
This Week in Neo4j – Analyzing PostgreSQL metadata, Similarity Algorithms Deep Dive, Decision Streams

Developer Relations Engineer
4 min read

Welcome to This Week in Neo4j where I share the most interesting things I found in our community over the last seven days.
This week I had fun with the online meetup on similarity algorithms with Tomaz Bratanic. I came across a great post written by Adrien Sales showing how to analyse PostgreSQL metadata using Neo4j and learned a neat approach to ingesting data into Neo4j using Kafka Streams and GraphQL.
The Neo4j DevRel team were out on the road again this week. Karin and Michael travelled to Berlin for a Neo4j meetup, and Karin also presented at the Data Natives conference. Don’t forget to say hi if you see us at any events you’re attending.
Featured Community Member: Pat Patterson
This weeks featured community member is Pat Patterson, Technical Director at StreamSets.
Pat Patterson – This Week’s Featured Community Member
I first met Pat about 18 months ago when he presented Visualizing and Analyzing Salesforce Data with StreamSets and Neo4j at our online meetup.
Since then Pat has presented at several meetups, and most recently presented Ingesting Data into Neo4j for Master Data Management at GraphConnect NYC 2018. Pat was also interviewed for the 5 minute interview series.
On behalf of the Neo4j community, thanks for all your work Pat!
Online Meetup: Neo4j Similarity Algorithms and How to Use Them
This week on the online meetup, Tomaz Bratanic showed us how to use the similarity algorithms recently added to the Neo4j Graph Algorithms library.
You can also learn more about the algorithms on Tomaz’s blog.
Building a Code One Session Recommendation Engine using Neo4j
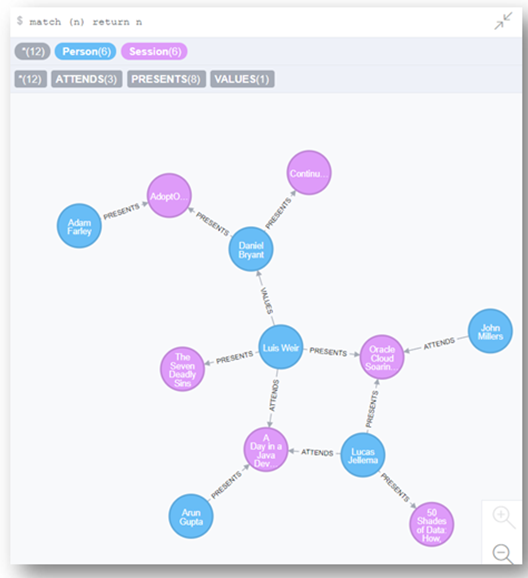
I enjoyed a blog post written by Lucas Jellema in which he builds a session recommendation engine for conferences like the recent Oracle CodeOne conference.
Lucas shows how to build such a system using both relational and graph approaches, and compares and contrasts the resulting SQL and Cypher queries.
You can find all the code shown in the post in the conference-recommendation-engine-in-graphdb GitHub repository.
GraphQL Based Neo4J Ingestion

Naren Chowdary wrote a blog post showing how to use GraphQL as an ingestion layer for importing data into Neo4j.
Naren builds a data pipeline that load an airlines and airports dataset into Kafka Streams, which is then consumed by a Spring Boot powered consumer that sends the data to Neo4j via the GraphQL plugin.
The code for the post is all available in the neo4j-graphql-streams-demo GitHub repository.
Spatial support in neomodel, Neo4j Seed File, FileMaker → Neo4j

- Athanasios Anastasiou released a first stable iteration of neomodel’s Geosptial data type handling. If you want to test it out you can get it from the feature_spatial_datatypes GitHub repository.
- Maddie Jennings Shepard shared a seed file for bootstrapping a Javascript based Neo4j project.
- Akhil Sharma explains how to build a Firebase NodeJS application that uses Neo4j to make recommendations.
- Joris Aarts has started writing a series of posts showing how to integrate Neo4j in a FileMaker solution. There’s also a video showing how to import FileMaker data into Neo4j.
Dynamic Rule Based Decision Trees: Decision Streams
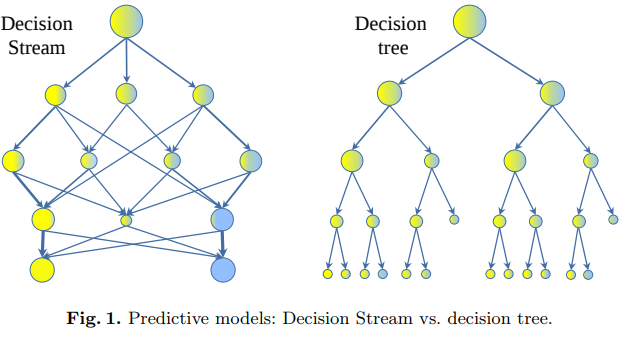
In part 4 of Max De Marzi‘s series of blog posts about decision trees he shows how to build a decision stream. A decision stream is similar to a decision tree, but it allows nodes to follow a path based on multiple options and may go down more than 1 level.
Max shows how to use some procedures he built that call a Clojure implementation of the decision stream algorithm, which was written as an alternative to random forests that are often used in machine learning pipelines.
Analysing PostgreSQL metadata using Neo4j
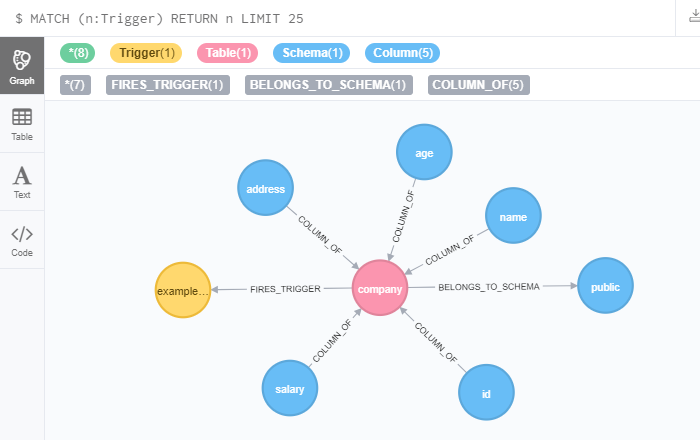
In Digging and mining datas structures : extracting INFORMATION_SCHEMA from Neo4J & APOC Adrien Sales shows how to use the graph to analyse the meta data of a PostgreSQL database.
Adrien imports system data from PostgreSQL using APOC’s LOAD JDBC procedure, before showing how to write Cypher queries to explore triggers, database objects, and more. He also shows how to stream the data into visualisation tools to explore the data further.
Next Week
What’s happening next week in the world of graph databases?
| Date | Title | Group |
|---|---|---|
|
November 29th 2018 |
Iterative modeling of corporate resources in a rapidly growing company |
Tweet of the Week
My favourite tweet this week was by Neil Harbinger:
Getting ready for #kerrydatascience with #neo4j pic.twitter.com/fidHmolkf4
— Neil at Harbinger (@neilharbinger) November 21, 2018
Don’t forget to RT if you liked it too.
That’s all for this week. Have a great weekend!
Cheers, Mark
Share Article



Explore
Related Articles

This Week in Neo4j: GraphRAG, GraphAcademy, Knowledge Graphs, Symfony and more

This Week in Neo4j: Certification, Developer Tools, GraphRAG, Knowledge Graphs and more

This Week in Neo4j: Certification, Graph Analytics, Agentic AI, Knowledge Graph and more


