAD/CAM software teams, and CR teams for internal lab management.
We do all of this because innovation is really just a new idea, and we need to be able to test new ideas quickly. When someone comes up with an idea, we can implement that quickly and “fail fast.”
Vertical integration is great because it creates the expectation that we will move quickly. What tends to gum up the works for us is when we have to rely on human workflows.
For the most part, I love humans. But when we give them workflow decisions, we can run into trouble. For example, a subject-matter expert can create a beautiful Visio workflow diagram which they communicate to everyone — which is logistically difficult when you have seven buildings and other campus locations.
Then when you have to rely on those humans to make routing decisions, especially under pressure, it becomes even more difficult. It also limits our ability to have fine-grained variation in our workflows because it requires too much education and communication.
This is all background to explain why we pursued what we pursued with Neo4j. We are an innovation company, which is something that we pride ourselves on, so we are not afraid of new technology.
We also needed Neo4j as we move from a manufacturing company to a technology company. This is true of a lot of large companies today, including Marriott which is moving from being a hospitality company to more of a technology company in order to compete.
The challenges of an obscured manufacturing process
Galit Gontar: As Robert said, our current manufacturing process isn’t supported by an existing workflow system. We do have a workflow system, but it’s very linear, rigid and inflexible. And because each tooth is a snowflake and there is so much customization inherent in our manufacturing process, this workflow system is not representative of the reality inside our production facilities:

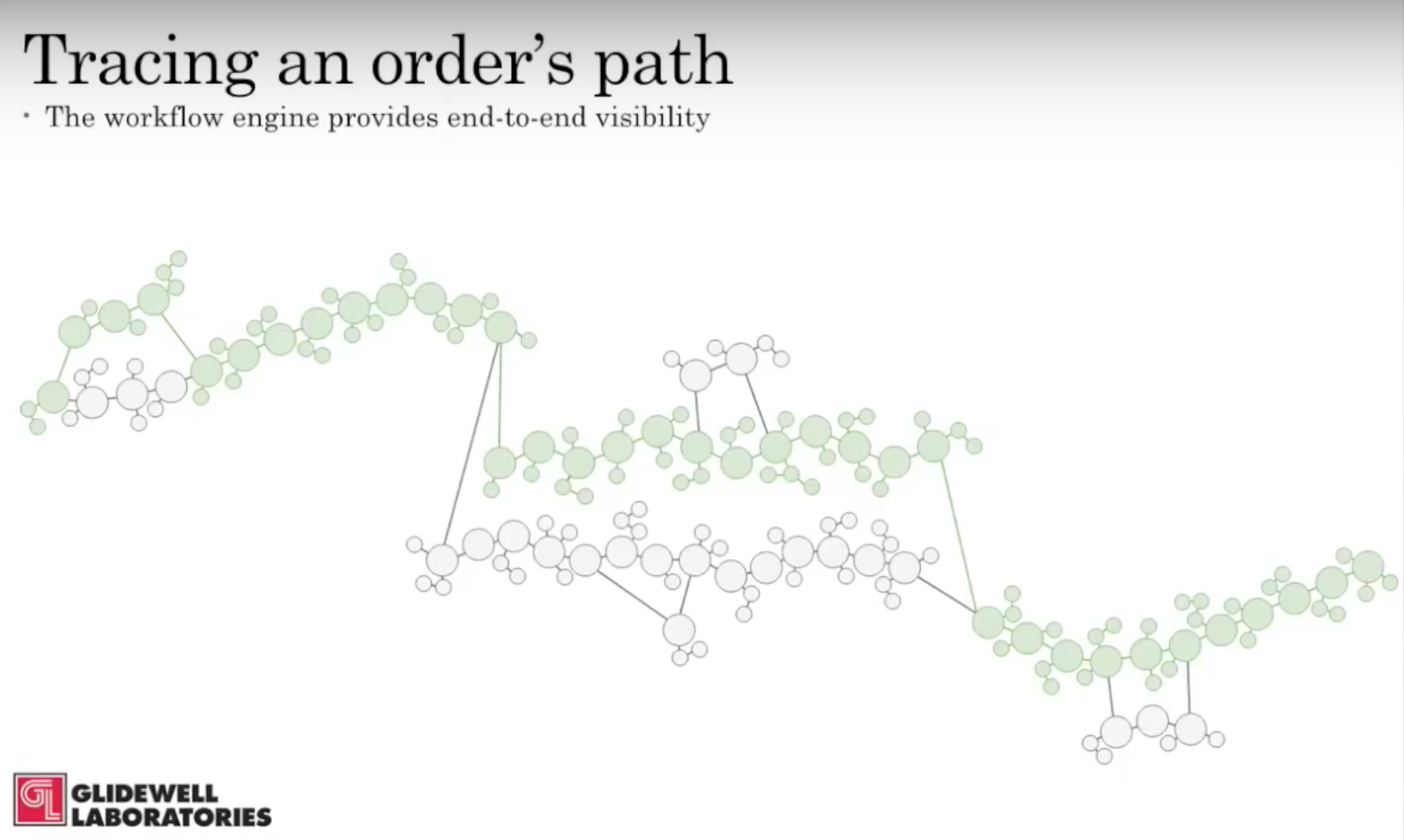
It’s really more of a timeline and the order that a product makes its way through our production process. You can see the order and production process in the receiving area, which is the point at which we receive a packet from a dentist with an order request. This ends in the shipping area, where all the teeth products get packaged together and shipped out.
