
This Week in Neo4j – Crime Investigation Sandbox, GraphQL to Cypher transpiler for the JVM, Exploring Yelp with Graph Algorithms

Developer Relations Engineer
4 min read

Welcome to This Week in Neo4j where I share the most interesting things I found in our community over the last seven days.
This week Will and I previewed the Applied Graph Algorithms training, Joe Depeau launched the Crime Investigation Sandbox, Michael launched a GraphQL to Cypher transpiler for the JVM, and more!
Featured Community Member: Joe Depeau
This weeks featured community member is Joe Depeau, Senior Presales Consultant at Neo4j.
Joe Depeau – This Week’s Featured Community Member
Joe has been part of the Neo4j community for just under 18 months, and has quickly become one of our most popular webinar presenters.
He’s presented on a wide range of topics, including building a recommender system, modelling complex financial instruments, modeling financial risk, GDPR, fraud detection, and of course POLE investigations. A common theme across these presentations is that they have excellent demos, often showing off Neo4j Bloom – a visualisation tool that we released earlier this year.
This week Joe launched the Neo4j Crime Investigation Sandbox, which has a built in tutorial showing how to do POLE investigations on a public dataset from Manchester, UK. You can launch the new sandbox from neo4j.com/sandbox.
On behalf of the Neo4j community, thanks for all your work Joe!
Online Meetup: Exploring Yelp with Graph Algorithms
In last week’s online meetup, Will Lyon and I gave a sneak peak of the Applied Graph Algorithms course that we’ll be launching soon.
We’re still putting the finishing touches to the course, but keep an eye on the Neo4j community forum page as we’ll announce the launch there.
TagOverflow: Correlating tags in StackOverflow
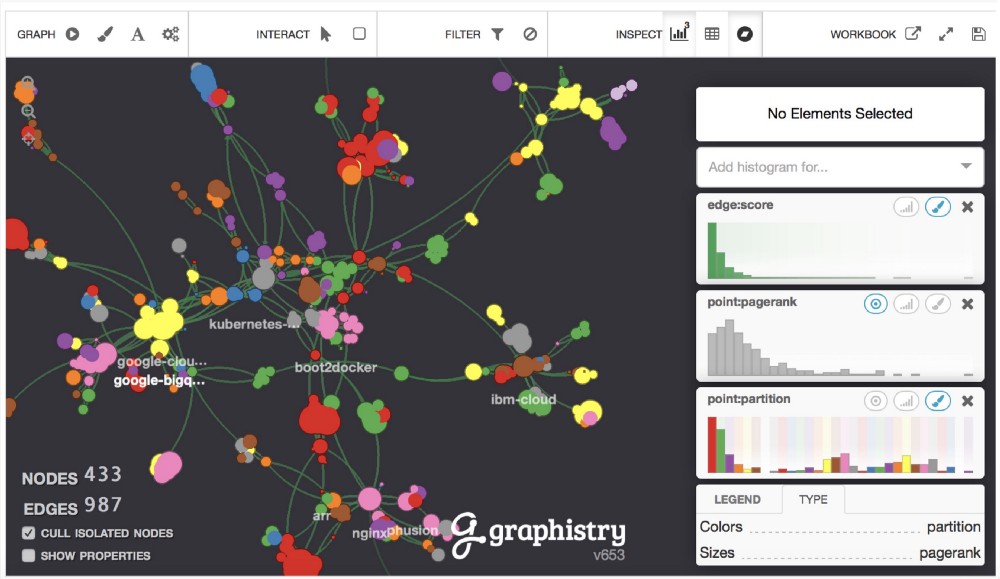
Michael Hunger wrote a blog post showing how to use the Neo4j Graph Algorithms to correlate and categorize the tags of StackOverflow based on the questions they are attached to.
Michael starts by building a tag similarity graph using the Jaccard similarity algorithm, and then clustering and centrality algorithms over the resulting graph to gain further insights into the data.He concludes by using Graphistry and NeoVis.js to visualise the output of the algorithms.
Create a Data Marvel: Hydrating the Model

