
This Week in Neo4j – Hierarchical Layouts in Bloom 1.4, Graph Data Science with LynxKite, FullStack GraphQL Book Club

Developer Relations Engineer
3 min read

Hi everyone,
This week Will Lyon started the FullStack GraphQL book club. If you’ve been waiting for the right time to get started with the GRANDstack, maybe that time is now, along with the rest of the community.
Amy Holder launched the new version of Neo4j Bloom, David Allen teaches us all about node labels, and Vlasta Kůs shows how to build a knowledge graph with GraphAware Hume.
And finally, Andras Nemeth shows how to build a Graph Data Science pipeline with Neo4j and LynxKite.
Featured Community Member: Véronique Gendner
This week’s featured community member is Véronique Gendner.
Véronique Gendner – This Week’s Featured Community Member
Véronique has been playing with computers since the age of 10 and has a background in Computational Linguistics.
In September 2020, Véronique started a one year mission at the French National Institute of Geographical Information (IGN). She will work on geolocalized data, with ontologies and labeled property graphs.
One of Véronique’s projects is TheBrain, a digital document management tool, that allows for a graph structure organization of documents, URLs, and notes. She recently presented a talk about this project at NODES2020.
In the talk, Véronique showed how to import TheBrain DB into Neo4j, to automatically extract selected lists or tables and take full advantage of the graph structure, to solve different use cases.
Fullstack GraphQL Book Club | Chapter 1: What’s The GRANDstack?
Our video this week is from the first week of Will Lyon’s FullStack GraphQL Book Club.
In this installment, Will goes through the first chapter of the book, which gives a high-level overview of the GRANDstack. He then shows how to write GraphQL queries to solve the exercises at the end of the chapter.
Graph Visualization Just Got Easier: Introducing Neo4j Bloom 1.4!

Amy Hodler announced the release of version 1.4 of Neo4j Bloom, the graph visualisation tool. This release has two main new features:
- Proactive search suggestions to make it easier to explore new graphs without having to know the underlying graph model.
- Hierarchical graph layout, which is useful for visualising nested and sequential data in a tree or linear format.
Graph Modeling: Labels

We have another installment of David Allen’s advanced graph modeling series of blog posts.
This week we learn all about labels. David explains what they are, how Neo4j treats them internally, and how you should use them in your models.
Knowledge Graphs with Entity Relations: Is Jane Austen employed by Google?

Vlasta Kůs has written a deep dive into the NLP techniques that we can use to extract meaning from news feeds.
After giving an overview of the techniques, Vlasta takes us through a demo of GraphAware Hume, a graph-powered insights engine that has in-built support for constructing knowledge graphs from text documents.
Supercharged Data Science with LynxKite on Neo4j data
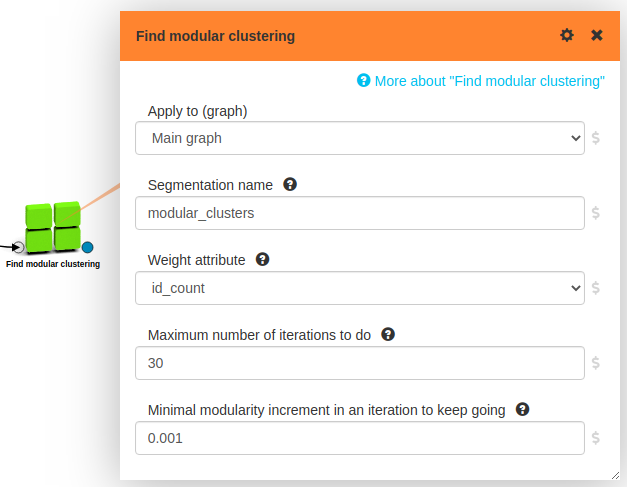
LynxKite is an open-source graph data science platform that simplifies building Machine Learning pipelines and supports multiple data sources. One of these data sources is Neo4j, and Andras Nemeth has written a tutorial showing how the two tools work together.
Andras shows how to transform a graph into the required structure, before running a clustering algorithm over the resulting graph. And finally, the results can be written back into Neo4j for further analysis.
Tweet of the Week
My favourite tweet this week was by Adam Cowley:
Hot off the press… I’ve added a useSchema hook to the #react use-neo4j library. This calls the apoc.meta.schema procedure and returns an array of labels and relationship types. pic.twitter.com/jX97cVsaGO
— Adam Cowley (@adamcowley) October 30, 2020
Don’t forget to RT if you liked it too!
Share Article



Explore
Related Articles

This Week in Neo4j: Certification, Developer Tools, GraphRAG, Knowledge Graphs and more

This Week in Neo4j: Certification, Graph Analytics, Agentic AI, Knowledge Graph and more