In between the receiving area and the shipping area, there is this big black cloud of uncertainty that represents our existing manufacturing process. This uncertainty is a result of a workflow system that is insufficient. Our technicians have created a lot of manual Access-based sub-processes to deal with the customizations and alterations that crop up all the time.
We have no visibility into any of that, which means that even though we know there are bottlenecks and inefficiencies inherent in the system, we can’t identify or locate them. We also know there are some inherent issues with quality control due to the human decision-making component, but we have no way to combat these.
Because so much of our manufacturing processes is done manually, there is no communication between different departments. This makes it difficult to share with other departments – and our customers – what is happening in the manufacturing process.
If a customer calls a Glidewell representative and asks about the status of their order, the only information we can provide to them with confidence is when the order arrived. We have to provide an estimate for how long it will take for the order to complete, which really has no basis in reality.
There’s no way of knowing if anything went wrong or if there were any delays, so we can’t tell the customer when their order is going to be delivered. The customer also certainly can’t log in to the system to find this information.
Additionally, as I said, there are unknown inefficiencies and bottlenecks using this process. And as we grow as a company and introduce more automation into our processes, it becomes really paramount that our workflow system accurately reflects what’s going on in production. Otherwise, it’s going to become increasingly difficult for us to scale, automate and innovate.
The goals of the new workflow
Our team was tasked with developing a workflow engine via an application to compare these company workflows.
Our goals include improving the efficiency and consistency of the manufacturing process by eliminating a lot of inefficiency in the routing. It’s okay right now, but we’re hoping that to be able to eliminate a lot of errors and impose a more consistent process across all manufacturing places and activities.
We are also hoping to improve visibility both externally for customers and internally for reporting departments. For example, engineers want to check on the progression of an experiment and how an automation process is performing.
Finally, we would like to be able to make much more intelligent and data-driven decisions so that we have a real basis for modifying processes and introducing new product lines, for example.
Why Neo4j?
Neo4j is the cornerstone of the application that we built, which houses all of the actual live work data.
We switched from a relational database to Neo4j for several reasons. The first is that Neo4j provides a natural representation of a workflow; after all, a workflow is a series of connected processes.
Next, our business needs are really complex and continually evolving. The flexible data model provided by Neo4j, especially in comparison to a relational database, made it easier to accommodate these evolving needs. It also enables us to efficiently traverse connected data — without complex queries and excessive JOINs — and make real-time decisions.
It’s helpful to think about this as an expansion of the classic real-time recommendation use case:

Recommendations use the user’s data — such as their profile and system preferences — to make decisions about what to recommend to that user. Similarly, the workflow engine takes an order — which includes information about that order, who the customer is, the customer’s preferences, the technician the customer works with, etc. — and uses this information to route the customer into the most appropriate workflow.
Developing the workflow model
For building out our workflow we decided to go with the polyglot persistence model:

For all the reasons described above, we use Neo4j for the live database, and the MongoDB document store for the workflow catalog.
This includes all of the metadata, such as who created the workflow and when it was created, as well as informational related to versioning and when to activate or deactivate the workflow. When you edit a workflow, it makes more sense to get all of data in bulk because it’s less expensive than traversing the workflow in your machine.
