The impact of graph-powered business leader social networks

CEO and Founder, Kantwert
7 min read

Editor’s Note: This presentation was given by Tilo Walter at GraphConnect Europe in April 2016. Here’s a quick review of what he covered:
–
What we’re going to be talking about today is how companies can use the power of graph databases to leverage business relationships and obtain new customers:
Why do so many companies create so little value from their contacts? Many of you probably work in a company that uses a customer relationship management (CRM) system. But you probably aren’t able to easily glean simple insights into those relationships.
For example, is the CEO of a customer also on the supervisory board of a different company? This is incredibly easy to determine, so why don’t more companies do it?
Using graphs to leverage and navigate business leader networks
The next question is, what if companies could systematically leverage their extensive business leader social networks? Most companies are highly interlinked and intertwined with their customers, which provides the opportunity for a lot of meaningful insights.
Consider the following simple use case:
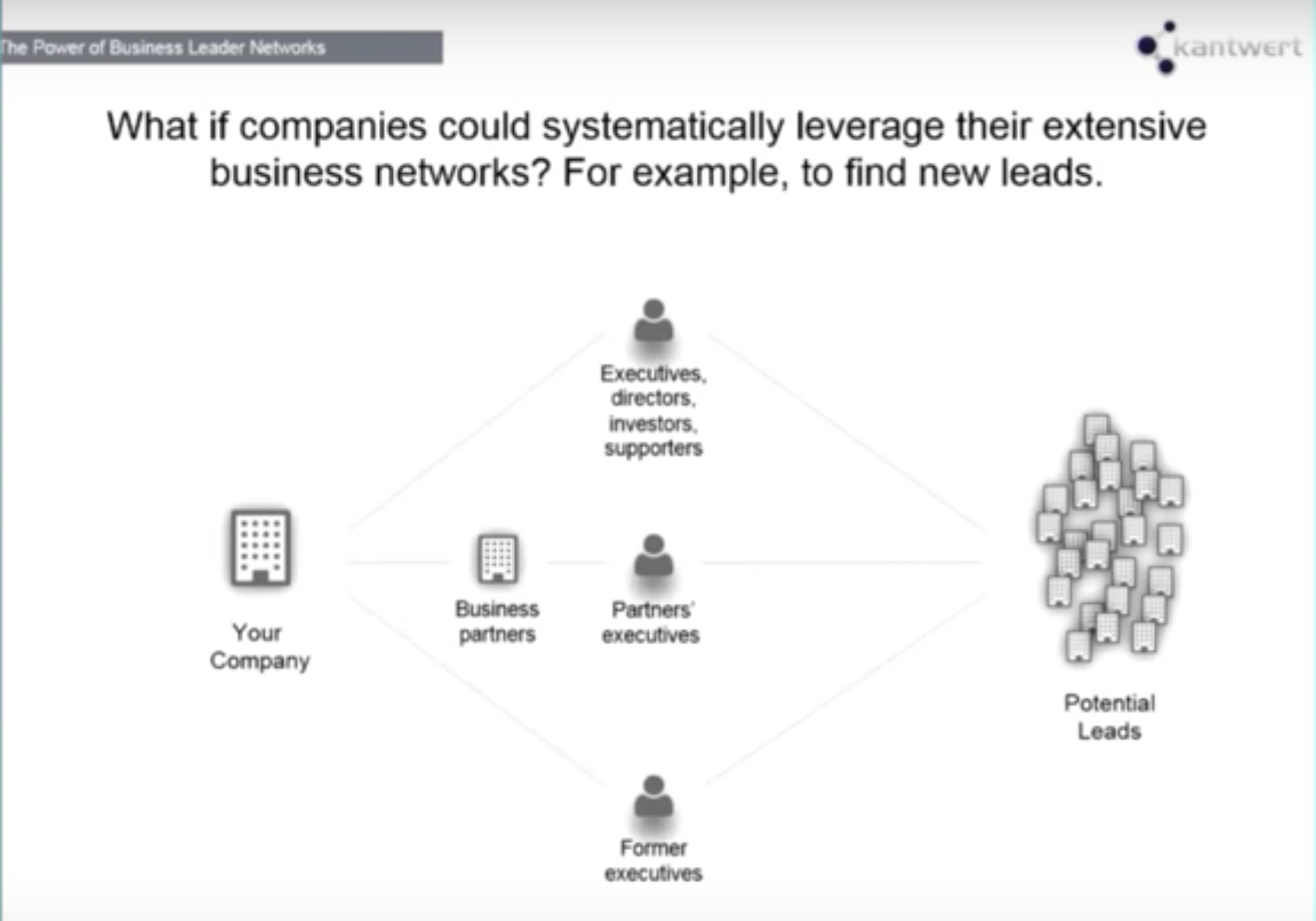
The CEO of one customer could potentially introduce you to another company in a “warm introduction,” which often times makes companies much more successful in obtaining new clients. We’ll revisit this later in the post when we review how to do this from a technical point of view.
The next question is, what if navigating complex business leader social networks to obtain new clients were as easy as finding a hotel online? From a customer perspective in the B2B business, when regular companies such as Neo4j try to find new customers, there’s no simple solution available. The company buys addresses for mailings or sends employees to conferences.
And this hasn’t progressed much over the last 10 years. Now people use social networks like Facebook and Twitter for some sales activities, but it’s difficult to measure how effective they are, making it not the best solution for B2B businesses.
Kantwert and Neo4j: a solution for winning new customers
This is exactly why we started Kantwert. We wanted to change this piece of how companies generate business by developing a European business and decision-maker network. This includes all companies and people within those companies, such as representatives of the first and second management levels, shareholders, and the supervisory board. And with this tool, we’re able to show how all of these groups are interlinked and dependent on each other.
