
This Week in Neo4j – Automate Neo4j Deploys on AWS and GCP, BBC GoodFood Graph Online Meetup, APOC Winter Release and Documentation Refresh

Developer Relations Engineer
4 min read

It’s been another fun week in the world of Neo4j, the highlight of my week being the online meetup where Lju and I had a great time showing off the BBC GoodFood graph that we’ve been working on. There were lots of questions about graph modeling, so be sure to check that out.
Andrea Santurbano continues with his series of posts about integrating Neo4j with Kafka, and If you’re deploying to the cloud this is your lucky week as David Allen shares scripts for automating the whole process on AWS and GCP.
And if that wasn’t enough, we also had the winter release of the APOC library, and Luanne Misquitta shows us how to build and query a software dependency graph.
Elsewhere, our colleagues in marketing land are halfway through GraphTour EU, having already visited Milan, Tel Aviv, Amsterdam and Madrid. If you want to see what’s been going on, our colleague Eva has been sharing pictures and videos from the events on Instagram.
Featured Community Member: Calin Constantinov
This week’s featured community members is Calin Constantinov, SAP Hybris Java Technical Lead and Neo4j Specialist.
Calin Constantinov – This Week’s Featured Community Member
Calin is a PhD at University of Craiova in Bucharest, Romania. He is a graph-enthusiast and a Neo4j Certified Developer. Last year, during Graph Tour in Europe, Calin submitted himself as a speaker for our community events and was booked at Bucharest Big Data as a presented on ‘Uncovering Hidden Insights through Graphs’.
To our surprise, we discovered this wasn’t his first presentation when we found this video (it’s in Romanian) of his presentation at iQuest on ‘Socially Enhanced Data Analysis’ earlier that year.
As you would expect, Calin didn’t stop spreading graph-love. He continued his advocacy and involvement in the community. His passion of graphs and wanting to help others learn recently got him accepted to give a training session on Neo4j at Big Data Romania. We’re grateful to have you in the community, Calin. Thank you for sharing your knowledge with others.
How to ingest data into Neo4j from a Kafka stream
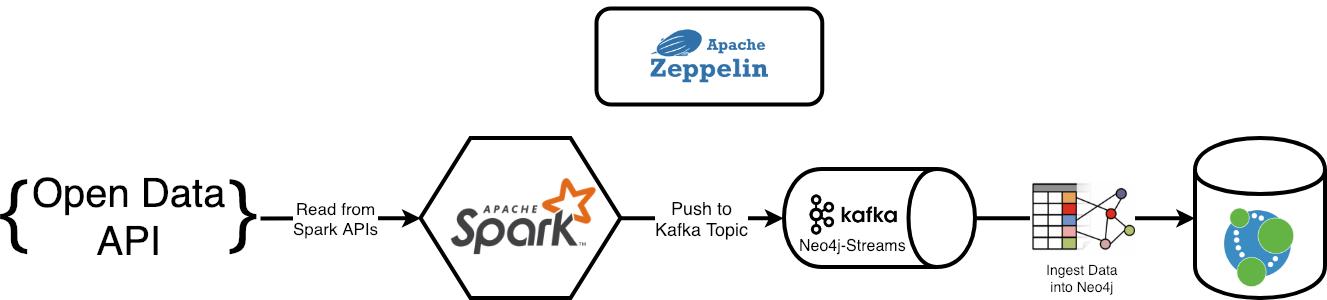
In the 2nd article of his series about leveraging Neo4j Stream, Andrea Santurbano explains how to bring Neo4j into your Apache Kafka flow by using the Sink module of the Neo4j Streams project in combination with Apache Spark’s Structured Streaming Apis.
This is all done using an Italian Ministry of Health dataset, and Andrea provides a Docker compose template to help others quickly get up and running.
Lean Dependencies- Reduce Project Delivery Chaos with Graphs
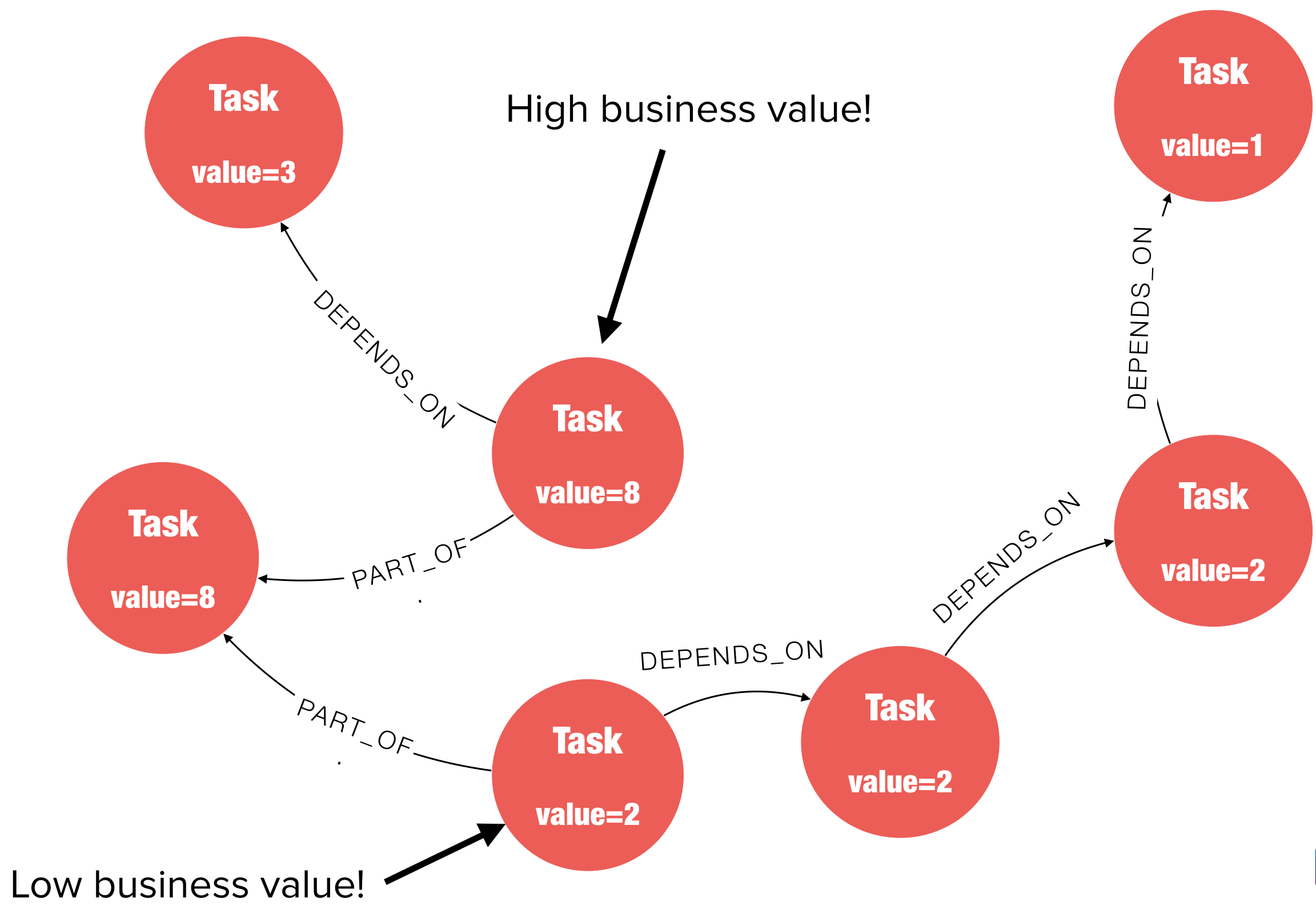
Dependency management is a very common use case for graphs, and in her latest post Luanne Misquitta shows how we can build a dependency graph of tasks in a software project.
Once the graph is created, Luanne describes the types of problems it can solve, including task prioritisation and evaluating the impact of tasks on the rest of the project.
How to Automate Neo4j Deploys on AWS and GCP