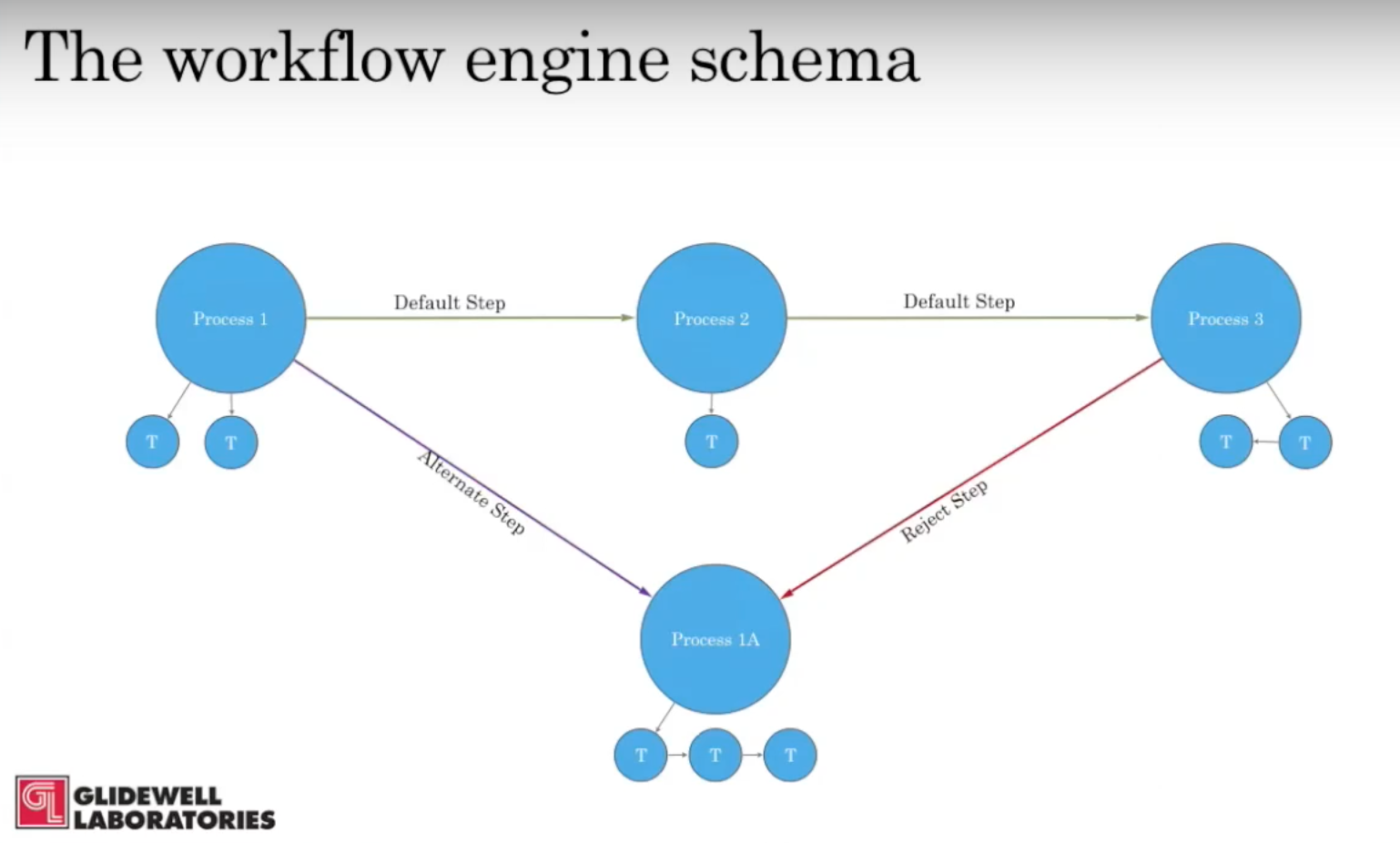
We worked with GraphAware to develop the workflow engine schema. They helped us come up with a really simple and generic workflow for our application:
The benefits of the Neo4j workflow
The workflow consists of processes, and each process has tasks. The tasks execute when a process is activated, and they can execute asynchronously — i.e. they all execute at once — or sequentially, meaning the second executes after the first one is successfully completed.
The processes can be connected by default or by some conditional set of values. For example, depending on some parameters on the item that’s on Process 1, it will either be routed to Process 2, or to Process 1A. Similarly, depending on how a task fails, that will determine the way it is routed to a failure process. As you can see above, upon rejection, Process 3 goes to process 1A.
This is very abstract for me, so an analogy I like to use is baking a cake:

You start with the dry ingredients such as flour, baking soda and salt and mix them all together. Then you move on to the wet ingredients and beat all the ingredients together with sugar. When that’s done, you combine the ingredients in a mixer to make a batter.
But what if you’re making a chocolate cake instead? Right after you add the wet ingredients, the next step is to add the cocoa powder and then to mix it. After that, you pour the ingredients into a pan and bake the cake.
But let’s say that right before you pour the batter into a pan you notice that you forgot to add the dry ingredients. You go to a conditional fail and go back to the beginning, add the dry ingredients, and then put it in the oven.
There are several benefits to this approach, the first of which is that the workflow engine is generic and can accommodate any type of workflow. It also allows us to create workflows that are modular and reusable, so rather than having to be subject-matter experts on huge processes from beginning to end, we can split up the workflow by department, have different people create different small workflows that we can reuse and chain together in a way that’s customizable.
Finally, and most importantly, our current workflow is linear — but the manufacturing of teeth is nonlinear. The fact that this workflow engine allows us to accommodate conditional workflow processes and failure steps was very important to us.