This is extremely helpful in searching for fraud ring patterns, but also for sales and marketing purposes. This is because our product allows companies to leverage the effectiveness of sales activities by using a graph-oriented approach to handling customer data.
Below is an example from my former company:
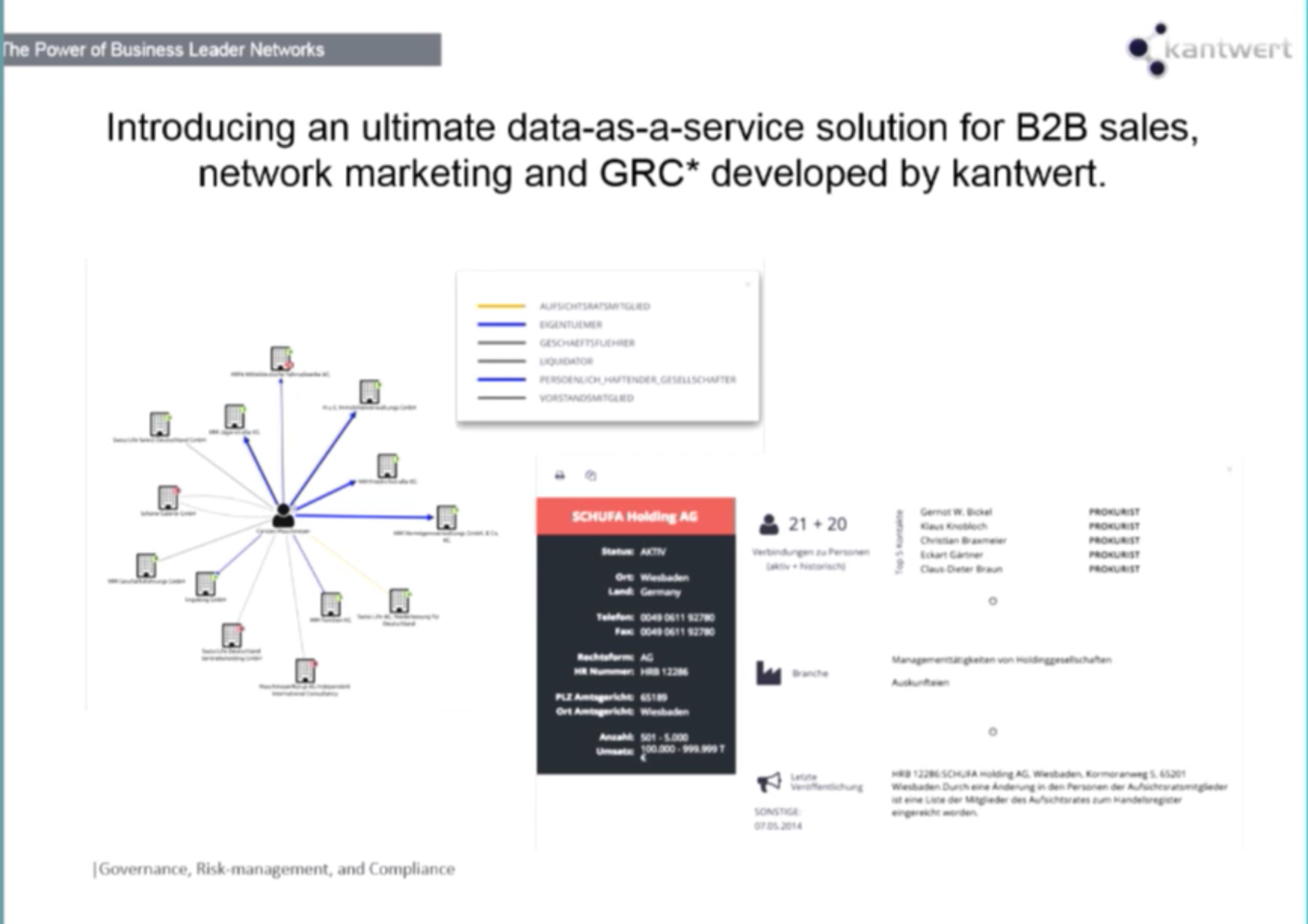
If you combine data from the nodes and node relationships, you get simple Cypher queries that provide network insights. We use Neo4j to show these relationships and dependencies between customers, and you can then click through all of the relationships using KeyLines graph visualization to show this network.
Data Architecture
When we first started the project, we were working with Oracle RDBMS, which had two main limitations: it was very slow, and finding the relationships between company entities was very time-consuming.
To address these issues, when we set up our new system we used the column-family store Cassandra to ensure fast write operations from the database. There are days when we import 10,000,000 datasets, which requires a really fast database, and obviously Oracle is too slow for that. We also use Neo4j and then to search the Neo4j database using Apache Solr.
This Neo4j, Cassandra and Solr architecture was the foundation of our application at the beginning, and we’ve continued adding to the front-end using a variety of systems that will be covered below.
The Advantages of Importing Data from Multiple Sources
Currently we only have public data from Germany, but we’re expanding to Poland, Austria, Switzerland and the UK. In Germany, we use registered trade data from the UK Companies House, which allows us to import essentially the CV of a company – its address, leadership, as well as the career trajectories of people within the company – all of which is published information. We crawl the text and update our data every 15 minutes by parsing the data and importing it into the system. That’s the main source of our data.
We also pull public data from decision-makers, such as government, trade associations and lobby associations with all of their associated boards – as well as from health insurance companies and universities. The commercial registers provide the annual reports, press releases and official websites of all the companies in Germany.
Any data that can’t be pulled from crawlers is input manually, which mostly includes data from individual websites that require an individually adapted parser, and it wasn’t economically feasible to set up crawlers for these cases. The key to our database is that we have so many sources of information.

