


This Week in Neo4j – More on GraphQL v2, A Focus on Graph Embeddings, and Recommendation Engines with Kafka

Data Science Advocate
4 min read

Hello, everyone!
For this week of Twin4j, we wanted to highlight a few different things. First, we get the chance to take an in-depth look at the newly-released GraphQL library 2.0.0. Next, we are dedicating most of this issue to the fascinating topic of graph embeddings, commonly used in data science and machine learning problems. There are three different graph embedding methods included in the Neo4j Graph Data Science library – FastRP, Node2Vec, and GraphSAGE – and we have articles this week showing the inner workings of all three.
We also have a few items on creating recommendation engines, including the recent work of our featured community member, Sebastian Daschner. And then we conclude with the popular podcast topic: “Will it Graph?”
Enjoy!
Featured Community Member: Sebastian Daschner
This week’s featured community member is Sebastian Daschner.
Sebastian Daschner – This Week’s Featured Community Member
Sebastian is a regular contributor of great content within the Neo4j community. For example, in one of his most recent posts he wrote about how to build a recommendation engine for coffee using Neo4j and Quarkus in Java, with a great demonstration using Neo4j AuraDB or locally via a Docker container. He also has provided some great examples in the past of using Kubernetes with Neo4j. His goal is to educate and spread knowledge on enterprise software development, Java, and IT in general through workshops and consulting.
In-Depth Guide to Neo4j GraphQL Library 2.0.0

In last week’s edition of Twin4j we highlighted the newly-released v2 of the Neo4j GraphQL library. This week, Dan Starns takes us on an in-depth tour of the new version, which includes new features such as relationship properties, count queries, and relay support. The main aim of this release was to support relationship properties, and he walks through an example using the classic Movies database showing how relationship properties could be hacked in v1, versus how efficient it is to do now with full support in v2.
Complete Guide to Understanding the Node2Vec Algorithm
Have you ever wondered how the popular Node2Vec algorithm used for generating graph embeddings works? Node2Vec is included in the Graph Data Science library, but have you wanted to understand more about what it’s doing under the hood? Tomaz Bratanic has written up a detailed guide into the origins and workings of this popular algorithm. It helps provide an understanding on how you can then tune your hyperparameters to get the best embedding for your application.
Behind the Scenes on the FastRP Algorithm for Generating Graph Embeddings

Have you ever wondered what makes the Fast Random Projections (FastRP) algorithm, built into the Graph Data Science library, tick? FastRP is obviously fast, as the name would imply, but it also generates very accurate node embeddings. Clair Sullivan has written a blog post that quickly summarizes the math behind the algorithm so you don’t have to read the research papers to learn how the hyperparameters work.
Graph Embeddings in Neo4j with GraphSAGE