Glidewell product workflow example: A crown for a tooth
Below is an example of a real product that we manufacture with the Neo4j workflow, a crown for a tooth:
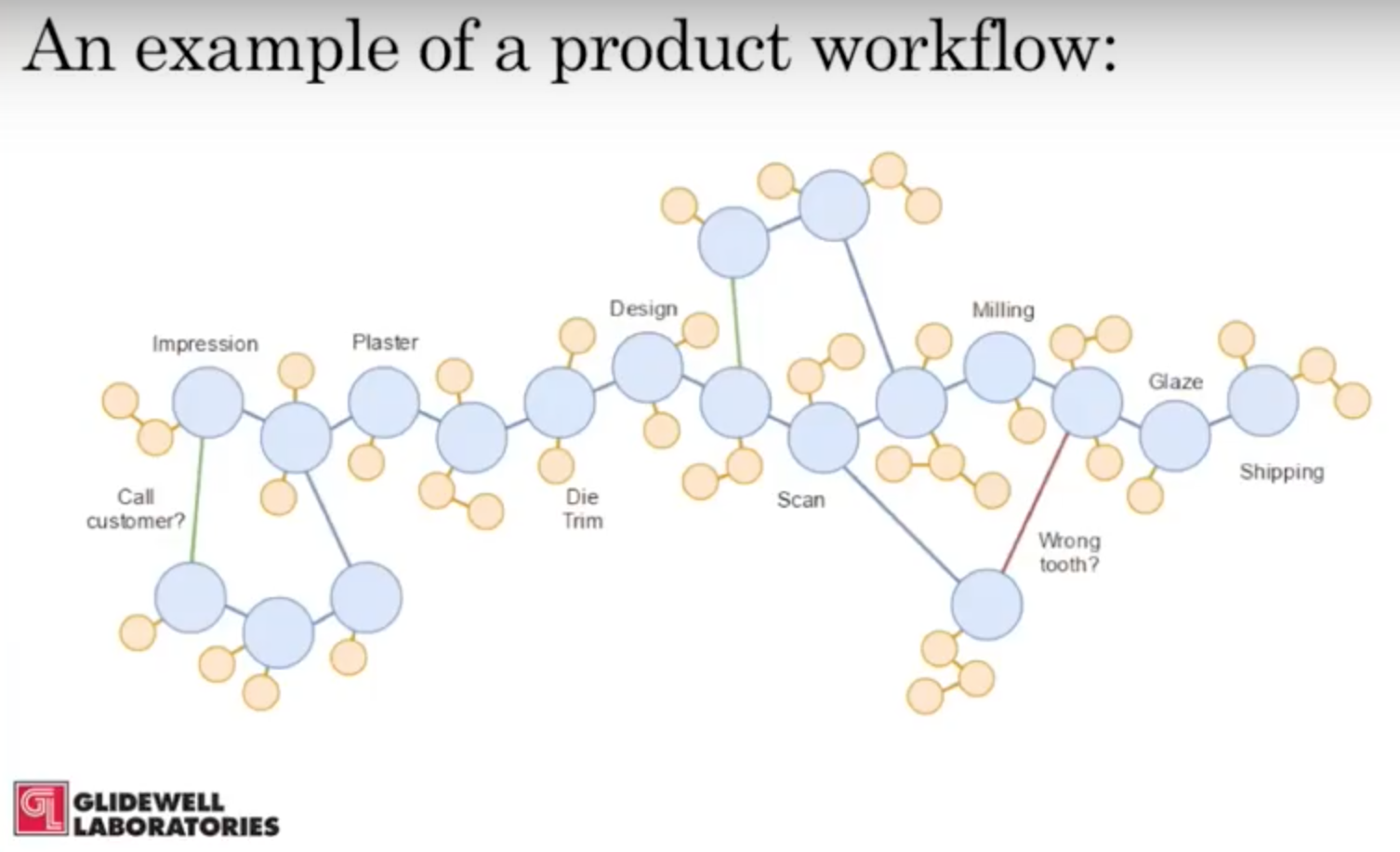
The process begins at the impression stage, when the dentist makes a model of your mouth. The impression stage technician at Glidewell receives the model and sends it through a number of steps so that we can create a digital representation of the crown mold. Then we mill an actual crown out of a certain type of material (either manually or with a robot), glaze the mold, and ship it to the customer.
But what if something different happens? What if, when we open the whole packet at the impression stage, it says to call the customer before proceeding?
Currently, a human being would see that notification and there would be a delay in the order, but we would have no way of accounting for it. If someone missed the notice, the product would get made and shipped without checking in with the customer.
With our new workflow, a technician sees that there is a request to call the customer, so it gets routed to the “Call Customers” workflow. Upon completion, it gets sent back.
And what if we build the wrong tooth? Again, in the new system it gets sent back to the appropriate stage, and recreated.
