
This Week in Neo4j – Health Care & Life Sciences Workshop, Cloudflare Workers, Apache Hop, and More

Developer Experience Engineer at Neo4j
5 min read

Hello, everyone!
It’s that time again to explore the latest news in this week’s edition of This Week in Neo4j.
This week, we feature the Neo4j Health Care & Life Sciences Workshop 2021, a two-day workshop with in-depth technical presentations from the healthcare and life sciences space. Will Lyon demonstrates how to build location-aware personalized news recommendations, Michael Hunger explores attrition data, and much more…
Adam Cowley
Featured Community Member: Ali Emre Varol
This week’s featured community member is Emre Varol.
Emre is a Data Scientist based in Istanbul, Turkey. He works for John Snow labs, a company that focuses on AI and NLP solutions for healthcare companies.
Ali Emre Varol – This Week’s Featured Community Member
Emre presented at the Neo4j Healthcare & Life Sciences Workshop last week, walking through how he created a Clinical Knowledge Graph using Spark NLP and Neo4j.
The presentation starts by introducing Spark NLP and demonstrates how it can be used within the Healthcare space. Emre then provided a life demo and walked through Named Entity Recognition (NER) to extract information from text, before importing it into a Neo4j Sandbox instance.
You can watch Emre’s presentation in the link below, or read more on the John Snow Labs blog.
The accompanying notebooks for this talk can be found on Github.
Videos for Neo4j Health Care & Life Sciences Workshop 2021

18 new videos recorded at the Neo4j Healthcare & Life Sciences Workshop last week are now available on the Neo4j website.
The third Health Care & Life Sciences Workshop was setup to showcase practical solutions to common problems as helping to incubate collaboration, innovation and good practice.
Eighteen videos are now available from the two-day event, including presentations that center around knowledge graphs, graph algorithms, and general Neo4j usage.
Included in the videos are Jeremy Grignard’s presentation of Pegasus (a knowledge graph to support early drug discovery), Frederico Braga’s presentation on Building Complex Web Applications for Healthcare, and Emre’s presentation on Building a Knowledge Graph with Neo4j and Spark NLP.
Improving News Recommendations with Cloudflare Workers & Knowledge Graphs

As part of Cloudflare’s Full Stack Week Developer Speaker Series, Will Lyon gave a talk on how to improve news recommendations using Knowledge Graphs and Cloudflare Workers.
Will’s 30-minute talk focuses on an article-based Knowledge Graph using data from the NY Times API, including news articles, associated metadata, and comments.
He then uses Cloudflare Workers to serve a real-time recommendation engine which takes into account the user’s location and interests.
Cloudflare Workers is a serverless application platform that runs on Cloudflare’s global cloud network.
They aim is to solve many of the common problems with existing serverless technologies, including performance issues and the cold-start problem.
Cloudflare Workers are also location-aware, making them ideal for location-based personalization.
Graph: A Possible Solution for Environmental Pollution!

Over on the the Neo4j Developer Blog, Shaani Arya Srivastava published an interesting article on how graphs may be a solution for the effects of climate change on our planet.
Shaani’s article looks at identifying industries and cities that are responsible for pollution by linking them with their respective area’s air/water quality measures and disease case.
With COP26 ending last week, this is a topic that I’m sure is on the mind of many people at the moment.
You can view the code and data on Github.
Exploring a Kaggle HR Attrition Dataset

Also from the the Neo4j Developer Blog, Michael Hunger wrote an article to accompany Week 13 of the Discover AuraDB Free weekly stream on the Neo4j Twitch channel.
In the post, Michael explores the IBM Attrition Dataset, which consists of employee information, along with their job satisfaction rating and a set of attributes that contribute towards that rating.
Michael starts off by importing the data using LOAD CSV, creating a Graph of employees, jobs, departments, and education data.
The article concludes with suggestions for how you could use Neo4j and the Graph Data Science library to predict attrition rates.
You can watch the livestream on YouTube, or catch the next stream live, Mondays on the Neo4j Twitch Channel.
5 Minutes to Write to Neo4j with Apache Hop
Over at Know-BI, an article has been published on how to import data into Neo4j using Apache Hop.
Apache Hop is a data engineering and data orchestration platform that allows data engineers and data developers to visually design workflows and pipelines to build powerful solutions.
It offers a comprehensive feature set for getting data into – and extracting data out of – Neo4j.
The article demonstrates how Apache Hop’s User Interface can be used to configure a Neo4j connection, create pipelines for transforming CSV data, and output the data to Neo4j.
All of this can be achieved without writing a line of code!
Read the Article
New Export Feature in Graphlytic UI

Our friends at Graphlytic recorded a new video tutorial that demonstrates how to export data from the Graphlytic UI.
Visualizations in Graphlytic can be exported as images or CSV.
Quantifying Reputation and Success in Art
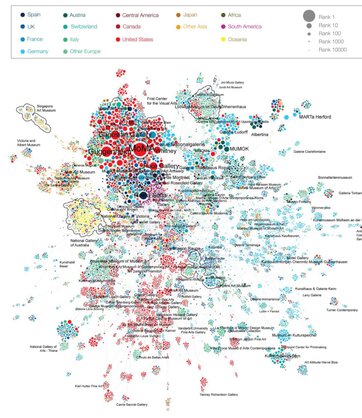
This week’s research paper comes from page 825 of Science Vol. 362, where Samuel P Faiberger et al. examine 500k artists and determines that their long-term success can be attributed to the fact that they’re connected.
The study uses an extensive record of exhibition and auction data to study the career trajectory of individual artists relative to a network of galleries and museums.
Spoiler alert: Turns out it’s hard to break into the world of art if you do not start off with the right connections.
Tweet of the Week
There’s been some great content on #neo4j hashtag this week. @padonouDD has been taking his first steps with Cypher and @mikesir87 has been experimenting with Docker container image data.
But my favorite Tweet this week has to be Savvas Stephanides‘s awesome thread introducing the high level concepts around Graph Databases.
What is a graph database? Let’s explain. pic.twitter.com/GXNMZp9usL
— Savvas Stephanides (@SavvasStephnds) November 8, 2021
Don’t forget to RT if you liked it too!
Share Article



Explore
Related Articles

This Week in Neo4j: GraphRAG, GraphAcademy, Knowledge Graphs, Symfony and more

This Week in Neo4j: Certification, Developer Tools, GraphRAG, Knowledge Graphs and more

This Week in Neo4j: Certification, Graph Analytics, Agentic AI, Knowledge Graph and more