David Allen has started writing a series of blog posts on automating Neo4j deploys on cloud platforms.
David shares shell scripts that automate the whole process. These are especially useful for when you want to integrate Neo4j into your CI/CD pipeline and be able to create/destroy instances temporarily, and also just to spin up a sample instance.
Building the BBC GoodFood Graph
In this week’s Neo4j Online Meetup, Lju Lazarevic and I showed how to build a graph of BBC GoodFood recipes.
In the talk we showed how to model the raw data as a graph, how to import it using the APOC library, and after showing some basic queries, wrote a more complex one that found recipes that didn’t contain any of my allergens.
APOC Winter Release and Documentation Refresh
This week we had the winter release of the popular APOC library, which contains a new procedure to clone and re-anchor sub graphs, functions for fingerprinting graphs, as well as a function to allow inspection of free storage.
My favourite part of this release, however, is the brand new documentation pages. Functionality is now grouped by type, so no longer will you need to search across the whole page to find what you’re looking for.
You can install the latest version of the APOC library from the Neo4j Desktop application.
Tweet of the Week
My favourite tweet this week was by Lalu Erfandi Maula Yusnu:
I was giving lecture about “Introduction to Graph Database with Neo4J and Python” at software developer community in Lombok Dev.
Here is my material link:https://t.co/u3nswXWpKz#neo4j #graphdatabase pic.twitter.com/wPCANfPXc7
— Lalu Erfandi Maula Yusnu (@nunenuh) February 18, 2019
Don’t forget to RT if you liked it too.
That’s all for this week. Have a great weekend!
Cheers, Mark
Share Article



Explore
Related Articles

This Week in Neo4j: Certification, Developer Tools, GraphRAG, Knowledge Graphs and more

This Week in Neo4j: Certification, Graph Analytics, Agentic AI, Knowledge Graph and more