Modular and connected workflows
Our workflows are also modular and connected:
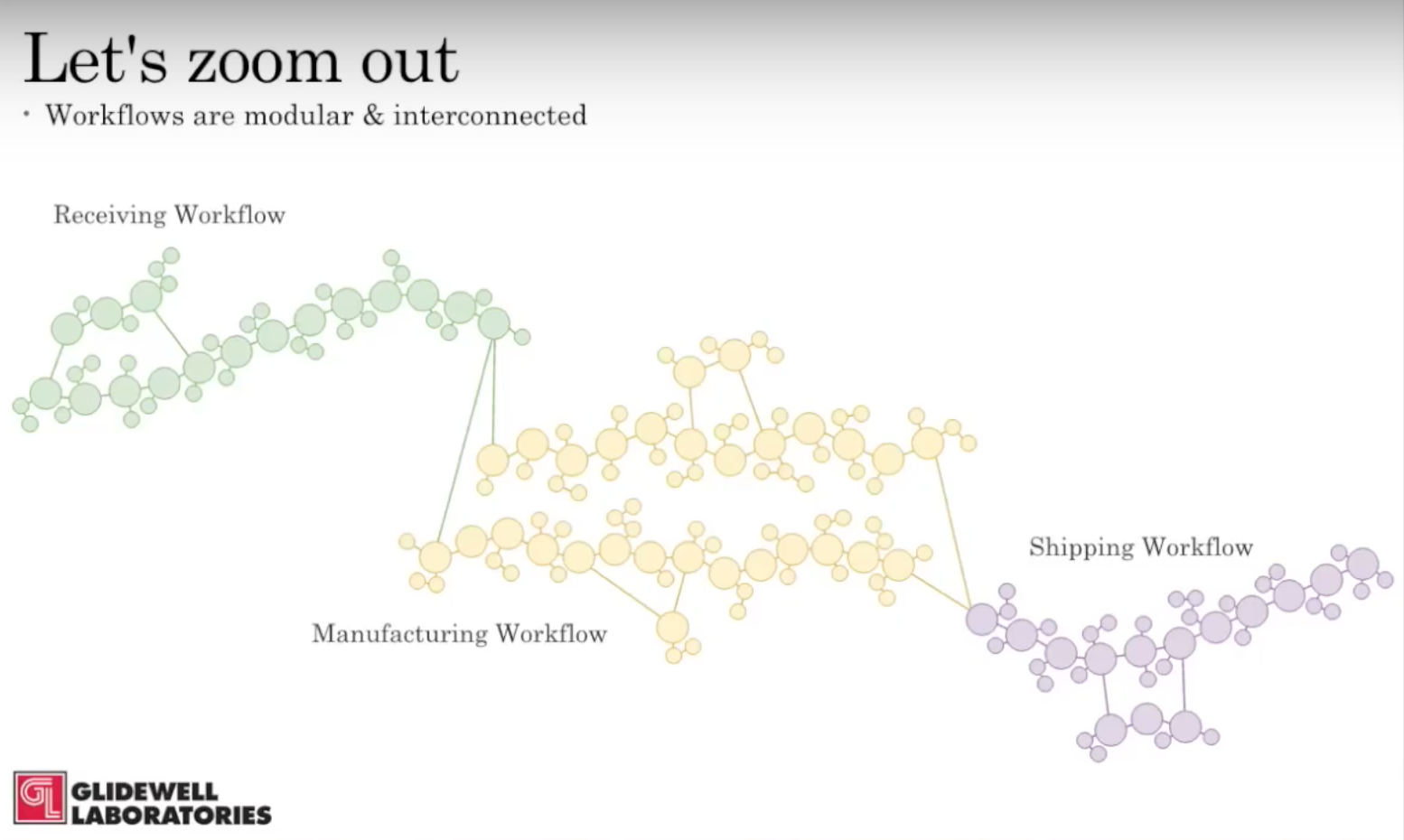
The product work is just a small part of the entire order, which also includes the receiving workflow, manufacturing workflow and shipping workflow. Using the workflow engine, we are able to create an end-to-end workflow by tying these three workflows together.
Let’s compare this new workflow with our old one:

Look how much more fine grain data is available in our new model, and how much it completes our understanding. Because we have this fine grain data, a manager on the floor or anywhere else is able to see the product’s entire path as it moves through the order.
Which alterations were required? Which processes failed, resulting in the product having to be sent back or be redone? Who was in charge of this process every step of the way, and how long did each of those processes take?
While some of this information won’t be useful in some cases, we’re also able to filter the data to make it more useful and comprehensible for different users.
A generic workflow engine with multiple uses
In reality, we are still in the early stages of putting our workflow engine into the production process. In the meantime, because the workflow engine is so generic, we have been able to implement it in a completely different way inside our application deployment process:

When a user says “deploy this Docker image,” that initializes the workflow. It pushes the image to AWS, goes through some checklist steps, goes through some redeployment stuff, deploys the item and confirms with the user that the item has been deployed.