We’ve incorporated social network algorithms to determine relationships between people in the database. For example, if two people worked together on the management board of a company at the same time, they probably know each other. And the management board almost always knows the members of the supervisory board, who then likely know their counterparts at another company.
We created a rule that limits these assumed associations to five degrees of separation. This social network is now the biggest social network of decision makers in all of Germany.
To ensure quality control of the manually input data, we have two people input the same data – if it’s the same, we assume it’s correct. Most is copied and pasted directly from websites. We also have a data team create random controls to ensure we have good data.
We’ve landed a number of the biggest companies in Germany – such as Deutsche Bank, Commerzbank and Deutsche Post – because they all want more data insights.
Below is the data architecture I went over earlier:

As mentioned above, we use Cassandra as our column-family store, Solr for searching personal and company data, Neo4j to perform graph database operations, and the PostgreSQL relational database for data quality analysis. We recently integrated Apache Spark and will likely use this program to replace Postgres, which only does a weekly export for quality analysis and reporting.
We have a highly decoupled architecture, meaning we have an NQ message broker that is responsible for shipping the data to all of our different databases. And then we have decoupled microservices in their own container instances within Apache Tomcat where our application is divided into multiple small parts.
This architecture was based off of all our learning experiences from our past project – which was not optimal, not decoupled, not fast and not flexible. And at the moment we’re still happy with this type of architecture.
Demo: Integrating public and customer data
In social networks like ours, it becomes even more powerful if our public data is integrated with the customer data. This is very important.
In the demo below, we’ll show how customers are integrating data into their systems. I’ll be logged in as a customer and will show real examples of how our customers use Kantwert, where they are currently uploading 10,000 potential leads that they haven’t been able to land.
They’re hoping to find out how to bypass the single entrance point to the company and get a foot in the door a different way:
I think graph databases offer a new perspectives and insights on the same data. We love this topic and I’m sure there will be much more use cases around business leader social networks using graph database in the future.
Share Article



Explore
Related Articles


Hey LLM, you’re using OPTIONAL MATCH wrong. Here’s the Cypher that actually works.



