This week in Neo4j – Link prediction with Neo4j, graphs for healthcare search, XRP graph, querying Neo4j clusters

Developer Relations Engineer
5 min read

This week was a bumper one for content in the Neo4j community.
We go into the world of blockchain with an online meetup on XRP and a blog post showing how to import bitcoin into Neo4j in less than 24 hours. I started a series of posts on link prediction and wrote a post explaining the modelling decisions we made in the BBC GoodFood Graph.
David Allen does a deep dive into what happens when you query a Neo4j cluster, Dave Fauth shows us how to model a healthcare graph, and more!
Featured community member: Dr. Lena Wiese
This week’s featured community members is Dr. Lena Wiese, Head of research group Knowledge Engineering at Georg August University Göttingen.
Dr. Lena Wiese – This Week’s Featured Community Member
Lena works and teaches on a wide variety of database topics and came across Neo4j a few years ago. She wrote a book on “Advanced Data Management” which also covers graph databases and presented about them at various events.
Lena been using graphs in work with linked-data, ontologies, knowledge graphs and similarity computation. This week she presented a half day hands-on tutorial on “Data Analytics with Graph Algorithms” at the scientific BTW-conference (German Equivalent to VLDB).
She covered graph data management and how and when to use which algorithms for graph data analytics.
On behalf of the Neo4j community, thanks for your work Lena!
Building a graph of the XRP ledger
In this week’s Neo4j Online Meetup, Thomas Silkjær and Sony Green showed us how to build a graph of the XRP ledger.
Thomas started by giving an overview of XRP and why he decided to load the data into Neo4j. Thomas has also written a couple of blog posts about his experiences so far.
In the 2nd part of the talk Sony shows how to analyse the data using GraphXR, a browser-based visualization tool that allows exploration of data in 2D and XR.
In related news, this week GraphXR was made available as a Graph App in the Neo4j Desktop. You can read more about that in the release post.
Link prediction with Neo4j part 1: An introduction

I’ve started a series of posts about link prediction and the algorithms that we recently added to the Neo4j Graph Algorithms library.
In the first post I give an overview of the problem, describe a few link prediction measures, and explain the challenges we have when building a link prediction machine classifier. We’re now setup for a worked example in the next post in the series.
Thanks also go to Michael Hunger and Amy Hodler for their extensive review of this post.
Leveraging a graph for healthcare search

Dave Fauth has started a series of posts showing how to leverage graphs for healthcare search. In the first post Dave lists several datasets from the US Government’s Centers for Medicare and Medicaid Services that will be loaded into Neo4j, and describes the graph model that we’ll be using.
PageRank meets full text search, querying Neo4j clusters, Bitcoin graph within a day
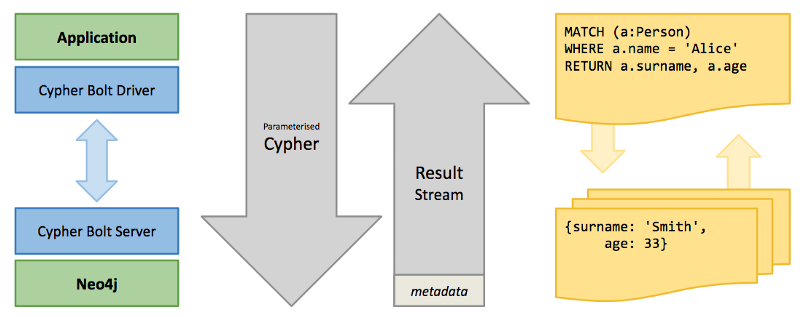
Have you ever wondered what happens when you query a Neo4j cluster using one of the official drivers? If so David Allen has got you covered in his latest post. David explains cluster roles, routing tables, connection management, the importance of the advertised address, and more.
I wrote a blog post showing how to make article recommendations by combining Neo4j 3.5’s Full Text Search with the Personalized PageRank graph algorithm.
Cesar Pantoja wrote a blog post in which he explains an innovative approach to get all the data from the bitcoin ledger into Neo4j within 24 hours. Cesar will be presenting on this topic at the Neo4j Online Meetup on 4th April 2019.
Codex’s extension to the Neo4j Driver has been been enhanced to now to take an optional path pattern, which lets you specify node variable names with the strongly-typed Match statement.
What’s cooking? Part 3: A segue into graph modelling

In the 3rd part of the What’s cooking? series, we take a brief detour into the world of graph modelling to go into more detail on the modelling questions we received during the online meetup a couple of weeks ago.
I explain why we chose to model certain things as nodes rather than properties, and also identify a part of the model where the opposite approach would make sense.
Tweet of the week
My favourite tweet this week was by Bernie Michalik:
In the last 36 hours I’ve learned and built a chatbot with DialogFlow and built a graph database with neo4J. My brain is glowing hot 🙂
— Bernie Michalik (@blm849) March 7, 2019
Don’t forget to RT if you liked it too.
That’s all for this week. Have a great weekend!
Cheers, Mark
Share Article



Explore
Related Articles

This Week in Neo4j: Knowledge Graph, Life Sciences, GraphRAG, NODES, Startups and more

This Week in Neo4j: GraphAware, Architecture, Knowledge Graph, AI Agents and more