We were able to do this with no core change to the workflow engine – only by changing the kinds of data and the tasks that the workflow engine performs. This has allowed us to make our deployment process a lot more flexible and easier to replicate across different environments.
The workflow architecture
You can see the architecture on the left is the workflow creation part, and it culminates in the Neo4j graph which houses all the live work data:
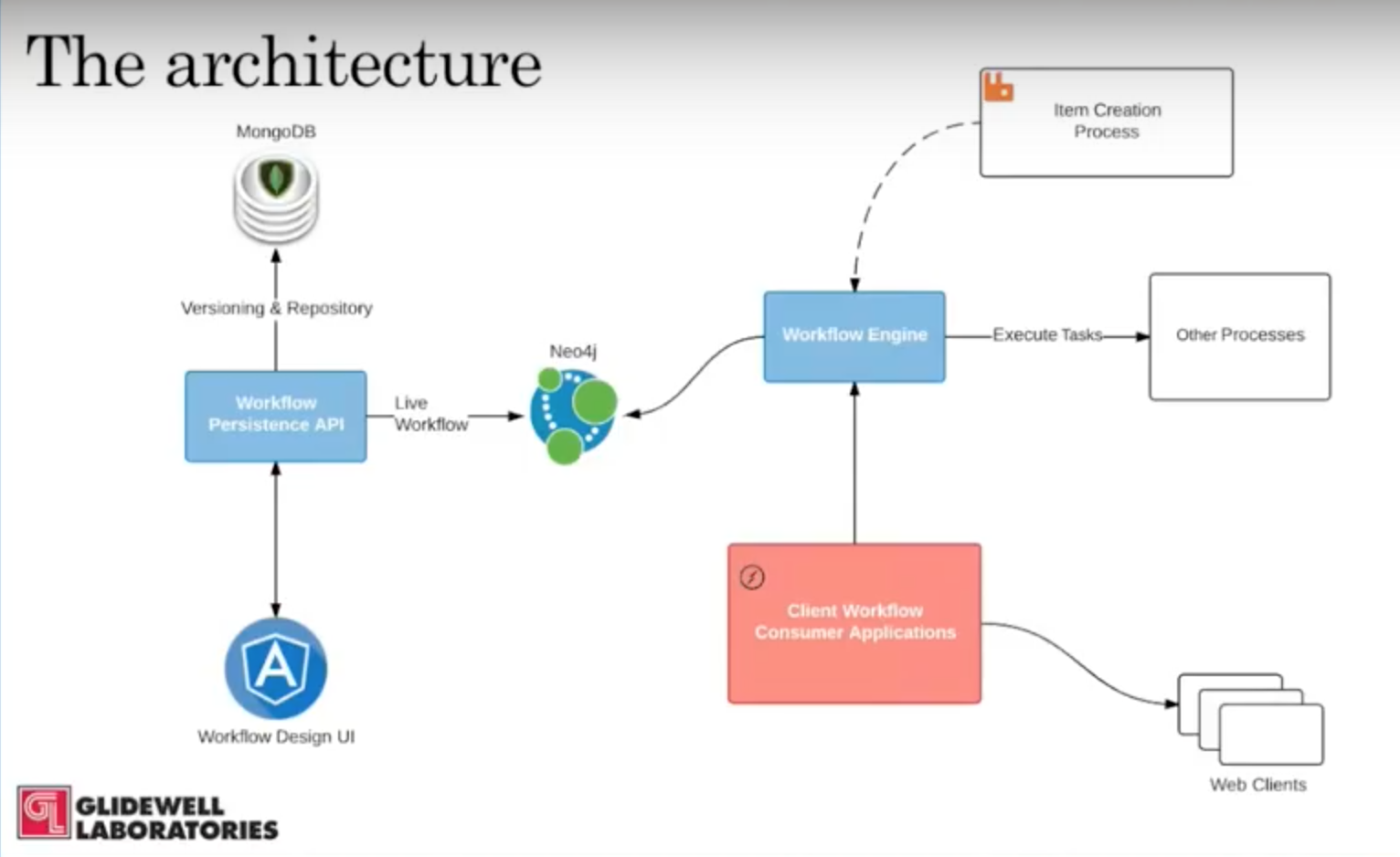
On the right, you can see actual workflow services, and the blue Workflow Engine service has all of the business logic for the workflow. It accepts items from a considerable set of processes, pushes those items into the Neo4j graph, sits back and determines which process and tasks are active and then executes those tasks.
The task itself contains its own execution instructions, gathers the results and sends them back and routes the item to the workflow. A lot of our clients can have some connection to the workflow engine to correct the appropriate subset of this data as the item is routed through the workflow.