In the third post in Jennifer Reif series of posts showing how to build a full stack application with Spring and Neo4j, Jennifer shows how to use the APOC library hydrate the model by pulling in more data related to comics, series, and events.
The data returned by the Marvel API isn’t completely consistent and therefore acts as a perfect example of the types of problems that we’ll experience when working with real life datasets.
Getting started with Neo4j – Building a follow system
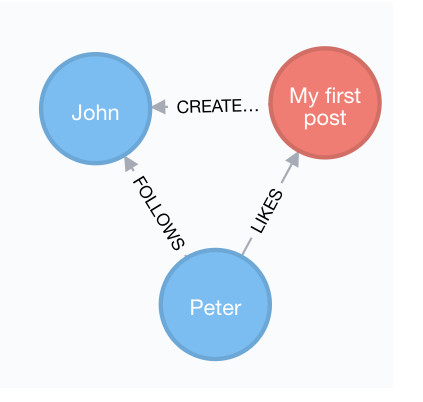
Pedro Mendonça wrote a blog post showing how to build follow system for a social network in Neo4j.
Pedro explains how to build a graph model for such a system, creates some sample data, and then shows how to write queries to find a user and their posts, as well as finding recommended posts.
neo4j-graphql-java: GraphQL to Cypher transpiler for the JVM
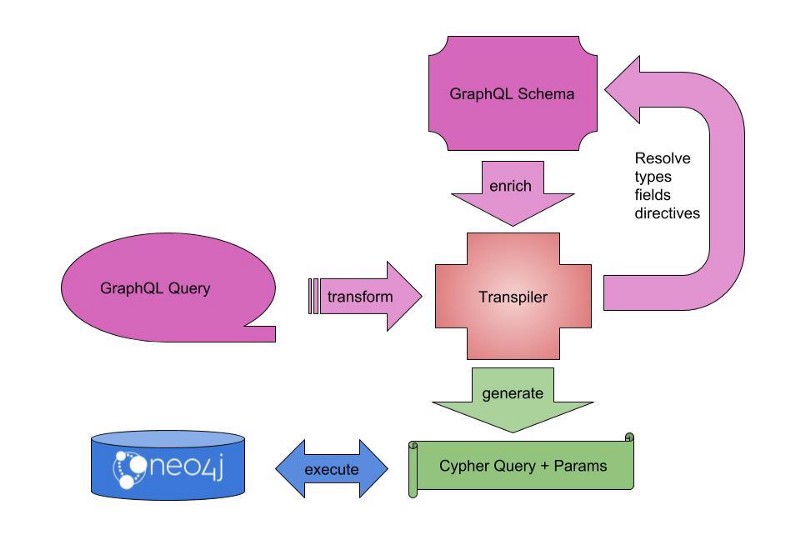
Michael released the first milestone (1.0.0-M01) of neo4j-graphql-java – a GraphQL to Cypher transpiler for the JVM.
If you want to use GraphQL with Neo4j from any JVM based web application or API, this library will give you the same freedom as you’re used to with the neo4j-graphql-js library.
On the podcast: Will Lyon

A couple of weeks ago Rik interviewed Will Lyon, my colleague in the Developer Relations team at Neo4j.
Will describes his introduction to Neo4j at a hackathon that he won by building a collaborative filtering based GitHub project recommendation engine, before going into detail about his work on the GRANDstack. He also talks about his experience working on the Russian Twitter Trolls dataset earlier this year.
Next Week
What’s happening next week in the world of graph databases?
| Date | Title | Group |
|---|---|---|
|
December 17th 2018 |
Tweet of the Week
My favourite tweet this week was by Gerrit Meier:
One of our functionality in the fresh @SpringData @Neo4j Moore M1: Native #Neo4j types. pic.twitter.com/UPMu6IrKlh
— Gerrit Meier (@meistermeier) December 11, 2018
Don’t forget to RT if you liked it too.
That’s all for this week. Have a great weekend!
Cheers, Mark
Share Article



Explore
Related Articles

This Week in Neo4j: Certification, Developer Tools, GraphRAG, Knowledge Graphs and more

This Week in Neo4j: Certification, Graph Analytics, Agentic AI, Knowledge Graph and more