Sefik Ilkin Serengil has written a tutorial on how to create GraphSAGE embeddings with Neo4j. GraphSAGE is the final of three embedding creation algorithms available within the Graph Data Science library, and the most sophisticated. Unlike Node2Vec and FastRP, GraphSAGE is an inductive algorithm, meaning that it doesn’t need to retrain on the entire graph each time a new node is added. Another added benefit is that it can be trained with multiple node labels.
Real-Time Recommendations with Kafka and Neo4j
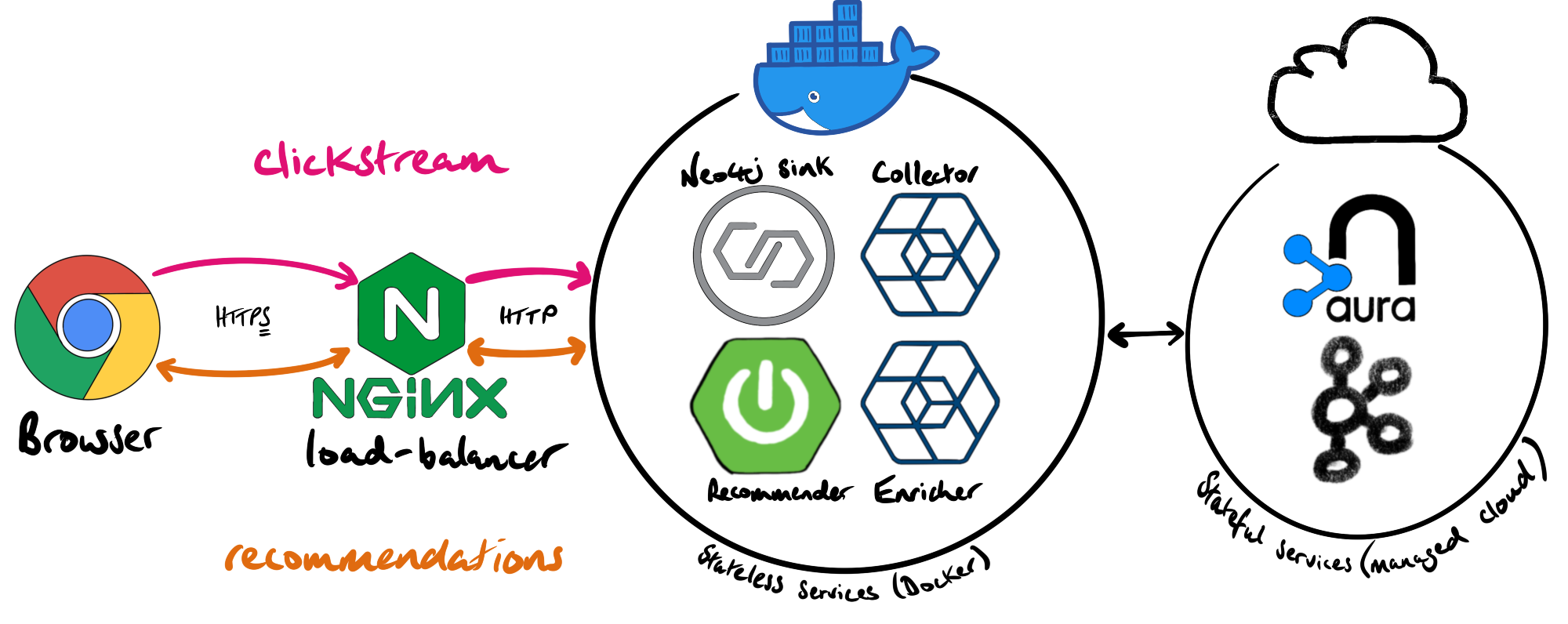
Building off of his previous posts, Alex Woolford tackles how to build a real-time recommendation engine using clickstream events captured from Kafka and imported to Neo4j. To do so, he shows us how to Dockerize a Kafka Connect instance that included the Neo4j connector and use it to create a Neo4j sink. This is all done using Confluent Cloud and Neo4j AuraDB.
Will it Graph? (Part 3)

In this next part of the GraphStuff.FM podcast, Lju Lazarevic and William Lyon discuss the potential of using a graph database as a general-purpose database within a larger database ecosystem. One big question they address is why would you want to do that? The easy answer is that graph databases are really fast when it comes to prototyping since they don’t require you to declare a schema. Additionally, graph models more closely represent how people intuitively think of data. Lju and Will talk through some examples of where thinking about your data as a graph can do things like speed up API development.
Tweet of the Week
My favorite tweet this week was by TheTechromancer:
I wrote a #Python tool to import and analyze @spiderfoot OSINT data in a @neo4j graph database. Multiple scans supported in a single graph!https://t.co/XIjeiyrSMC pic.twitter.com/czrfzdSgfo
— TheTechromancer (@thetechr0mancer) August 12, 2021
Don’t forget to RT if you liked it too!
Share Article



Explore
Related Articles

This Week in Neo4j: AI in Production, Memory, GraphRAG, Architecture and more

This Week in Neo4j: Aura Agents, Persistence, Graph Algorithms, GraphRAG and more

This Week in Neo4j: NODES AI, Context, Text2Cypher, Fraud Detection and more


This Week in Neo4j: Entity Extraction, MS Agent Framework, Context Engineering and more