The application: Unique user views
Below are some screenshots of our current application. This is a page for designing our workflow, with a list of all the products on the left:
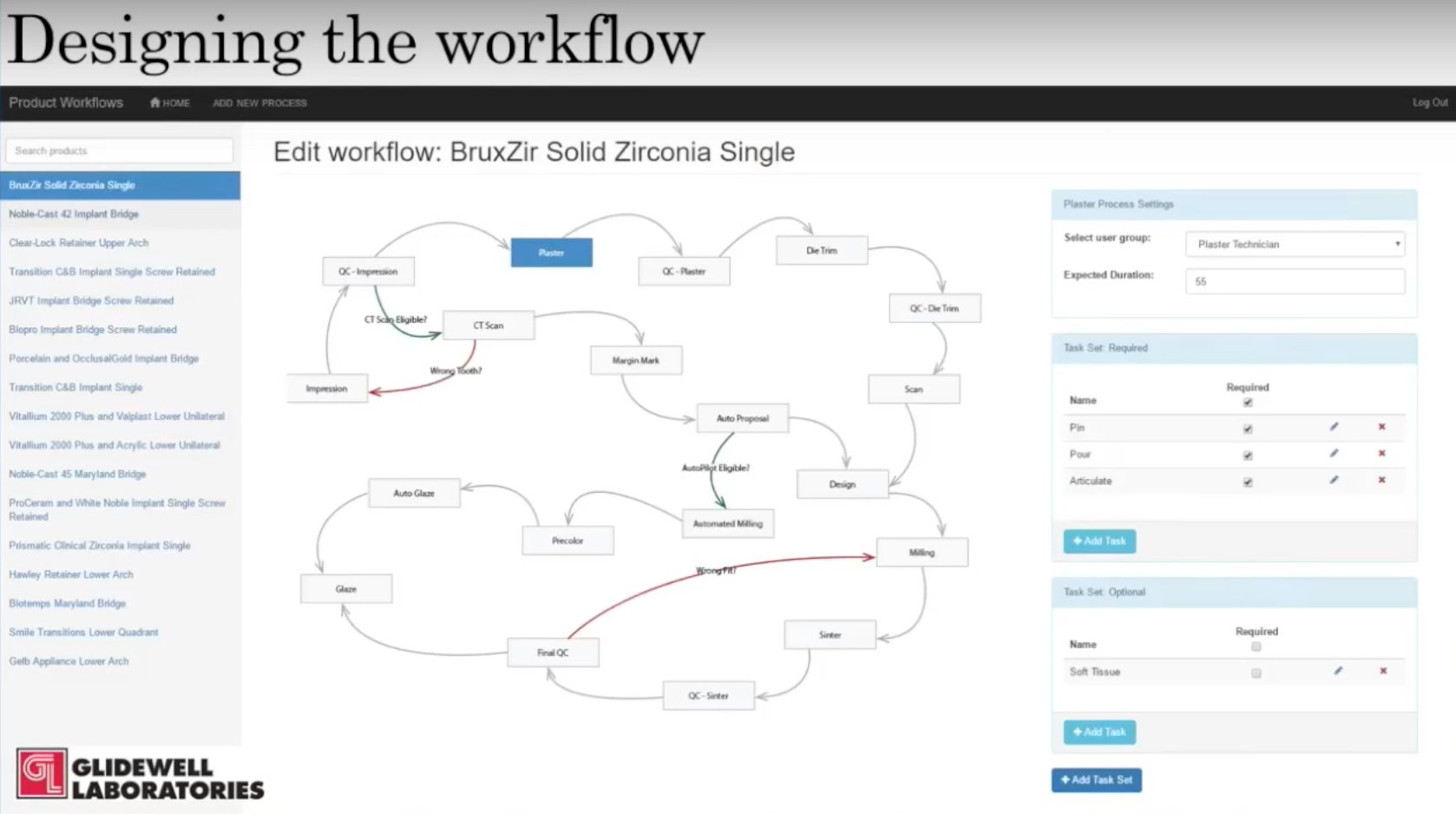
There’s another page that lists all the processes, and you can drag in different processes and assign task sets. Each task set is assigned asynchronously, while the tasks inside the task will be sequential.
Below is another screenshot example. On the left is the list of pending items, which have completed their previous workflow step, have been routed to their next workflow step, and now need to be assigned to a specific user:
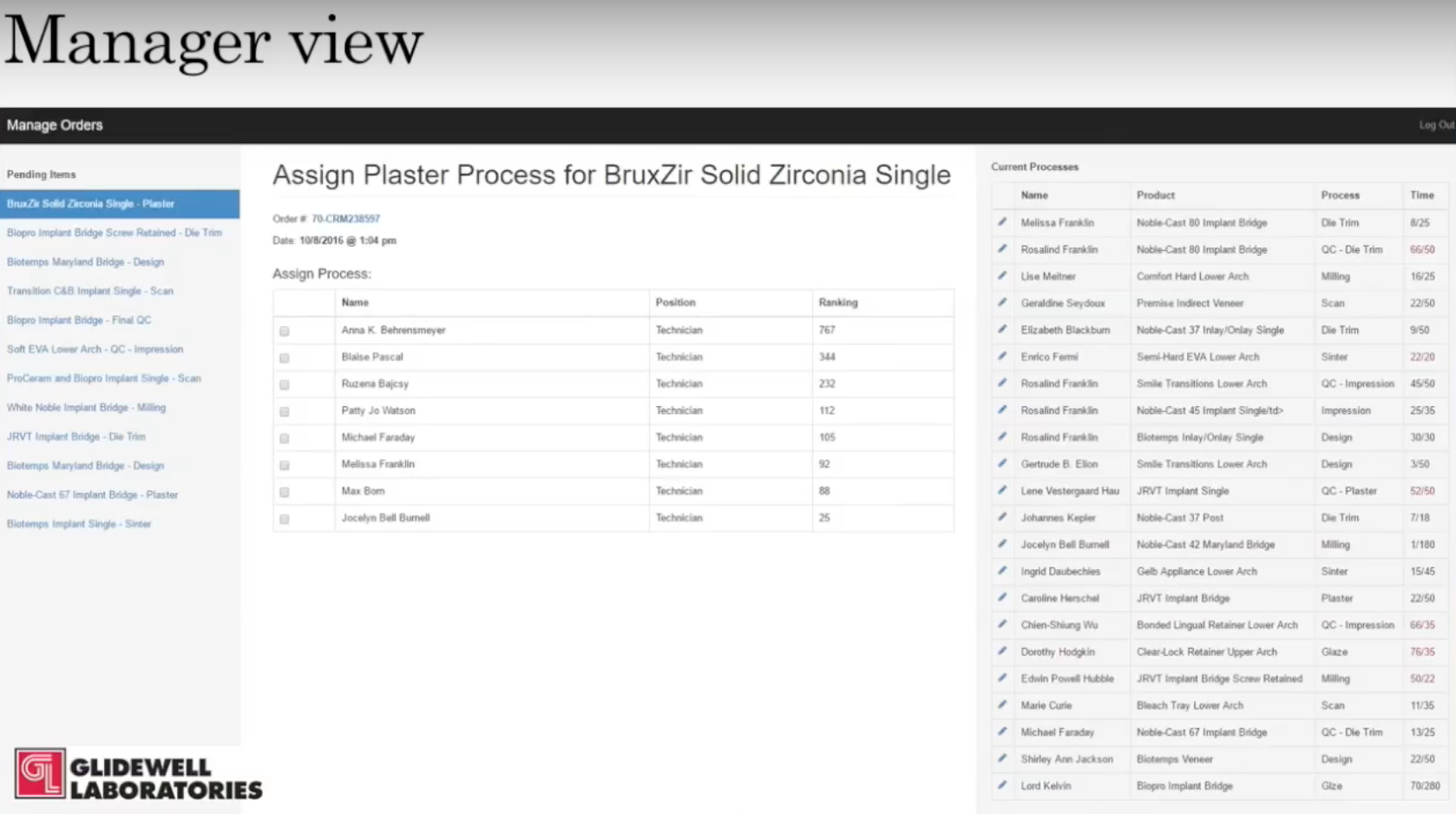
In the middle you see a list of all of the users who are qualified for this specific step. All the manager has to do is check one and it will automatically be rerouted to their work program.
We can see the current processes on the far right, so the assistant manager can see all of the technicians, what product they’re working on, what process in that product they’re working on, and how much time they have spent divided by much time we thought this process would take.
And below is the technician view:

We can see the technician and the pending items they have on their desk right now, and you can see they can submit any missing tasks for that last process. They can mark the task as completed or they can mark it as rejected, and then they have to come back with a rejection reason and move it to a different process.
Our technicians are paid per item they produce, and now we are able to track how many items they have completed in order to display how much they will be paid.
As I mentioned above, gathering data is a crucial component part of this application. Below is an example dataset for demonstration purposes:

We are able to use an aggregate of all our work to show the executive products, the recording process, how many orders we received today, how many products are currently in production, how many products have been completed today divided by how many products we would like to complete for today, etc.
The important takeaways when building your own workflow process is that generic solutions are incredibly useful, and do your best to create modular processes so that they can be reused throughout your workflow.
Share Article



Explore
Related Articles
Neo4j Named “One to Watch” in Snowflake’s 2026 Modern Marketing Data Stack Report

Supply chains don’t fail at the node. They fail at the connection.
What’s invisible in your supply chain could cost you

Unlocking high-conversion recommendations with graph analytics in Snowflake
